































Airbnb is one of the most data-driven companies in the world, largely due to how well it scales data-driven decision-making. It got there by building sophisticated data infrastructure that gave everyone in the company access to information.
A lot has already been written about how Airbnb approached growth (check out this great interview). One of the lesser known pillars of how they make data-driven decisions is their Data University. It's something they had to iterate on internally until it paid off.
Despite open-sourcing much of their tools & techniques, most companies are still playing catch-up. Here's how you can learn from their history and take similar steps towards transparency & education in your organization.
Data Democratization’s History at Airbnb
The Data University program, founded in 2016, was modeled after Google’s internal team training programs. Airbnb’s original motivation for educating their teams was to give a “voice” to their customer through data. From product analytics or accessible datasets of customer actions, Airbnb enabled data-driven decision-making across the company.
Essential to this effort was making the data accessible and easy to understand for everyone, no matter their role at the company. In other words, all employees needed to be able to analyze the data independently. So Airbnb prioritized developing 100-level, foundational classes over the more advanced classes (which were created later for developers). All told, Airbnb launched Data University in the first year with 30 classes.

Airbnb had tried to democratize data and roll out the tools to analyze it to all teams three times before. Why was it successful the fourth time?
The successful launch of Airbnb’s Data University can be traced back to three factors:
- The curriculum was approachable for each employee, regardless of job function. In prior attempts, there wasn’t an emphasis on equipping beginners with tools to succeed.
- Airbnb’s leadership set clear expectations for teams in data literacy. From the get-go, the priority was for managers to discuss progression through Data University and emphasize to direct reports that data-driven insights were the expectation upon completion of the program. Top-down, this education’s value was reinforced.
- They found ways to measure the successes of the program. The main metric used was weekly active users (WAU) of Data University, in addition to how many Airbnb’ers took classes and NPS scores from attendees. Notably, these methods of measurement continue to chart success over time.
“We used a metric of weekly active users (WAUs) of our data platform as a proxy to how ‘data informed’ we were as an organization. At the beginning of Q3 2016, only about 30% of Airbnb employees were a WAU of our data platform, which was significantly lower than other hypergrowth internet company peers we benchmarked with like Facebook and Dropbox.” — Jeff Feng, PM Lead for Data at Airbnb
After the first six months in 2016, 45% of Airbnb was weekly active users (WAU) of the data platform, a strong 66% gain in the first half-year of the program. A related metric of success: Airbnb became profitable for the first time in the second half of 2016. This profitability meant more hires, more hosts and stays for Airbnb, and thus more data to analyze.
Data Scientists Scaled by Training Thousands
The key to democratizing your own organization’s data lies within your own employees, those working with the data regularly. Data science teams should dedicate some bandwidth to educating the rest of the company if you want to have maximum impact. That’s right—you don’t need to hire “educators.” Data scientists can, and should, teach your product managers and operations teams directly if you want to make more data-driven decisions. Fortunately, the data champions in your organization don’t have to be huge in numbers to make a significant positive impact on the data insights your team can dig up with their guidance.
Airbnb’s data analysts and scientists made up just 1.6% of their total workforce in 2016-17, but because of Data University, the company was able to inform every decision employees made with data. Proper employee training of any type ensures that the workforce has all the tools needed to succeed, so Airbnb set out to arm their workforce with Data University to increase transparency with data and scale the impact of their small but mighty data team. They were determined to prevent data holding back their growth.
This meant amplifying the impact of that small, mighty data team beyond headcount. Said Feng at the outset, “In order to inform every decision with data, it wouldn’t be possible to have a data scientist in every room—we needed to scale our skillset.”
This system of using data-scientist employees as educators to scale impact across the company was a page out of Google’s internal training book. Per Google: “Your own employees are perhaps the most qualified instructors available to you.”
“Your own employees are perhaps the most qualified instructors available to you.”
What did this look like a year later, mid-2017, after the launch of Data University? By then, Data University was powered by 30 volunteer data science “faculty members."

