































When customer data platforms (CDPs) came onto the scene a little over a decade ago, they promised the world. 🌍 The CDP was meant to be the marketer’s source of truth: A means of building a 360° profile of your customer, segmenting your audience, lead scoring, and syncing it back to all your tools. An all-in-one solution to collect, unify, segment, and activate data — sounds great, right?
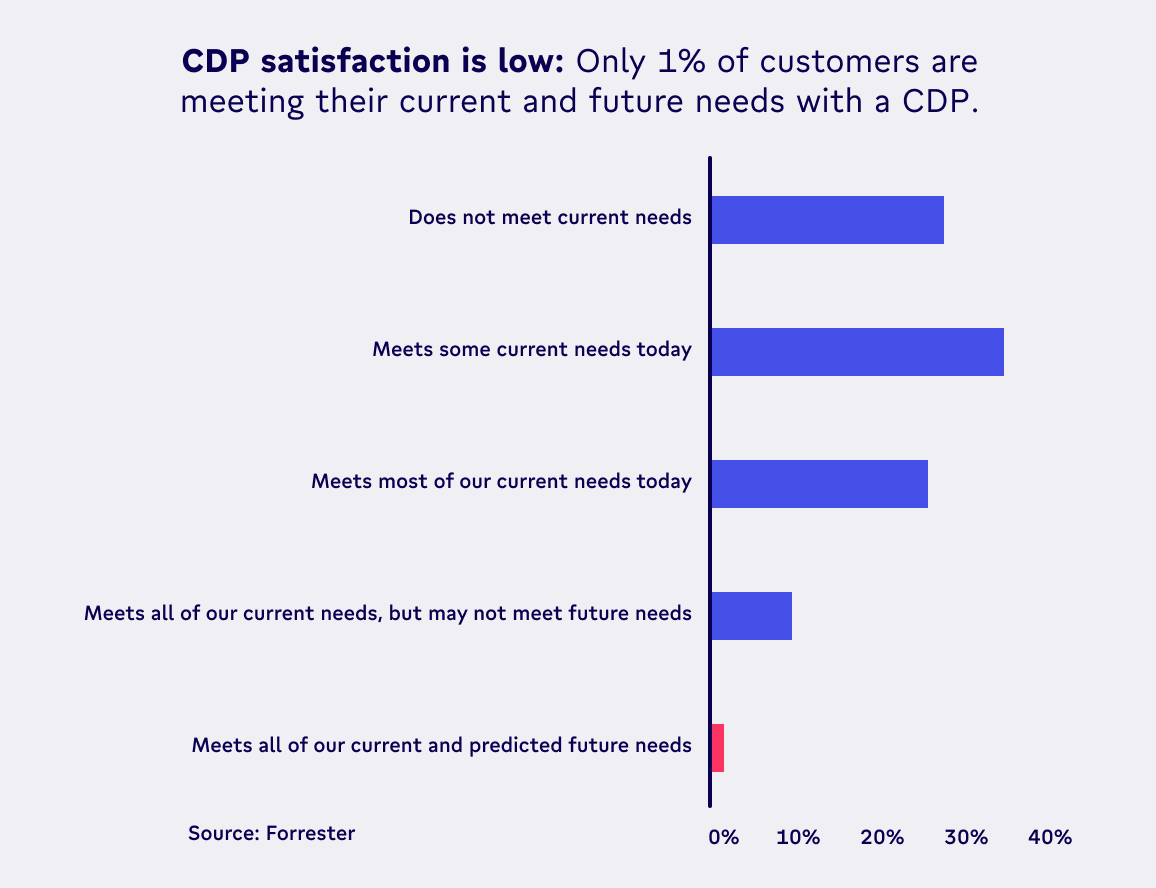
If a customer 360° view from an out-of-the-box CDP sounds too good to be true, it’s because it is. That’s the reason that only 1% of companies report that their CDP is actually meeting their needs. In this blog, we’ll dive into the four key promises CDPs make, where they fall short, and how you can make the most of the data that’s already living in your warehouse.
