































Getting reliable access to data is one of the toughest challenges faced by data teams today. Data often sits in silos, is constantly changing, and lacks the uniformity or structure desired by downstream platforms.
That’s why so many organizations have come to rely on Fivetran for their automated data movement platform. With 300+ pre-built, no-code connectors, Fivetran helps you move all of your data into one centralized cloud data warehouse while managing the most time-consuming elements like schema drift, updates, security, governance, and more.
And while centralizing your disparate data into one location is imperative, it does not mean that data is ready to be activated. ⛔ In fact, the majority of data teams acknowledge that they miss out on key opportunities with data simply because it’s not in a usable format for decision-making. They end up spending a disproportionate amount of time focusing on the workflows of data modeling.
The importance of data modeling
Data modeling is the process of taking raw data after it has been loaded into your cloud data warehouse and transforming it into analytics-ready tables through cleansing, harmonizing, and structuring. It enables you to organize random data points and make them actionable — like generating a Customer 360 view that highlights opportunities for every GTM team. 🔦
Without properly modeled data, your downstream activations are wasteful and potentially even harmful, as you might act on inaccurate information. As the old adage goes: Garbage in, garbage out. 🗑️
So, if you’re sending unstructured, unharmonized, uncleansed raw data (aka garbage) into your data activation platform – like Census – then you likely won’t get the results you want. That’s why any proper data activation program requires a proper data modeling strategy to complement.
There are several benefits of going through the data modeling process:
- Standardization of data: Data modeling standardizes data by establishing a clear format and set of rules for how data should be structured. This ensures consistency and accuracy, which is essential for making data-driven decisions.
- Improved data quality: Data modeling also improves data quality through validation and cleaning. This reduces the risk of errors and inconsistencies when data is activated or analyzed.