These 30 volunteers effectively scaled their impact to 500 unique people who had participated in at least one class, or educating nearly one-eighth of all of Airbnb, as of May 2017. And Airbnb began to measure a new metric, given the successes: depth of engagement. As of May 2017, employees who had participated took more than four classes on average, totaling over 2,100, as Feng called them, “butts in seats.”
He added, “Every class offered thus far has a net promoter score of +55 or higher,” another key metric to mark Data University's success.
Powered by the internal data minds at Airbnb and a shared goal of bringing learning back to the workplace, the company laid the foundational work to establish data-driven decision-making as part of “business as usual” at Airbnb.
The 3 Competencies of Data-Driven Organizational Decision-Making
A commitment to data democratization, according to Feng, “not only help[s] ensure that decisions are grounded in data, but it enables people to make decisions autonomously. This is important because the person asking the question always has the best context on the question they are trying to answer, and it reduces the feedback loop to answering questions. This also has the side benefit of freeing up some of the data science team’s time.” Making that conscious commitment as an organization is the first step.
Both a method and a company culture, data-driven decision-making becomes possible only once all employees are trained as “citizen data scientists” and well-versed in three areas. The three competencies to ensure people make good, data-informed decisions as imagined by Airbnb are SQL/data proficiency (data education), access & documentation, and tools.
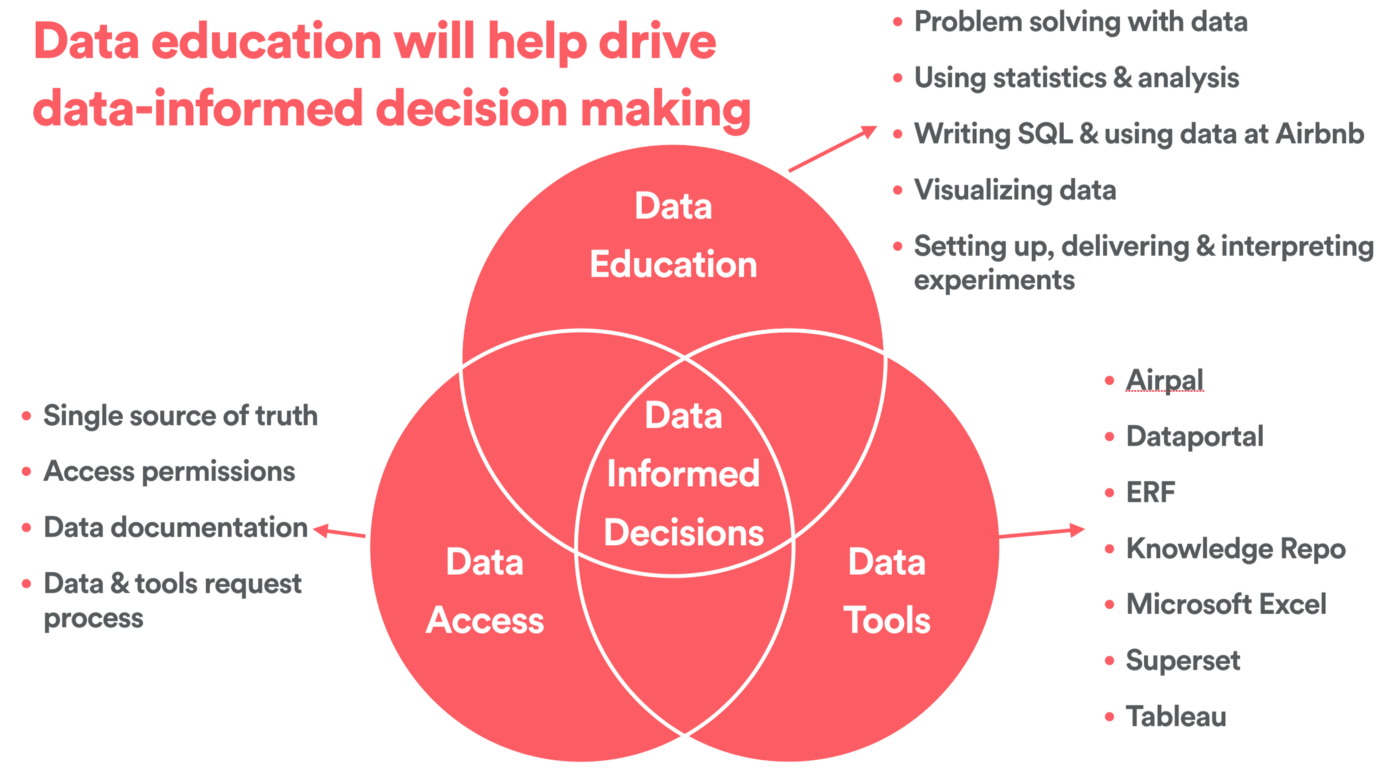
Data Democratization Program Grows with Airbnb
In the years since its 2016 inception, Airbnb has iterated on and created additional programs to augment Data University (Data U).
