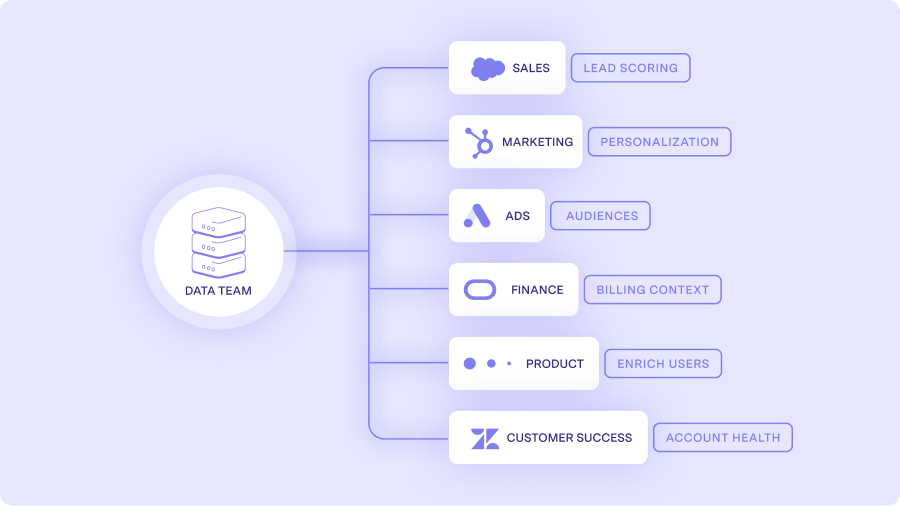
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
With our Reverse ETL integration to Kafka, you can:
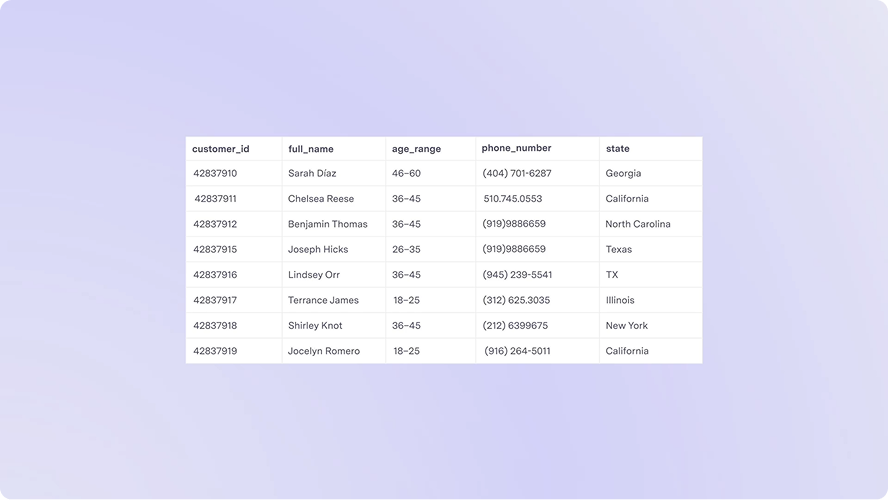
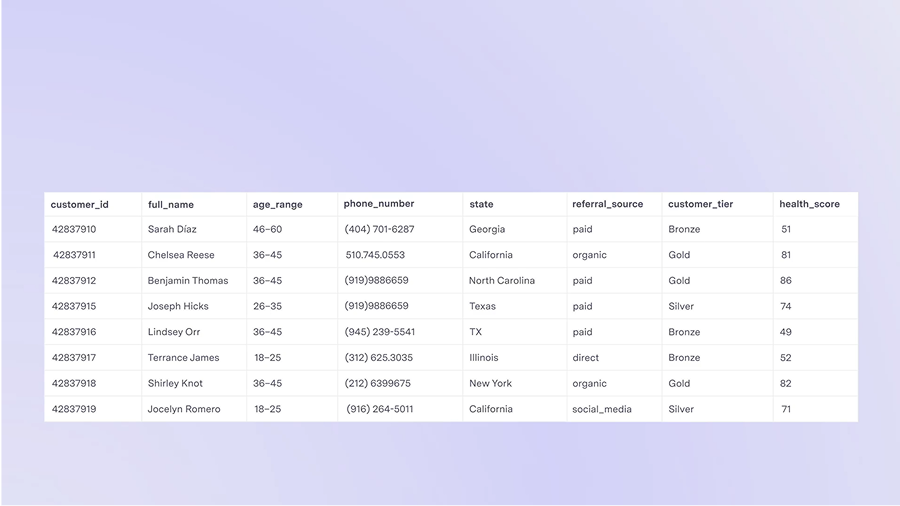
- Publish messages to topics whenever rows are added, changed, or removed in your source data models.
- Compose messages using SQL or our Liquid-based templating engine, directly within our sync mapping UI.