































At Census, we believe your data deserves the same care and attention as production-grade software systems. That’s why we’re excited to announce our Open Beta for Git-backed Models.
Today, we’ve released a bi-directional Git integration that enables data teams to manage Census SQL models with software development best practices. Now, your business-critical models are backed by all of the benefits of Git – peer review, version control, and auditability.
Our vision is that all Census resources should be manageable in code. This is the first step – stay tuned for more improvements on the roadmap. 🚀
Bringing the benefits of Git to your Reverse ETL workflows
In software development, version control is critical to managing changes and ensuring quality. Git helps developers build collaboratively, track changes, and ensure high quality code.
In the past 4 years, dbt has cemented Git-based processes as an essential part of data and analytics engineering. Data teams now manage the majority of their data work in code – whether in dbt, Terraform, or Python.
Data Activation should be no different.
When business logic lives outside of code, it can be difficult to audit and govern changes that impact live systems. Even with the most powerful RBAC, changes can be made without review and easy-to-catch mistakes can end up impacting your business processes.
That’s why we built Git-backed Models – to enable you to govern your activation flows as seamlessly as the rest of your data stack. This feature brings all the benefits of Git to your Reverse ETL workflows:
- Commit logs for auditability and rollbacks
- Approval and review flows for proposed changes
- Ability to create automated CI testing checks
At a glance, what do Git-backed Models do?
Git-backed Models enable you to make changes to Census SQL models using configuration YAML files, leveraging best practices of production software development.
In summary, Git-backed Models offer:
- Resources as Code: Specify your Census SQL models in YAML configuration files.
- Bi-directional updates: UI or Code – it’s up to you! You and your team members will still have the freedom to make changes in the Census UI (according to your level of access control), or make changes by updating the YAML configuration files in your git repository.
- Git-Backed Change History: You can already view and rollback changes to Census SQL models directly within the Census UI. Now – view them as they relate directly to git commits, either initiated in code or directly in the Census UI.
When you create or edit SQL Models in the Census UI (and soon: entities and syncs), they will be backed up into a git repository as YAML configuration files. All changes will be represented as commits to those files.
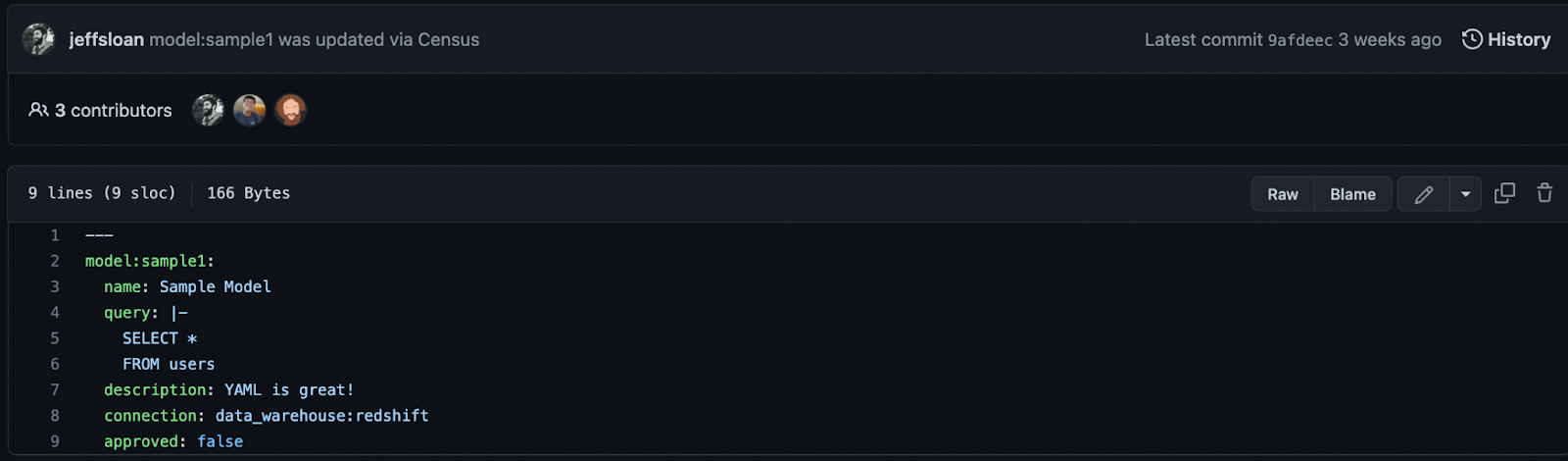
When you create and edit the configuration files via commits and pull requests in a git repository, Census will materialize your changes into your Census workspace.
