































For the past 6 months, I've been helping dozens of companies and newly formed RevOps & Data teams that are hitting the limits of what I call the "Founder Data Stack" (one marketing/sales tool that holds most of your customer data). It usually combines a single tool like Intercom/Hubspot with events forwarded by Segment.
Overall, the founder stack looks something like this 👇
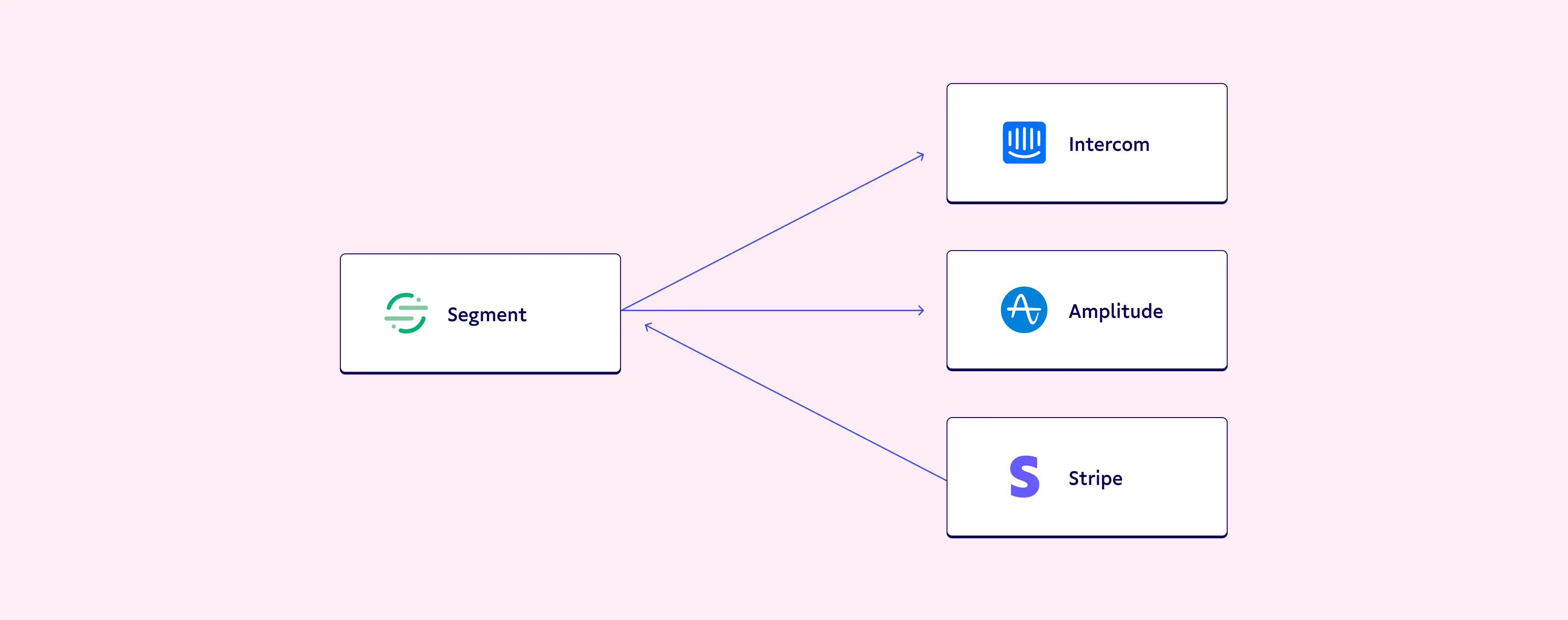
🤔 Pretty simple right? So what is the problem?