Promise #1: Data ingestion/collection
As regulations like GDPR and CCPA cut down on the ability to capture third-party data, more and more marketers are relying on the first-party data they’ve collected to inform audience insights. 🔍
If you’re looking to record information like event data and user attributes using APIs, event trackers, and manual imports, a CDP will do the job. But the truth is, if you’re looking to paint an accurate 360° picture of your customer, this information isn’t nearly enough.
Reality:
CDPs do follow through on their promise of data ingestion — mostly. However, most CDPs don’t have any of the customer or company-level data you need to draw conclusions about the buyer journey. They’re taking most of your data, replicating it within their platform, and using it to act as an incomplete source of truth. The result? At best, they’re allowing you to paint an incomplete picture of your customer; at worst, a wholly inaccurate one. 🎨
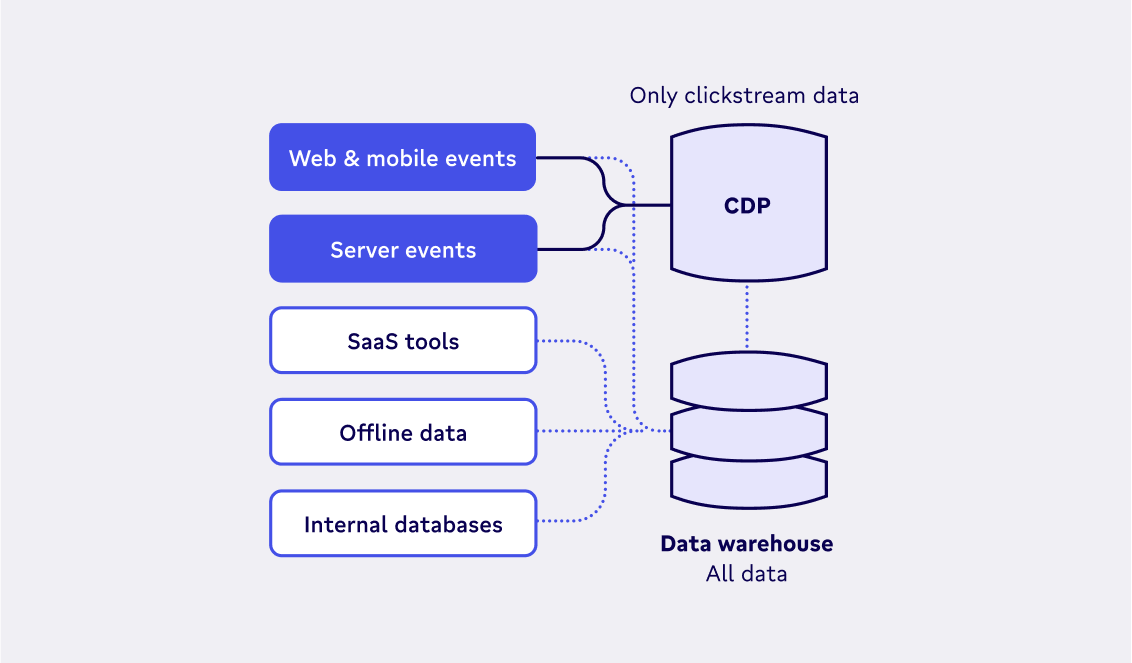
For many marketing teams, the data you need to build a Customer 360 already exists across your tech stack. By bringing a CDP into the mix, you’re adding another layer of data collection that only provides a fragmented view of your customer. For the team at Smartify, this was a key reason why they opted not to purchase a CDP to bolster marketing efforts.

Promise #2: Data transformation
CDPs promise to unify your data into a single, cohesive user profile — a 360° view of the customer if you will. They’re meant to dedupe, structure, and unify customer profiles on the individual level within their platform (you know, the one that you’re spending hundreds of thousands of dollars on). 💸
Identity resolution is essential to identifying and reconciling customer identities across your many different data sources. It’s also one of the core features a CDP promises. The role of identity resolution in building a Customer 360 can’t be understated. It’s integral to resolving data across multiple touchpoints and allowing marketers to run campaigns with confidence in the quality of that data. It’s also impossible for a CDP to provide since it can never truly be your single source of truth.