- Efficient data processing: As reverse ETL becomes near real-time, data pipelines need to become more efficient. With a clear data modeling process, you can send data into operational flows as quickly and efficiently as possible.
- Integration with other systems: A clear data model can also conform to the needs of other systems, ensuring the data you push into a customer-facing destination is accepted and recognized.
Data modeling challenges
Data modeling, however, is often manual, done by the data team per source to conform disparate data sources into the correct format for downstream systems. The data team has to take on the responsibility of each source and consider aligned stakeholders’ specific needs.
Heightened stress aside, this puts a taxing burden on strapped resources, resulting in bottlenecks and delayed action. ⚠️
But with a proper tool and strategy, data teams of any size can overcome these obstacles and find efficiencies in their data modeling strategy. They can take the data available to them and scale results and activations, all while freeing up time from foundational work to focus on more bespoke needs.
Raw data 👉 activation-ready data
It was with these needs in mind that Fivetran recently released Quickstart data models. This new point-and-click, no-code solution helps data teams turn raw source data into activation-ready tables — no dbt projects or 3rd party tools required. The best part? Implementation is simple and the impact is huge. 🙌
Let’s say that you are looking to reduce the amount of time needed to identify your GTM teams’ highest propensity buyers. The sellers want to sell, not spend time combing through data. So, you want to turn raw Salesforce data into lead-scoring insights that you feed back into Salesforce to help inform prospecting.