More People, More Tools, More Data, More Problems
As your company grows, new employees add new tools to the stack to help them do their jobs:
- Salesforce is added for sales
- Hubspot, Marketo or Customer.io for marketing automation
- Pendo for product data analysis
- Outreach, Salesloft, Reply.io to help with sales engagement
- People.ai, Mixmax, Yesware, to help with sales productivity
- Livestorm, Zoom, Crowdcast for webinars
- Wordpress Ghosts, Gatsby for their blog
... and the list goes on. 6 months later, your stack of tools looks something closer to this.
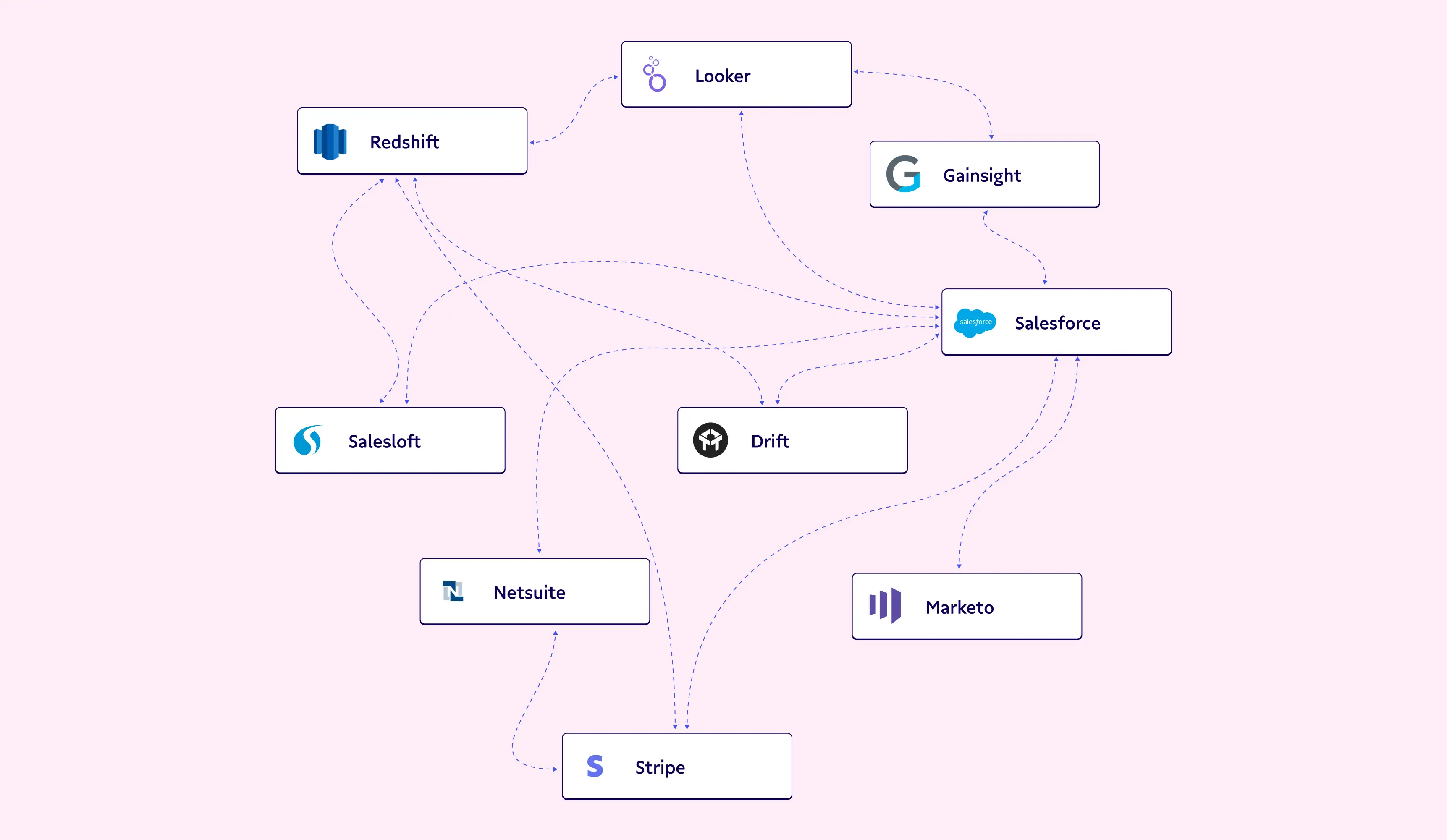
This explosion of tools is not a problem in itself. The real issue lies in the fact that all of these dotted lines represent point-to-point integrations. This means that there's no unified control plane for how data gets to all the tools. If something goes wrong, or you need to make a change, nobody knows where to find it. These applications were never designed with this integration outcome in mind.
