































A new ETL tool has recently seen remarkable adoption among tech companies, both large and small, thanks to its versatility and powerful data engineering features. dbt allows users to set up complex production-grade data pipelines using SELECT statements. The software will take care of the admin set-up (e.g., permission grants and table clean-ups), clearing up time for the data engineers that usually perform these tasks.
In this post, I will present a real-world application for dbt—the primary analytics tool in my company, N26—including the path to its adoption, its benefits, and the lessons learned from our implementation.
A data backstory
At N26, I'm part of the Data Analytics (DA) team. Although this group belongs to the larger Data organization (including Data Science and Data Engineering), the data infrastructure topics we wrangle are pretty different.
|
As the business grew and the organization evolved, so did the data challenges we faced—and the data team's structure mirrored that. Before I joined the company in 2018, we had only 1 FTE data analyst. We then had a hiring surge to bring in new analysts to support the expanding marketing, operations, and product departments. Then, in 2019, N26 launched the US branch of their business, so we spun up a new local data warehouse, and, more importantly, we incorporated dbt in our data services architecture.
Fast-forward three years... We today want to add a new analytics engineer to maintain and contribute to our ever-growing data projects. Undoubtedly, this is a testament to the impact that dbt has had on our team’s work: It’s boosted our productivity and augmented our scope.
Before dbt, most of the data pipelines at N26 were created and managed by the Data Warehouse Engineering (DWH) team, which sits within Data Engineering. Almost all the pipelines were ingesting data stored in backend services, data from third-party external sources (Salesforce), or data produced by our website/app tracking. The only way data analysts could set up data pipelines or create data models independently was to use automation and a light ETL microservice we built in-house.

|
Over time, the service’s scope expanded, but, at its core, it queried vendors’ APIs (e.g., Google Ads) to either push or pull data to and from the DWH. Some more sophisticated data models, like the customer attribution model, were developed and run there, but adding new data models to the service was cumbersome. To add new models, we needed data analysts that could code ETL pipelines confidently in a mixture of Python and SQL on a service with few standardizations. We realized that our set-up had several bottlenecks in tooling and data governance, so we decided to try something new. Enter dbt.
A reform movement
dbt core is an open-source tool capable of creating complex data pipelines leveraging the SQL SELECT statement. dbt labs’ claims that “anyone who knows SQL can build production-grade data pipelines” —and we can validate that claim. Data analysts, who only know SQL for data retrieval operations (like SELECT statements), can create robust data transformation pipelines with dbt. Effectively, you no longer need to know “admin” SQL to create and manage data models.
The core tool has rich features: It's data warehouse agnostic, offers automated documentation and a front-end to access it, has built-in CI/CD integration, and allows easy testing and dependency management. We use the open-source version, so we host the project on our infrastructure, but there is also a popular, paid product, dbt cloud, which offers a browser-based IDE and is hosted by dbt labs.
The introduction of dbt has revolutionized how the data analytics team works at N26. It allowed us to easily add business logic to raw data sources without taking precious time from the DWH team. Now, we can fully own the design, creation, implementation, and maintenance of the core data models that power any modern digital business. Some advanced data models already existed, but having dbt drastically improved the quantity and quality of the pipelines we could create as a team.
|
There was some prep work for implementing dbt in our architecture. We had to create hundreds of markdown files to document all the existing tables in the DWH since that's the only way to properly use the ref and source functions which are the backbone of dbt’s visual lineage graphs for dependencies. Since both functions leverage jinja templating, we all had to learn exactly how that worked. On the plus side, though, we now have documentation connected to what’s in the DWH, so it's worlds better than the static Confluence pages set-up we previously had.
Next, we converted the analytics models we had at the time to dbt logic. Sometimes this meant struggling with handling recursive model alternation and data type definitions at the column level since dbt infers the data type from whatever source table you use.
