































Throughout 2022, I shared 125 resources in the OA Digest Newsletter. 🤯 These resources came in various forms (blogs, videos, podcasts, events, etc.), but they came together to serve a single purpose: Help data professionals gain practical knowledge to level up their careers. 📈
To wrap up the year, (Please! Not another Spotify pun!) I wanted to highlight the 10 most popular resources from all of my newsletters.

|
So, without further ado, thanks for being an OA Digest reader, and enjoy the top 10 (in no particular order). 👇
Blogs and Technical Tutorials
SQL Cheat Sheet for Data Scienceby Srikanth Kb (data scientist @ Tesla)
Whether you’re a SQL veteran or a beginner, it’s always nice to have a SQL cheat sheet on hand. This blog is your ticket to remembering all the basic SQL syntax and semantics. Hopefully, it saves you a few google searches!
The best SQL template for Customer Lifetime Value by Josh Berry (data scientist @ Rasgo)
You know what constantly reminds me that the world isn’t all that bad? People sharing high-value, applicable knowledge for free. Josh Berry does just that in his recent blog, The best SQL template for Customer Lifetime Value.
Josh has been building CLV models for over a decade. Not only does he share the templated SQL and jinja code, but he carefully explains the logic behind it all. Give this a read If you’re looking to up your SQL knowledge or gain a better understanding of CLV modeling.
SQL Hack: How to get first value based on time without a JOIN or a Window Function? by Ahmed Elsamadisi (CEO @ Narrator AI)
There’s nothing worse than having to write long, complex queries to answer simple questions. Sure, sometimes it’s unavoidable, but other times you simply need to leverage some handy-dandy, pre-built SQL functions.
In this article, Ahmed shows you how to substitute subqueries and self-joins with simple SQL functions like CONCAT.

|
Using SQL to Summarize A/B Experiment Results by Adam Stone (sr. analytics engineer @ Netlify)
Even if your responsibilities fall outside the realm of A/B testing, I highly recommend giving Adam’s blog a read. You can learn from his disciplined planning and execution process, as well as his high-quality SQL queries, then apply them to a wide variety of SQL projects. In this blog, Adam shares:
🪄 A practical example of A/B testing
🪄 Quality SQL queries for joining, de-duping, and safeguarding user-level tables
🪄 How to accurately calculate summary metrics accurately (hint: double-check your denominators 😉)
|
Thinking of Analytics Tools as Products by Emily Thompson (lead - core product data science @ Gusto)
Emily is a two-pronged professional, dabbling in both data and product. In this blog, she shares her best practices for developing self-service data tools for stakeholders (including two best practices I, personally, hadn't previously considered):
- Create an internal marketing plan. This will help your stakeholders a) know that the tool exists and b) know how to use it.
- Plan for customer support. Set up a process in order for stakeholders to easily contact you, so your team will solve their issues in a timely manner.
5 SQL Functions Every Analytics Engineer Needs to Know by Madison Schott (analytics engineer @ Winc)
You can always count on at least one SQL tutorial in every OA Digest newsletter. You know those 50+ line SQL queries you used to write? But then, one day, "poof" 🪄 you learn about a function that solves it in 4? In this blog, Madison shares the common SQL functions she uses to solve complex problems.
Bonus: SQL code is included in each example so you can not only learn, but also apply them yourself in a snap. 👌
Videos and On-Demand Workshops
SQL Patterns Every Analyst Should Know w/ Ergest Xheblati (data architect & author)
This is the first installment of Ergest’s workshop series. In it, Ergest gets hands-on with SQL and shares key principles to help you take your SQL skill from intermediate to advanced. More specifically, he teaches:
🎯 Query composition patterns - How to make your complex queries shorter, more legible, and more performant
🎯 Query maintainability patterns - Constructing CTEs that can be reused. In software engineering, it's called the DRY principle (don't repeat yourself)
🎯 Query robustness patterns - Constructing queries that don't break when the underlying data changes in unpredictable ways
🎯 Query performance patterns - Make your queries faster (and cheaper) regardless of the specific database you’re using.
One of my many takeaways from the event... CTEs > Subqueries👇

|
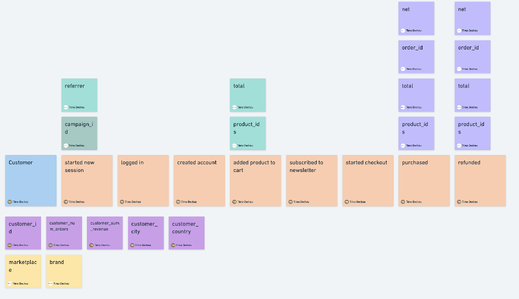
How to design a good tracking plan by Timo Dechau (founder & data designer @ Deepskydata)
If you work with event data (tracking, attribution, etc.), you’ve seen how disorganized, inaccurate, and useless it can be in the absence of a well-executed plan. Timo’s been building tracking plans for 10+ years, and he recently released this free 1-hour course on how to develop, manage, and implement a good tracking plan.

|
Bonus: Timo is somewhat of a flowchart expert. It’s fascinating. He visualizes the information as fast as he speaks it. 😂
|
SQL Puzzle Optimization: The UDTF Approach For A Decay Function by Felipe Hoffa (data cloud advocate @ Snowflake)
Felipe documents his response to a SQL challenge on Elon Musk’s private social platform: SQL Puzzle: Calculating engagement with a decay function. The goal? To write the most efficient decay function in SQL.
It’s particularly tedious because the decay calculation must reference multiple rows from the same table, and an inefficient query might crash your warehouse 💥. Some participants leveraged window functions, others used joins, and Felipe chose Tabular JavaScript UDFs.
If you come across a similar problem, Tabular JavaScript UDFs might be your best option!

|
Data modeling workshop: How to design a lasting business blueprint w/ Ergest Xheblati (data architect & author)
Yes, another Ergest workshop! And if your data profession has anything to do with data modeling – or if you simply want a high-level overview from an industry expert like Ergest – I strongly recommend giving it a watch.
You’ll learn:
🎯 Data modeling 101: What is it? Why's it so important?
🎯 Top-down vs bottom-up data modeling: Which one is best for the current state of your business?
🎯 Modeling types: Conceptual models, logical models, physical models... What's the difference?
🎯 Overview + pros & cons of popular physical data modeling types (One Big Table, Kimball Dimensional Modeling AKA Star Schema, Relational Modeling, Activity Stream, etc.)
2022 was a great year for data practitioners. And as the industry continues to boom in 2023, we're sure to see even more great content from data folks!
Want to be the first to see resources like this in the new year? 🎆 Join The Operational Analytics Club!