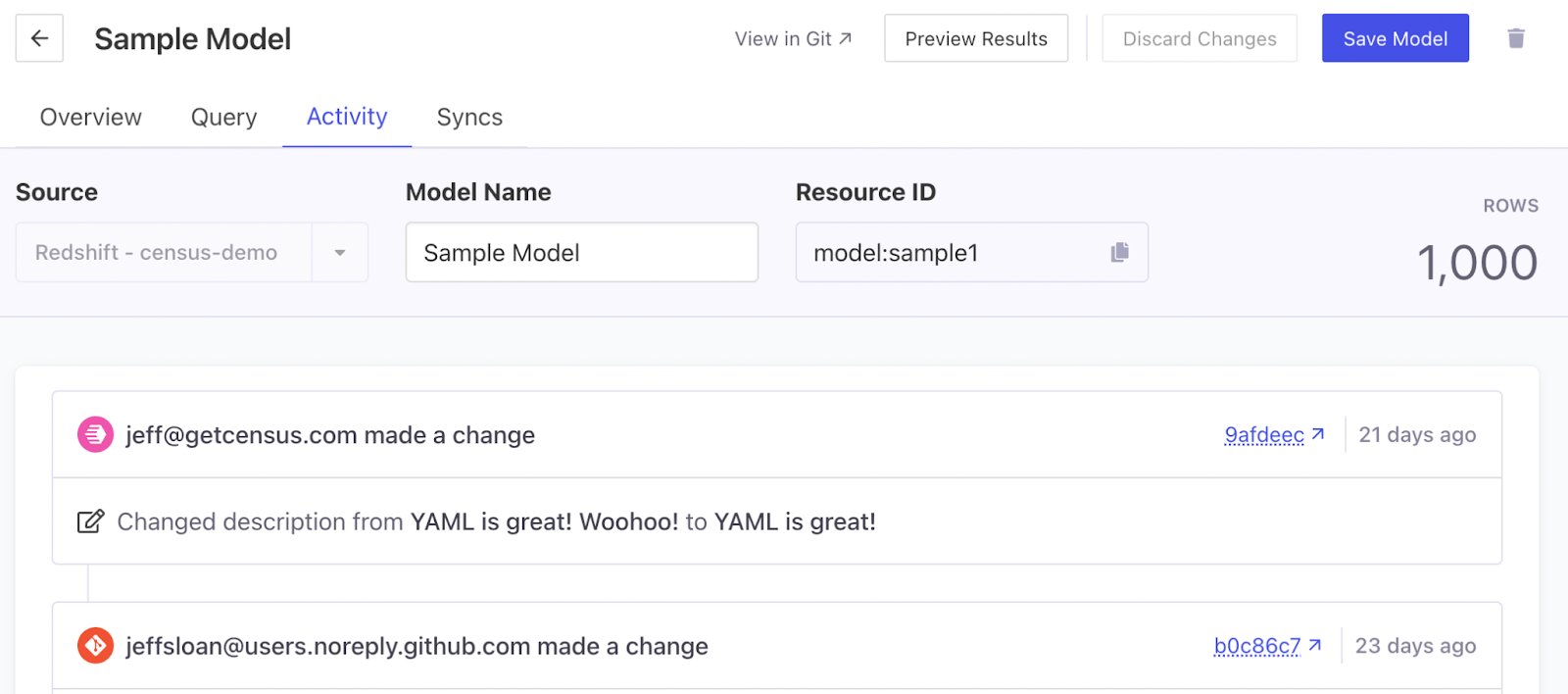
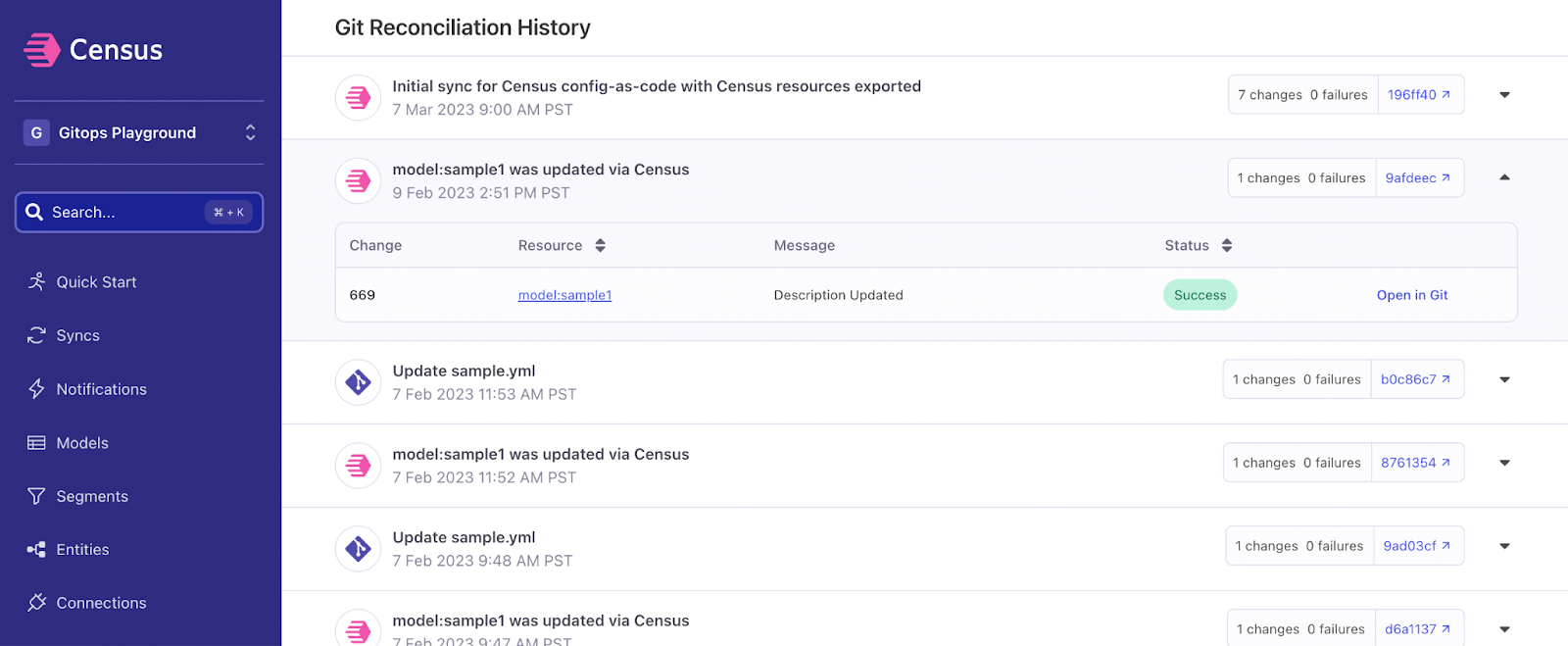
Furthermore, we provide an easy-to-audit History view of all SQL Model changes across your entire Census workspace. Whether from GitHub or the Census UI, you will be able to isolate exactly when changes went into effect, and the git commits associated with that change.
Ready to get started?
Git-backed Models are now in Open Beta for all customers on the Census Platform Plan.
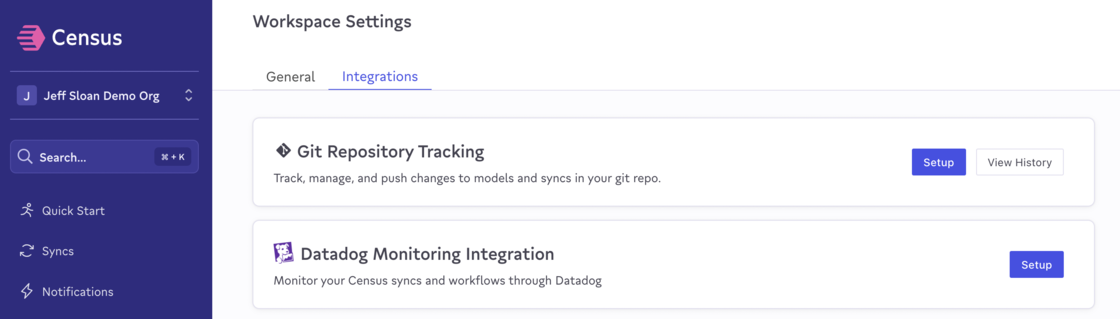
To enable, head to your workspaces's Settings > Integrations page, and click "Setup" for Git Repository Tracking. For more details, please visit our docs.
What’s next?
We believe that all Census resources should be manageable in code. SQL Models are our first step on this journey, but Entities, Segments, and Syncs are also critical resources to manage in code on our roadmap. Try the feature now, and be kept up-to-date on our progress in enabling git- and code-based workflows to manage these Census resources.