In December 2018, the condensed two- to three-day training of Data U Intensive was born to solve for two limitations of the original university:
- Tweaking training content to address specific needs of a department or team
- Cross-training more data champions who are members of the teams they serve
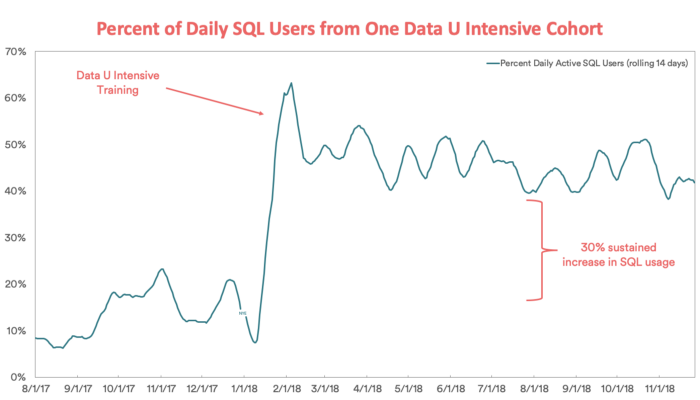
As of January 2019, over 400 Data U Intensive courses have been taught to thousands of Airbnb employees by 55 faculty members. The ROI speaks for itself, with the number of daily SQL users leaping up after the first Data U Intensive trainings.
After the rollout of Data U Intensive courses, educating users on the value of and how to use SQL, the percentage of daily SQL users spiked from a lowly ~7% to a peak of ~62% of users less than one month later. This sustained increase evened out to a solid 30% increase in SQL usage year over year from 2017 to 2018.
Airbnb’s most recent advancement is the Engineering Empowered Data Science program to deepen their data scientists’ knowledge of the engineering landscape and streamline collaboration with engineers. New use-cases for this educational framework arise constantly across teams, and Airbnb is prepared to evolve to meet those needs.
Once data insights are surfaced and are readily available to your team, there arise hundreds of ways to analyze them, combine them for new learnings, and open up new venues to explore further.
Airbnb Sets the Standard for Forward-Looking Organizations
Data is power, and the more organizations can adopt this system of radical transparency, the more quickly they can respond to market fluctuations and changes in the economy. The stakes couldn’t be higher for those organizations that don’t take employee training seriously.
For Airbnb, trial and error was and continues to be part of the process. The company continually learns from its successes and failures, cracking the code along the way and adapting quickly to Airbnb’s growth, and communicating learnings about their customers through data.
It doesn’t take establishing your own “university” to follow Airbnb’s example. Take your own steps toward data democratization right now.
- Setup an internal presentation series. This goes without saying but your data team should budget at least 1-2 hours per month to share their knowledge with the broader organization. You can do this by soliciting a data-driven presentation from an internal expert for a lunch-and-learn or sponsoring knowledge-sharing sessions like “professional book club” discussions.
- Introduce 1:1 tutoring. Your own team can be the most powerful instructors. Randomize matching data scientists to members of the team to cover bite-sized topics together in monthly 30-minute 1:1s. Survey the pairs after each round to compile topics to pull together in future courses.
Want to become more like Airbnb? Boiled down, you need two things: the right tools and to teach your company SQL skills. It will pay off. Census helps operationalize your data democratization efforts to make customer data insights accessible for your employees. Forming your own coalition of citizen data scientists is only a demo away.
Read on for more inspiring customer stories and powerful applications of Census’s reverse ETL platform across the myriad tools you use for the customer, marketing, and sales data.