Reality:
The fact remains that the CDP can’t host all the data you (or your tools) need access to for effective marketing campaigns. 🧰
When you’re trying to run the most personalized campaigns possible, why would you settle for a customer profile with 20 fields when there’s a world where you could have 100 or even 1000? Of the data it can host, the CDP can only provide data modeling for the most basic entities, things like contacts, companies, and events. If you want to do more with data and get information on business objects like workspaces, deals, campaigns, and more, you’re out of luck in a CDP’s hands. This begs the question: What's the point of building audiences on so few fields? At that point, are you really building a personalized experience? What, then, is the point of creating and maintaining all these audiences?
What you will get from your CDP is a hefty price tag on a tool that’s giving you incomplete data to act on. Not only are you paying to store your data twice— once in your warehouse and once in your CDP— you’re also left with reduced confidence in your data quality and limitations in the campaign types and experiments you can run.🙅
Maybe all of this is worth it for the promise of a no-code customer profile-building experience, but it’s important to remember that your CDP can only reconcile the data it’s pulling in. Much of the customer or company-level data specific to your customers is still lost, which means that not only are the destinations that you can push your data to limited but so are the inputs pulling it in. When your CDP can't unify the customer data that’s most important to you, it’s no surprise that 73% of company data is going unused.
Promise #3: Insights/segmentation
So, once you’ve collected a fragment of your data into your CDP and used your expensive platform to reconcile that data, it’s time to build out segments of your audience. CDPs are meant to be self-service tools that allow marketers to deliver a personalized customer experience based on the data pushed into them.
Features like predictive segmentation and predictive LTV aim to showcase the tools’ ML capabilities and help marketers build a customer journey — all before it’s even happened. Sounds pretty cool, but how valuable can predictive insights really be when they’re sitting on top of incomplete data? 🤔
Reality:
Most “self-service” CDPs are never actually self-service. Tools like ActionIQ have self-service features for the marketing team, but since they’re operating on the tiny fragment of customer data that the CDP has collected, your data team is left with the costly (and annoying) task of moving data from the warehouse into the CDP.
Tools like Rudderstack, on the other hand, don’t even have the self-service features that allow marketers to take matters into their own hands. Instead, only the ones who know SQL (👋 to the 0.1% of marketers who can) are enabled to segment and activate data.
Once you decide on a CDP as your solution and commit to a minimum of 3-6 months of implementation, you’re looking at a long time spent deliberating with the buying committee. And you’re looking at even more dev time before you’re actually able to start building any segments in your product. But even then, you’re building half-baked segments on a shaky data foundation and drawing untrustworthy insights that are nowhere near as powerful as the conclusions you could draw by querying your data warehouse.
Promise #4: Data activation
By now, you’re well aware that a CDP’s core use case is pulling your data from various sources to then push back to all your marketing tools. Omnichannel marketing campaigns, personalized emails, and a self-serve system sound great, sure. But what if there was a more powerful, cost-effective way to accomplish all of this?
Reality:
The reality is that while a CDP can help you personalize emails and build out some specialized segments, these few features aren’t worth the time, cost, or effort that the implementation demands. You already have all the data you need to run hyper-targeted marketing campaigns — implementing a CDP won’t do anything besides creating another silo and the risk of unhygienic data practices. 🤢
Your data team has already put so much effort into implementing and maintaining a data warehouse. The solution? Cut out the expensive and inefficient middleman — build your CDP on the warehouse.

CDP? Thank You, Next:
By this point, we’ve established that the CDP hasn’t delivered on its many promises to marketers. Instead, many marketers have decided to take the plunge and rely on a solution that costs less and delivers far more: The data warehouse.
The data warehouse already acts as a source of truth for all the data in your organization — and someone else has already paid for it. By building a Composable CDP, you can use warehouse-native, best-in-class components to create a tool that ingests, unifies, segments, and activates your data — all without the restrictions and drawbacks of an out-of-the-box tool.
Still wondering what all this has to do with marketers? Book a demo with one of our product specialists to see how we can help you sync customer data to all your marketing and advertising tools, without any code.
For further reading, read this blog from Syl Giuliani, Census’s Head of Growth, on why the data warehouse is the future for marketers.