































The data industry and community wouldn’t be what it is today without the brilliant minds and contributions of data practitioners. That’s a pretty well known truth, and something the community team here at Census (and the company overall) aims to support in all our relationships, whether that’s at an event, in a customer call, over Slack, when building for our users, or when networking with you all.
There’s no shortage of product and user conferences out there built by companies to help vendors connect with this community of bright folks. However, there’s an opportunity to better support practitioners as you look to learn from each other (and share your own expertise).
So we’re creating an event just for you: Summer Community Days, a 2-day, practitioner-first event July 28 and 29. We’ll get together to learn from data experts and help you stand out in your data career (and have some fun) for the official Summer of Data.
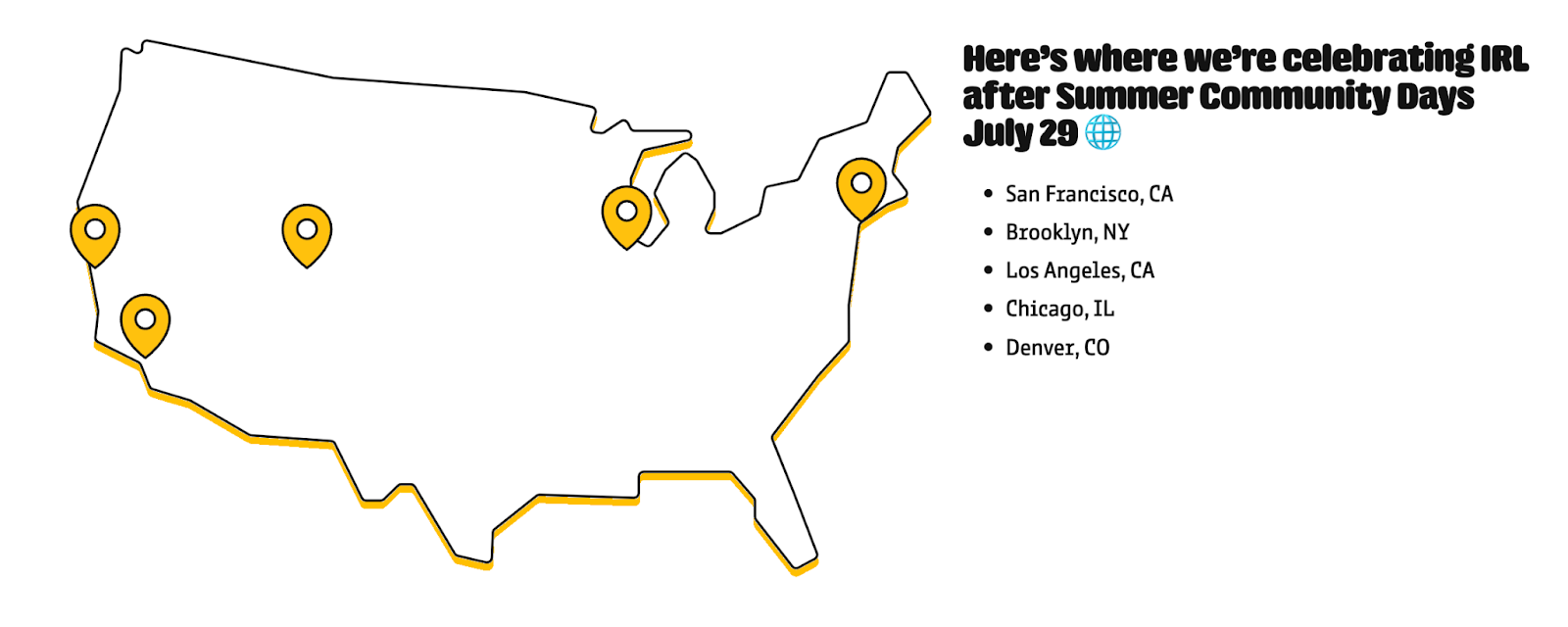
Over the course of two days, we’ll bring virtual programming directly to you, as well as in person happy hours in select US cities to help you connect with your local data scene. You’ll leave the event an OA expert in technical- and business-focused subjects alike (and have some new friends, too). 🍾
Choose your own data adventure at Summer Community Days
The modern data leader is a cross-functional data champion (and you’re all complex human beings with lots of different interests and backgrounds). We’re bringing you a wide range of technical data talk tracks, plus data-driven business sessions, to build up your skills wherever you need support.
As such, our virtual schedule is split into two parts: Technical deep dives and business drivers.
On the technical deep dive talk tracks, here’s a breakdown of the themes you’ll learn about:
- Use case workshops: This track showcases popular and inspiring use cases from our community, plus some well-earned second-hand gold.
- New tools 101: Want to learn more about that fancy new tool all your friends have been talking about? Trying to evaluate a new vendor, but don’t know where to start? This track offers in-depth starter’s guides to some of the best tools in the Modern Data Stack.
- The mental process of modeling considerations: Want to learn more about building effective models for lead scoring, customer 360, and more? This track focuses on modeling considerations and best practices to save you headaches, time, and $$$ as you operationalize your data.
- How your data stack stacks up: Need some inspiration? This track features an all-star lineup of cutting-edge, modern stacks from our community (as well as a breakdown of what went into their architecture, and lessons learned).
For the folks looking to level up their management, business, or strategic skills to stand out to your non-data counterparts, you’ll find sessions on:
- Crafting successful data careers: Everyone’s journey looks a little different, but we can all learn from each other. This track focuses on how folks broke into data, how their career has changed over time, and how they’ve continued to learn and evolve in new roles.
- Building and managing high-impact data teams: Are you a new manager? A seasoned data team leader looking to learn from your peers? A data team of one trying to scale? This track is for, featuring hard-won lessons to help the next generation of data leaders build bigger and faster.
- Taking your seat at the table: Operational Analytics is all about giving data teams the seat they deserve at the organizational table, but the work doesn’t stop there. Stakeholder management, internal data enablement education, and a myriad of complex people-oriented initiatives await data teams beyond day 1. Talks in this track will cover how to champion data throughout your organization and broaden the data team’s sphere of influence.
- Taming the chaos: Need some advice on tackling data governance at your organization? Looking for a bomb proof discovery process for uncovering stakeholder needs? Curious what the perfect balance of DataOps best practices (or some other best practice framework) is? Sessions in this track can answer your questions (or at least point you in the right direction).
No matter what you’re interested in (or where you’re looking to improve), your community members have the resources for you.
Call for proposals: Come share your unique expertise
This conference line up and our session schedule is driven by the best practices, lessons, and second-hand gold of everyone who is in the community.
Got something you want to share with your community? A topic or best practice that you frequently educate about internally? Something you wish someone had presented when you were just starting out? We’d love to have you present at Summer Community Days.
We’re taking submissions for 30-minute presentations on any of the topics above. The deadline for submitting is June 30 at 11:59 pm PT. For full details (including a breakdown of the support you’ll get to develop your talk), check out our submissions page.👈
Ready to grab your seat? Got some questions? You can find more details (and FAQs) at operationalanalytics.club/summer-community-days.
Not (yet) a member of the OA Club? Join today to get access to pre-conference activities, conversation with fellow practitioners, and more.