To quickly model and activate data with Fivetran plus Census, all it takes is four easy steps:
1. Set up a Fivetran connector to extract and load Salesforce data into your cloud data warehouse of choice
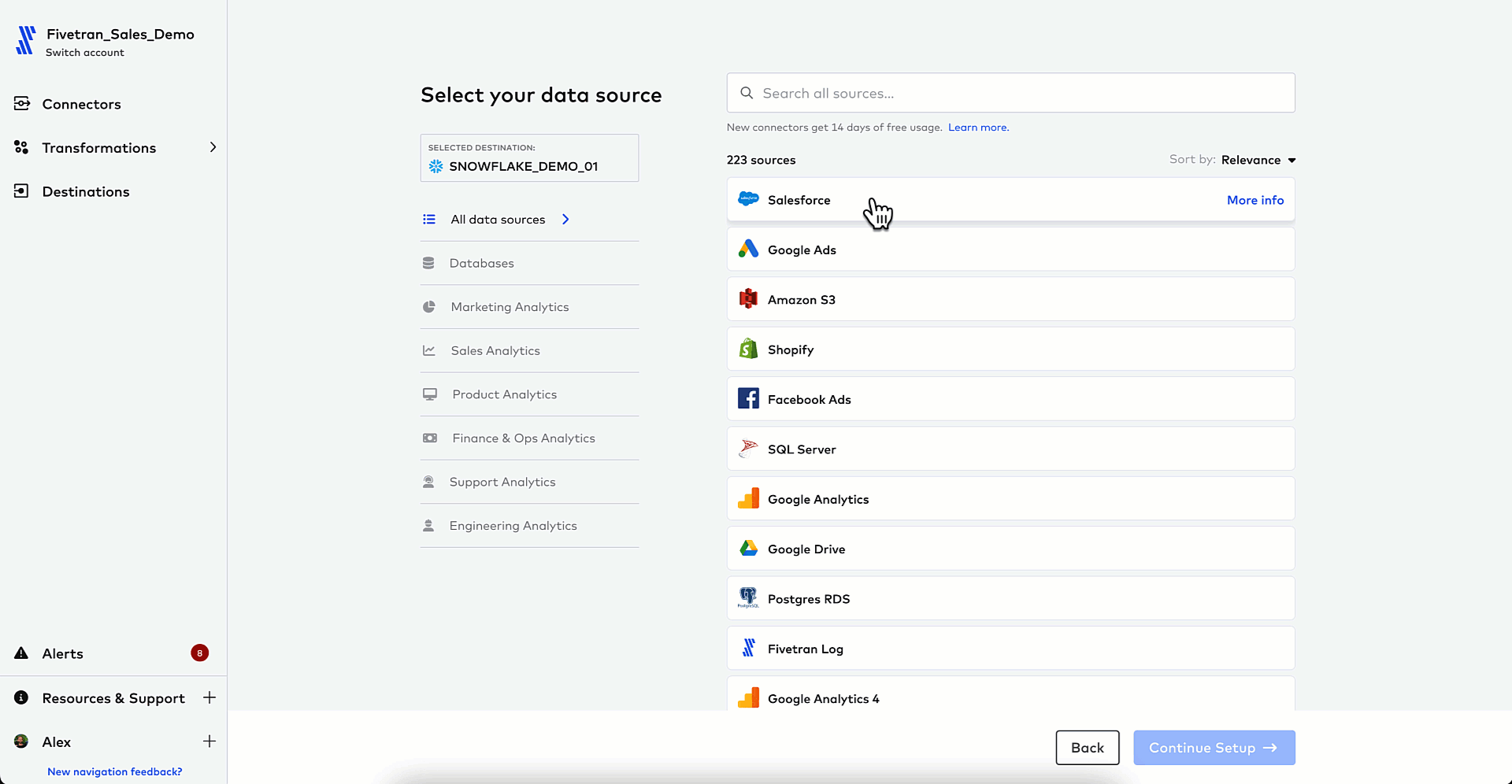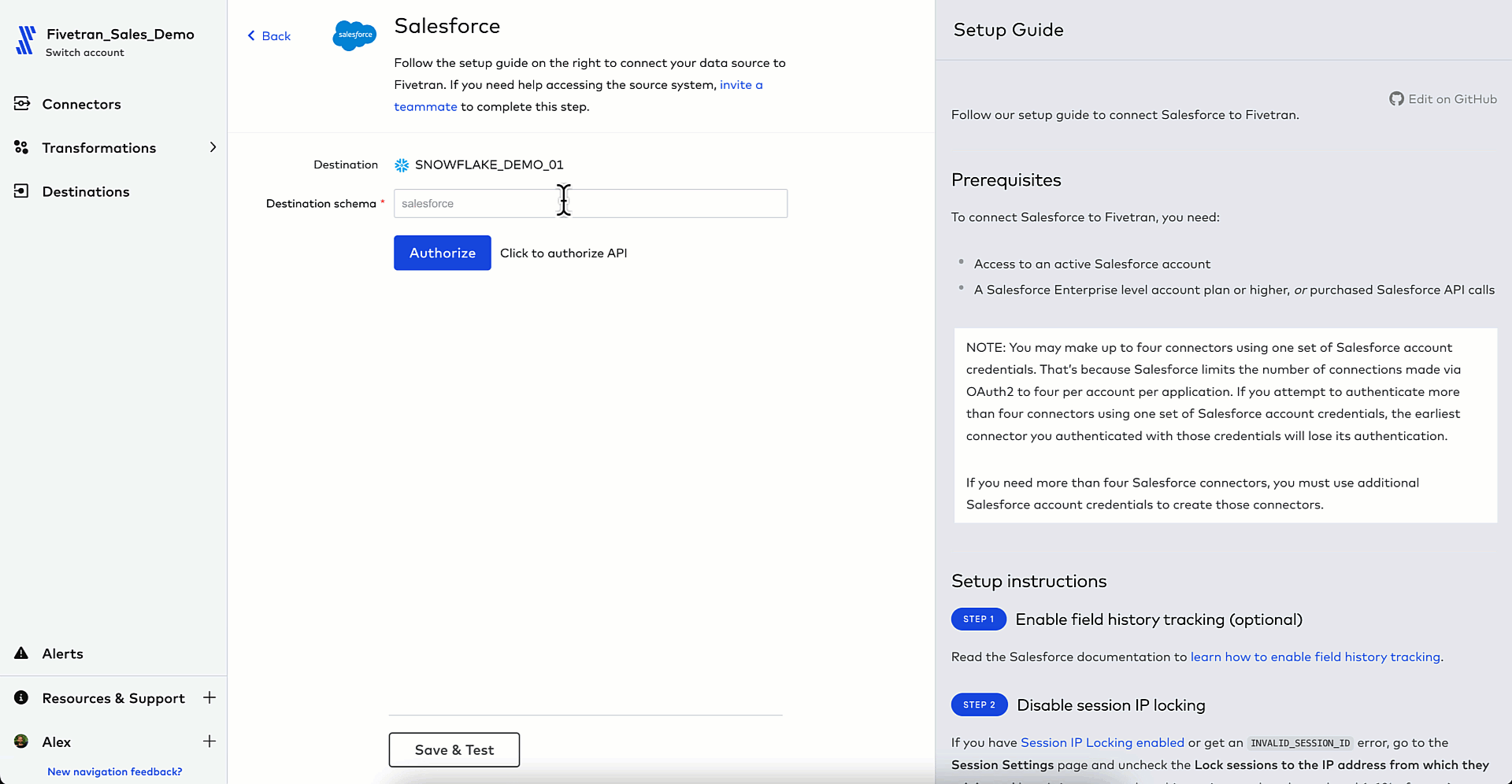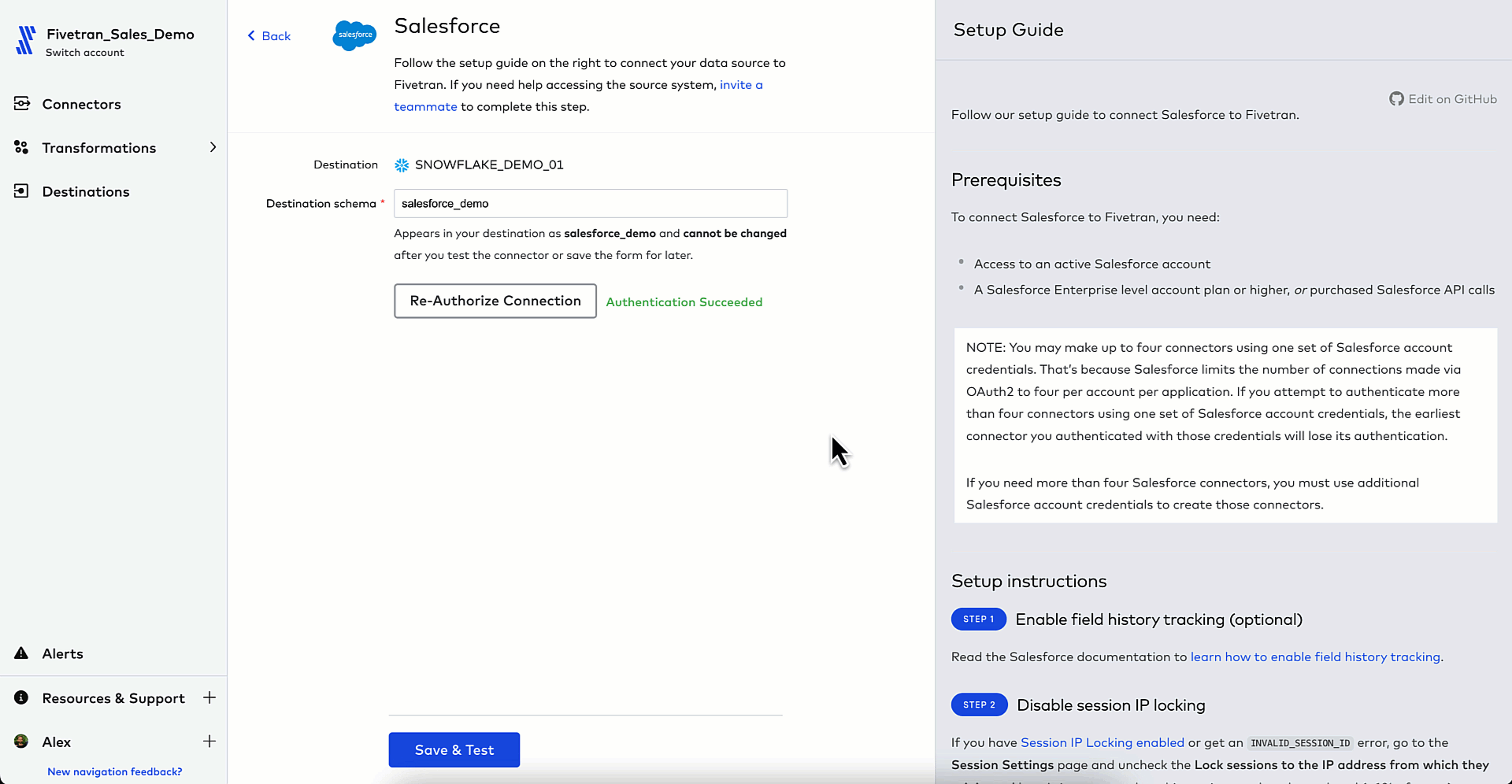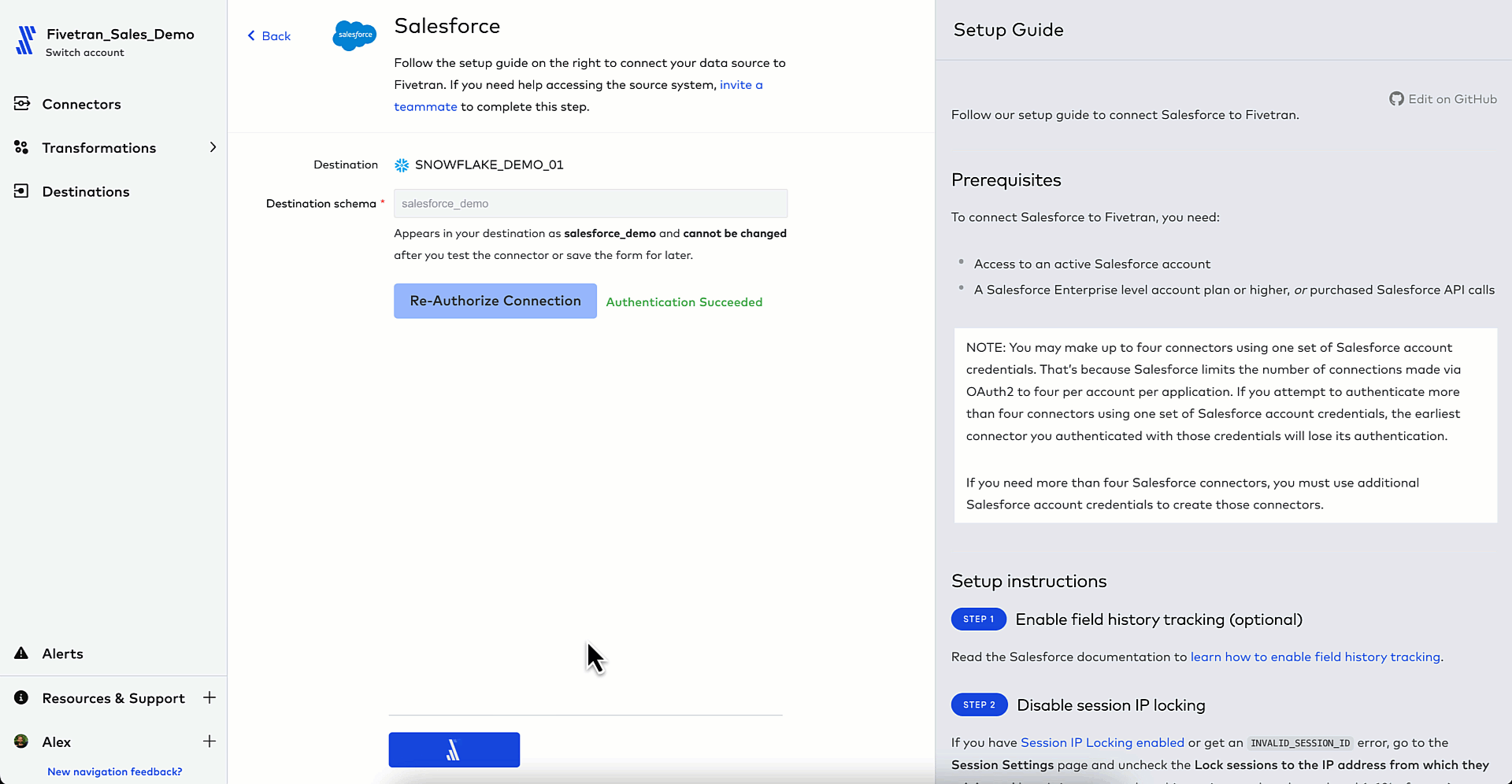
2. Add your Quickstart transformation to transform your raw data after it has loaded into your destination
3. Configure your Quickstart data model with a few clicks so that new, raw data is automatically transformed into lead and opportunity tables upon load
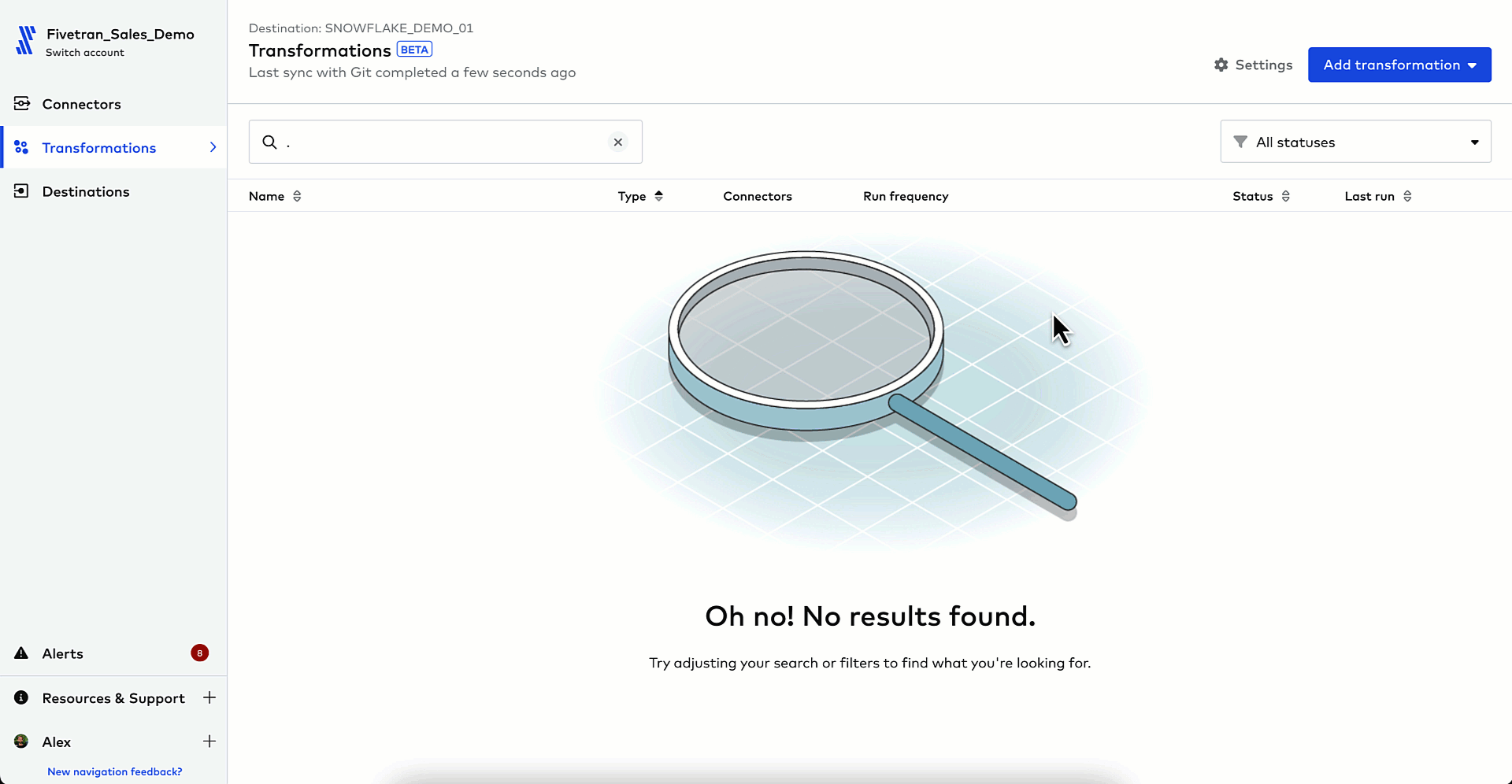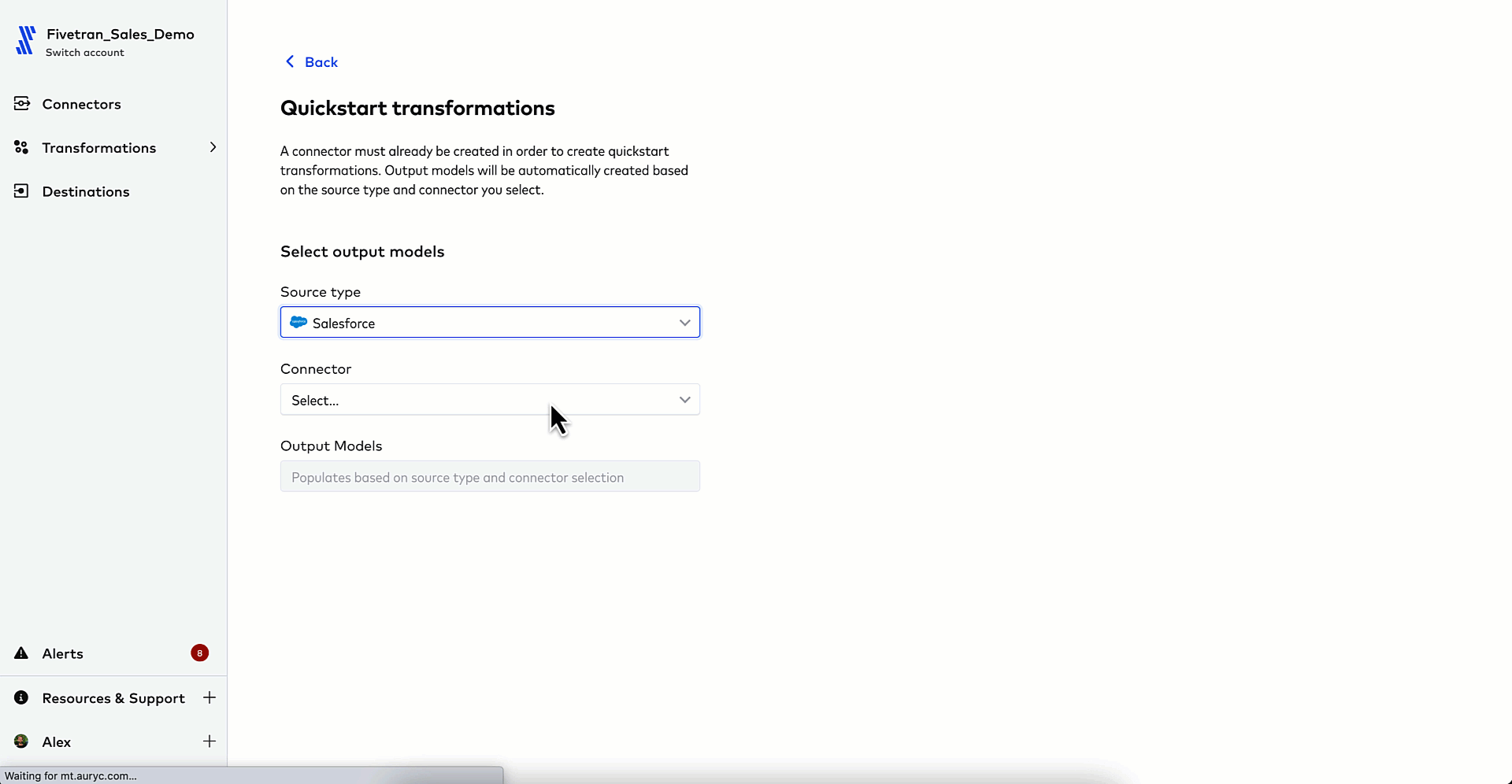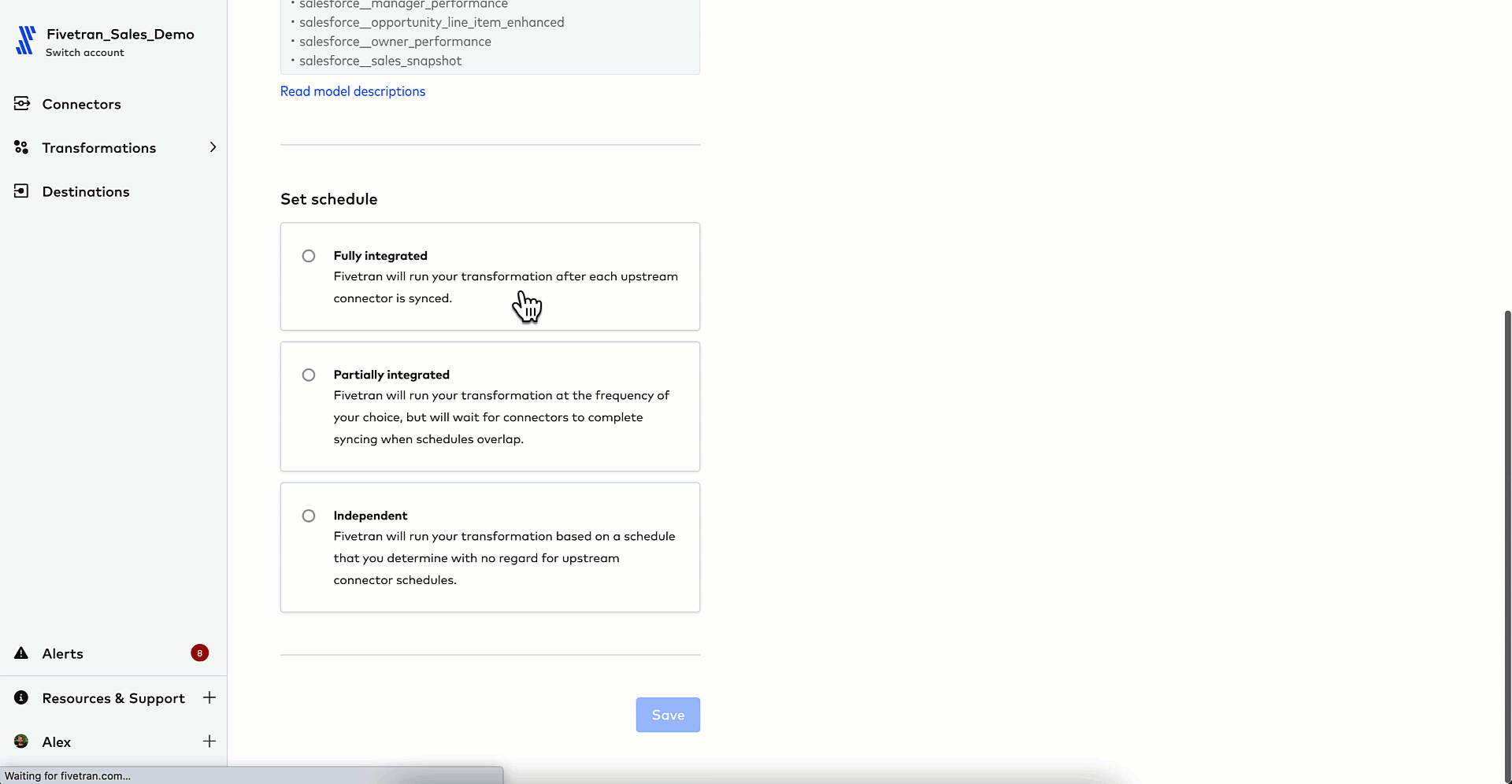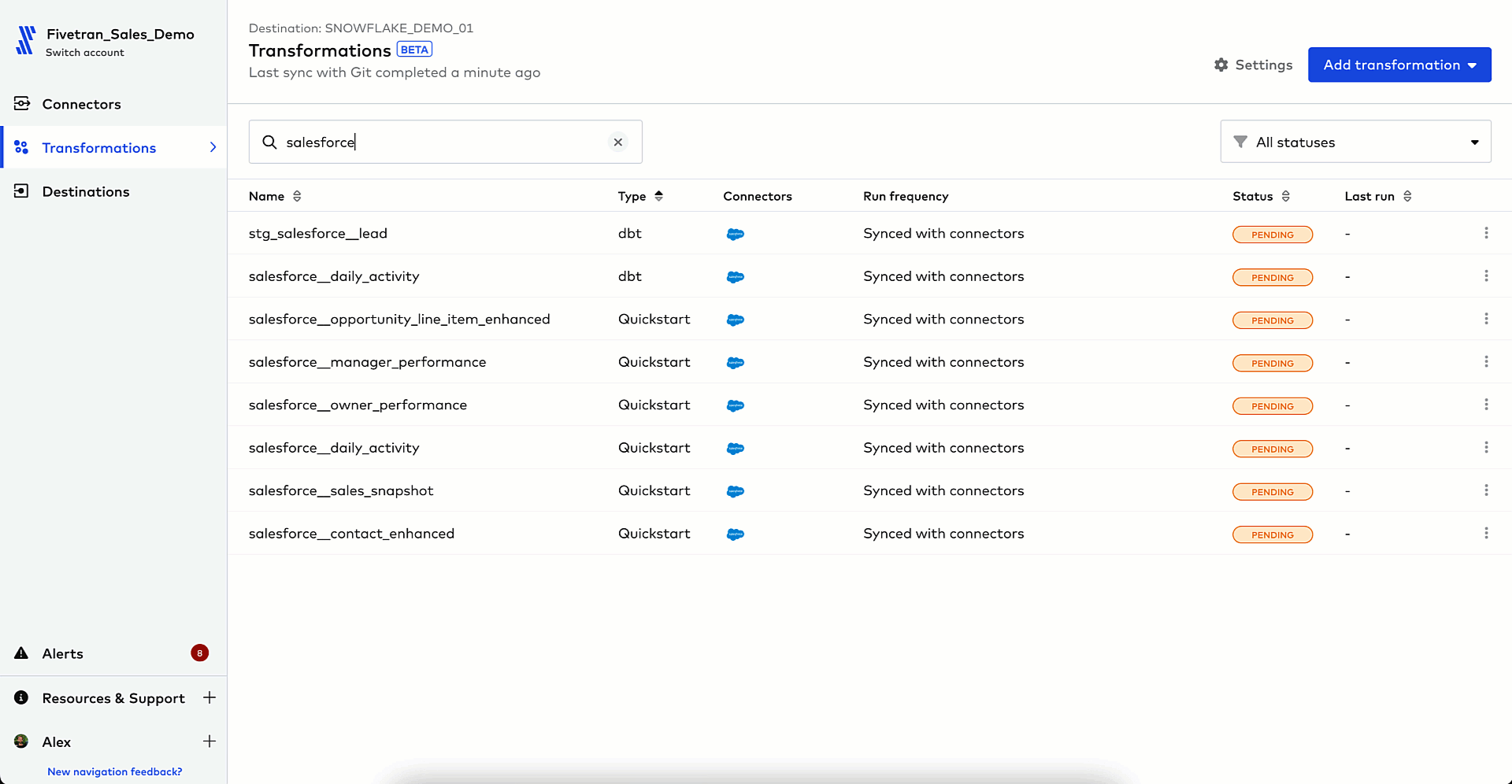