Even worse, these point-to-point integrations are usually built with custom one-off code, which makes it hard to maintain over time. This mess creates inconsistent data, duplication, and leads ultimately to data you can't trust.
Don’t think you have this problem? Here's some classic symptoms, can you answer no to all of these?
- The Sales / CS / Support teams have 3-5 tabs open to understand what a customer is doing.
- One of your tools might say the customer is on a free plan, and the other one shows they are paying $399 / month.
- You have sent automatic emails to the wrong customers or multiple copies of the same email to one customer.
- It takes 2+ weeks to run any in-depth report and analysis that uses a mix of product & customer data. By the time you finish the analysis, the source data (usually based on CSV files) is out of date.

Problem: No Single Source of Truth
Without a single source of truth, you will suffer from garbage in, garbage out across your whole stack. Because of this, teams won't trust their reports & analysis because they think the data is inaccurate. Automations & workflows will misbehave, sending the wrong emails to the wrong person with the incorrect personalized value. Incompatible IDs will generate tons of duplicates, which will lead to more bad data. The result is that you will have a recurring calendar task where you will spend your day cleaning the mess manually across your tools.
The solution is straightforward. As your company and the number of tools grow, you need to maintain a single source of truth that:
- enforces data consistency
- syncs data across all of your tools
- can be queried when in doubt
Solution: The Modern Data Stack
There's already a tool perfectly suited to storing massive amounts of data, that can be queried easily, and is connected to everything. A database or data warehouse. You probably already have one running in your company that you can reuse so you don't need to buy another CRM, CDP, DMP, MAP, or any other acronym.
Building around a data warehouse as part of a modern data stack has additional benefits such as:
- You own your data. It helps you comply with different regulations.
- Get value quicker. It is 10x easier to dump historical data in a DB than importing the data in yet-another-tool.
- Easier to sync with other tools. Databases integrate with everything, contrary to SaaS Tools that have limited APIs (and please don't get me started on APIs like Marketo).
- Reusability. Other teams in the company can use this trusted source of truth.
In addition to a data warehouse, you will need 4 other key components for your modern data stack:
- An event tracking tool. You can continue using Segment here. It does the job well and allows you to collect events across all of your websites & apps.
- A data loader. I recommend Fivetran. It’s easy to set up in a couple of clicks and amazingly reliable.
- A data modeling tool. DBT is the new power tool here. It allows you to transform and model your data.
- An Integration Platform. I’m a 100% biased here, but I recommend using Census. We integrate well with DBT and enable you to sync your clean and unified data models back to all of your other tools.