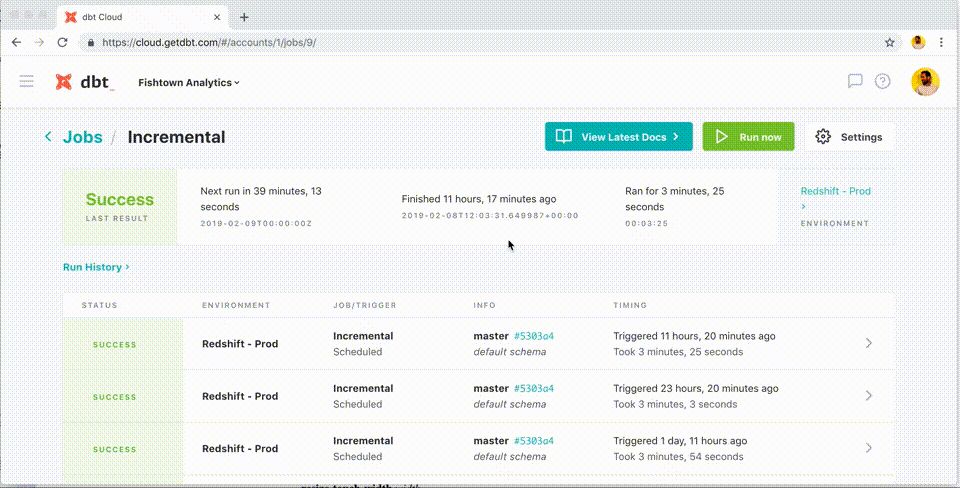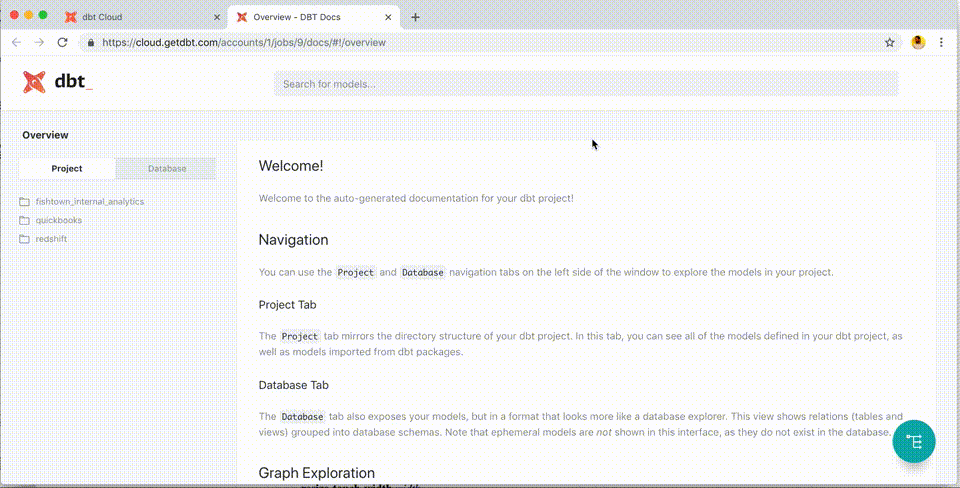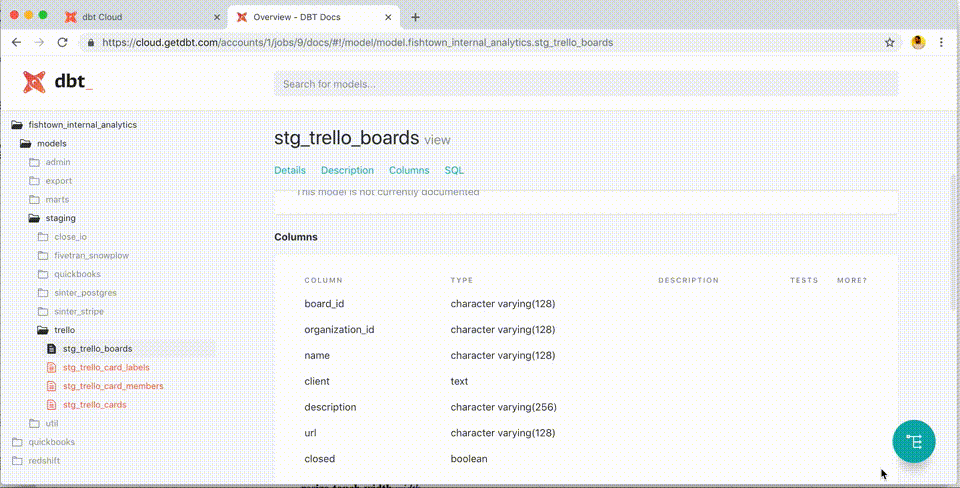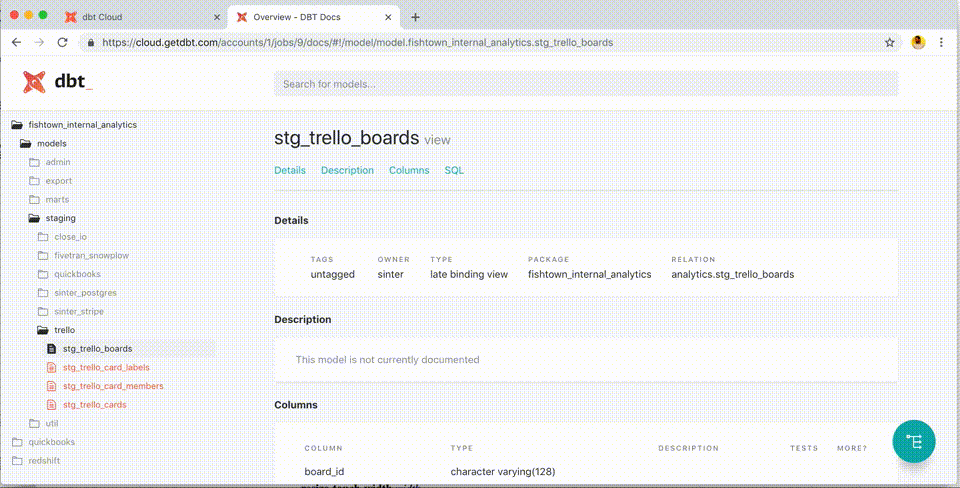
Then we introduced a system to trigger on-demand job execution through our automation tool, Jenkins, and its “build with parameters” page. It's useful for manually re-triggering a pipeline if the previous build didn’t succeed or for fine-tuning model runs and picking what to update.
Luckily, dbt comes with powerful step-by-step logging, which we integrated into our Elasticsearch/Kibana stack using Python’s standard logging module and our custom library.
A look at N26 today
Three years into dbt’s adoption, our data projects have become quite large and complex: We run six dbt projects, with well over 800 data models running daily or weekly. Models are grouped using tags based on the team they were created for, with several core models as foundations for the project. At N26, dbt is a containerized application on a Kubernetes (k8s) cluster, leveraging the built-in scheduler as an automation server, while Jenkins is used for on-demand execution and CI/CD.

|
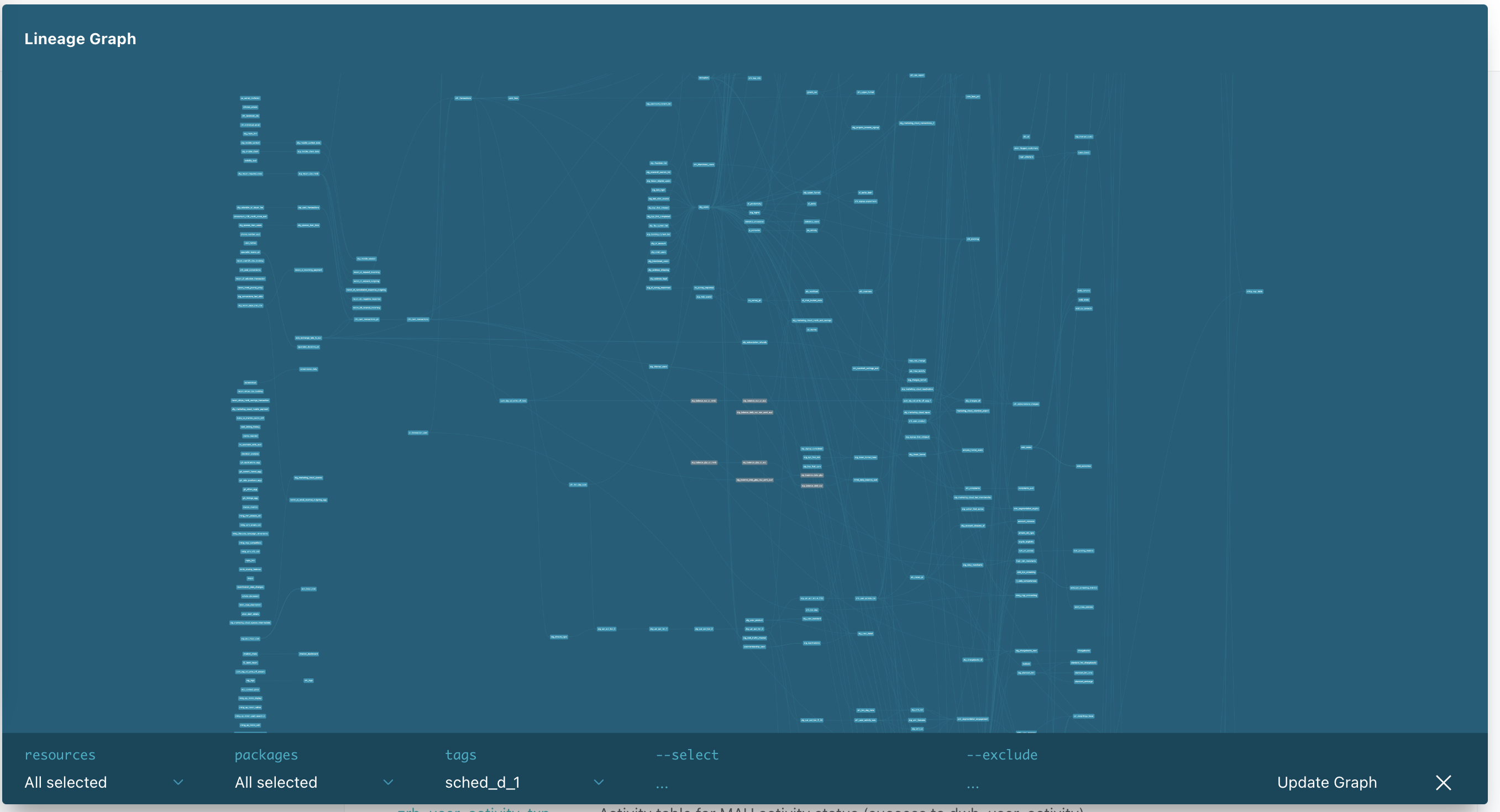
We started simple, with only tables (incremental and not) and seeds (CSV uploads), because we believe that the level of abstraction of your dbt project should increase according to the complexity of the project itself. As N26 became more complex and multi-faceted, so did our dbt project. Today, we run tables, seeds, snapshots, macros, hooks, tests, and sources with automated freshness checks on raw data sources. These are all different object types; however, our 10+ direct acyclic graphs (DAGs) are still relatively simple, grouping objects based on schedule frequency (daily, weekly, etc.)