4. Activate this transformed data back into Salesforce using Census
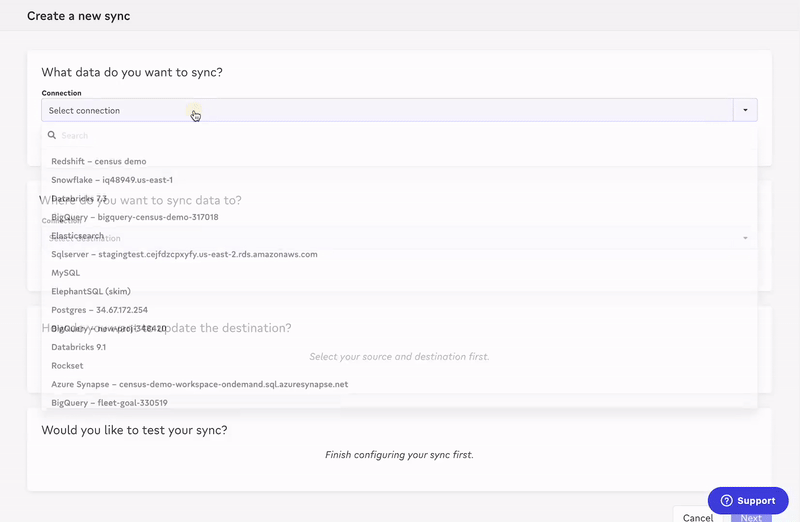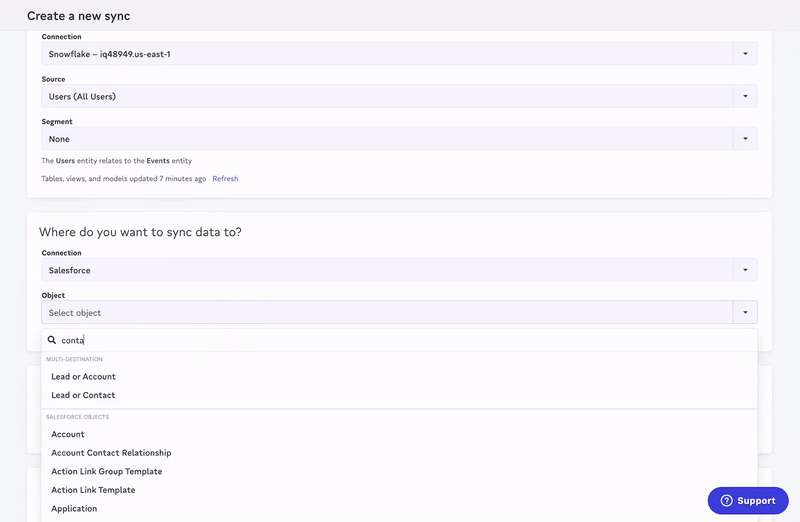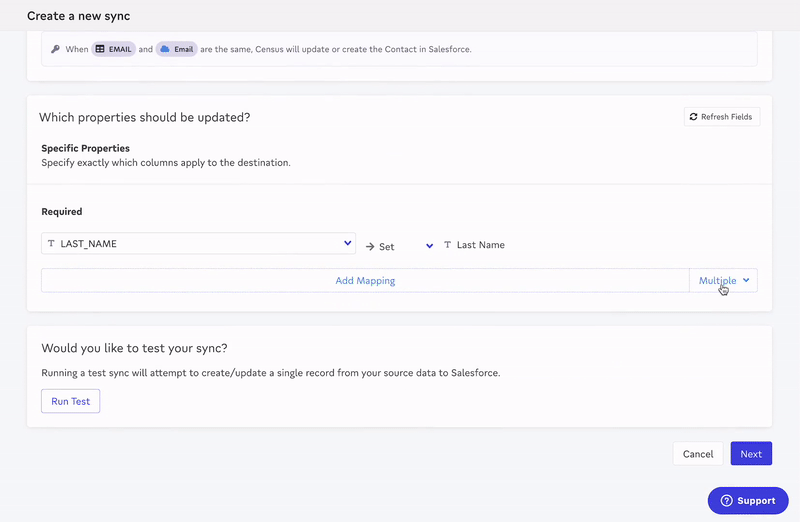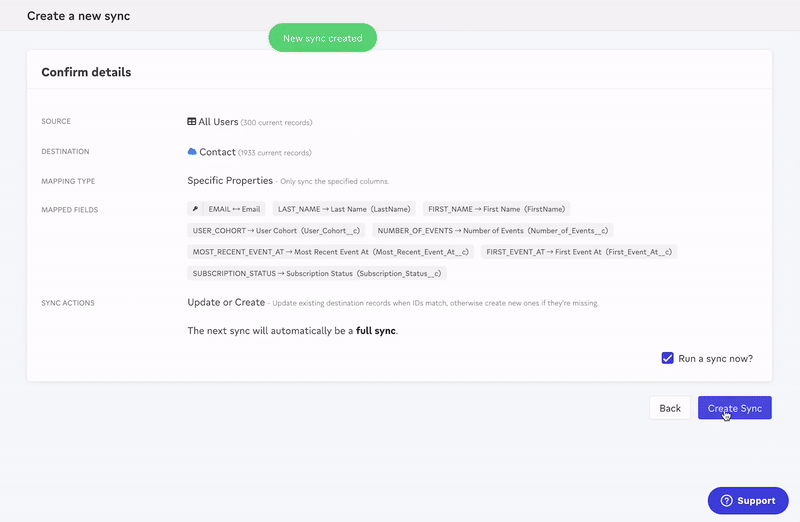
Just like that, you have the results your stakeholders want (in a fraction of the time). Your sales team is now more aware of opportunities and can have more efficient conversations.
And as a data team, you’re able to model your data at scale, without creating bottlenecks or spending time on manual custom coding. Your time is valuable and should be spent on the highest-impact projects — let Fivetran and Census automate the rest.
Fivetran + Census = ❤️
Together, Fivetran and Census give every team the data they need to act and automate with confidence. Mutual customers like these have been able to supercharge marketing personalization and sales outreach:
- Canva powered personalization to 100M+ users with Customer 360 profiles and dynamic segmentation in Braze
- Figma increased sales productivity by 10x with product usage data inside Salesforce
- Zip unified all their audience segments between Braze and the Zip app for personalized omni-channel campaigns
- Fivetran built a 360° customer view for better lead scoring in Salesforce and Marketo (yes, we’re a Census customer too!)
💪 Want to learn more about how Fivetran can help you scale your data practices? Sign up for a 14-day free trial.
💡 Want to see how Census can sync your customer data to all your downstream tools without any code? Book a demo with a Census product specialist.