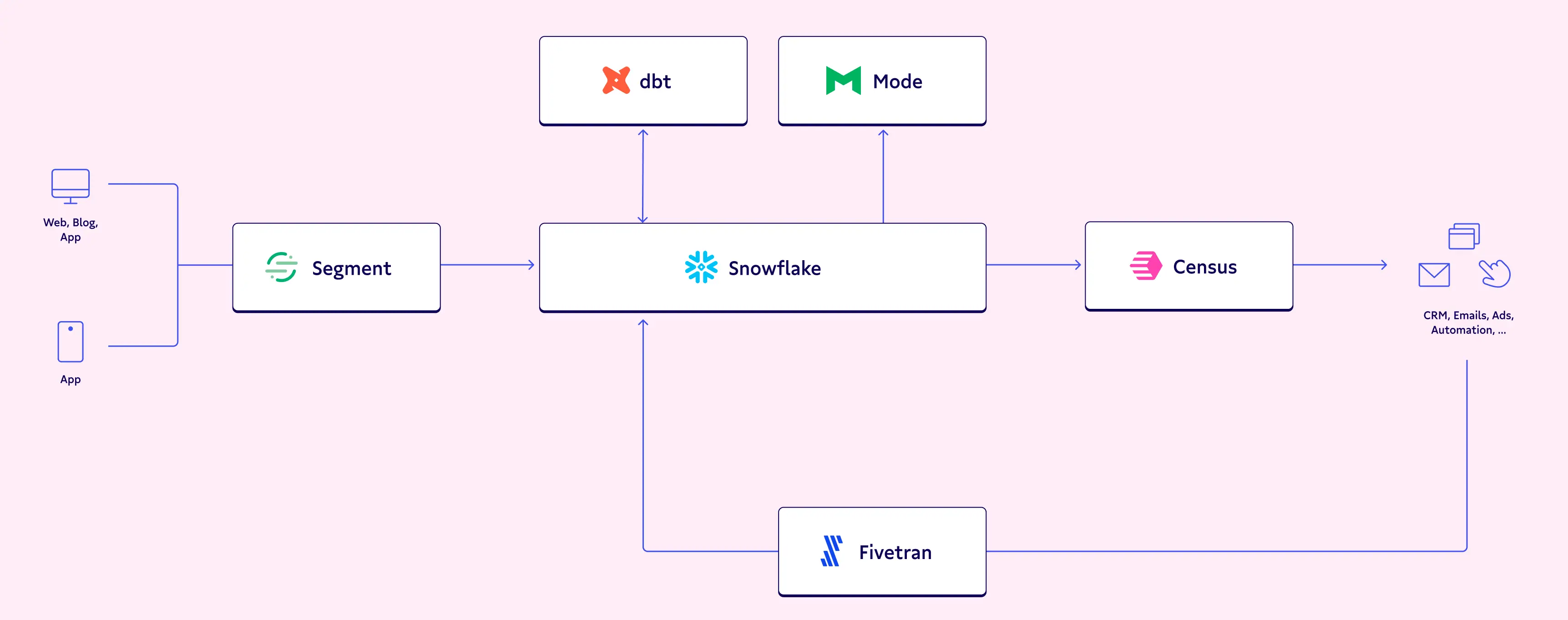
As a bonus, you can replace Amplitude with a BI tool like Mode or Chart.io, which is cheap and as good as Looker.
What do you get?
Done right, this modern data stack will help you centralize all of your data in one accessible place so you can create unified models and sync them to the tools each business team uses. Here's some of the way you can put the resulting data to work:
- Create segments of users based on features they use to create personalized education campaigns
- Create Account Health Scores and report in your CRM to help your CSM team prioritize their time
- Use the same customer view across your tools
- Notify Sales reps that there is activity in an account that is currently in a trial
- Retarget on Facebook & Google disengaged users based on actual product data
Bonus, everyone gets to keep using the tools they love.
Finally, despite the look of it, this modern data stack is straightforward to deploy and requires near-zero maintenance. Best of all, it is pretty affordable and costs will scale with you.
How to get started?
I would encourage you to start small. Take one end-to-end data flow and build the modern data stack to solve that use case. It could be pushing aggregate product usage from your web app to Salesforce to give your sales team visibility on product adoption. Or it could be syncing payment data to your marketing automation tool to send emails to your best customers and turn them into champions.
If you have any questions, don't hesitate to contact us. We are happy to do a full review of your existing stack for free!
- Drop us an email 👉 contact@getcensus.com
- ☎️ or schedule a call on this page
Or want to check out Census for free for your modern data stack?