Not everything went out super smoothly, though. We did not fully anticipate the need for solid data architecture knowledge to stand up an efficient and robust analytics engineering service. Most of the team at that point was only used to creating one-off queries used for ad-hoc analyses, data retrieval, and dashboards and had no experience with data pipelines. This is why we plan to boost data warehousing knowledge in our team by adding analytics engineers to the roster. To support the business during hypergrowth, with priorities changing rapidly, we did not initially enforce strict development guidelines for data models, which has made for a somewhat tight dependency network in our DAGs.
As a result of this interdependency, the daily DAG, the biggest one, is heavy and fragile because of model overload in it. While this only affects internal analytics, as our team’s work is never customer-facing, it does sometimes mean that dashboards will take longer to update in the morning - an annoyance all the same.
|
We run tests on data models through the dbt test functionality and we cover all the core models. While we can monitor dependencies within the dbt projects, thanks to its rich dependency management, the service it runs on is unaware of dependencies outside of it. That light ETL service I mentioned in the beginning? It produces some raw data that's powering many models.
The concept of “status” of any dbt run is not fully fleshed out and can’t be referenced during job execution, and we discovered that k8s is better tuned for high-availability services (i.e. backend) than cronjob-based ones. There have been multiple cases of jobs running twice because the old k8s pod didn’t shut down properly or the pods spontaneously restarted. But even with all the bumps in the road, dbt still changed the way the N26 Data team works for the better.
The road ahead
What’s next? Certainly, dbt is here to stay, but we are changing how we maintain the project and rethinking who will be responsible for developing it. We plan to hire analytics engineers to help us plan and execute the healthy growth of our dbt data projects and ensure sound data warehouse principles. On the other hand, we want to separate core business analytics responsibilities from development and data modeling duties and move the former out to the business departments.
We are also considering adding a workflow orchestrator like Airflow to our infrastructure. With that addition, we hope to address inter-service dependency issues, improve non-happy paths management, and expand the concept of job status. Introducing higher severity tests to guarantee data quality is on the roadmap, too — and we are just about to launch automated SQL format checks to standardize how our code looks!
All in all, going with dbt was a great decision. It has turbocharged the output of our team, both quality and quantity wise and is the right tool to support the expansion of our data platform as N26 expands its business with new products and new geographies.
☀️ Catch Carlo's full talk from Summer Community Days here.
😎 Then, head on over to the Operational Analytics Club to share your thoughts with Carlo and others in the community!