































When building a resilient system, observability is key. Things fail in data pipelines, and when they do, it’s important to show, at the record level, what failed and why.
When you add a reverse ETL layer to manage the data flowing between your data warehouse, BI tools, and operational tools, it seems like it should snap right into place. But even without reverse ETL, data pipelines interact with managed servers, changing data types, memory constraints, even buggy code. When you build integrations with third-party services you can spark record-level failures, APIs that behave in unexpected ways, and more.
I view data as a hub-and-spoke model. The data hub is a single source of truth. The Census API can be triggered by any workflow in any language and deliver third-party applications the data they need. With third-party APIs off your plate, you can focus your energy on optimizing pipelines and building SLAs instead of whether data is showing up in HubSpot the same way it shows up in Salesforce.
Wistia first became interested in Census because the custom integrations it built into its pipeline were causing too much friction. Wistia’s users engaged with a Rails application that sits on top of a MariaDB database. Fivetran replicates the database into Amazon Redshift.
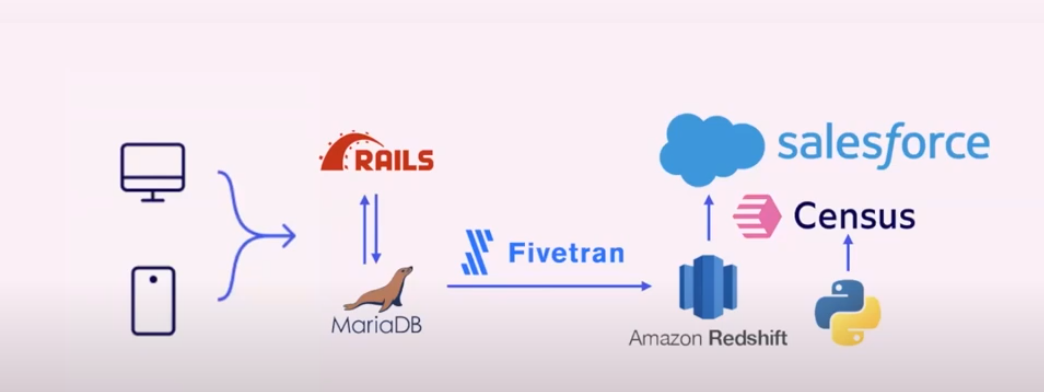
Wistia’s sales and customer success teams needed to see in Salesforce how users were interacting with the application.
“The Wistia app had this custom integration from Rails to Salesforce,” Chris Bertrand, data scientist at Wistia, said during our presentation at DataOps Unleashed in February. “There were five main issues with that setup that were pain points for us.”
Here are the five challenges Wistia ran into with data visibility–and how a hub-and-spoke model solved them.
Challenge 1: Updates took too much effort
In Wistia’s data architecture, all the events came from the main application. To avoid taking down the main app while making updates and fixes, tests and code review had to go through someone owning the portion of the application being updated.
“It was a lot of hoops,” Chris said. “It felt like an outsized effort to make relatively minor changes.”
Updates were further complicated by nuanced differences in definitions. Engineers were often asked to make changes without understanding the business context behind them, or on the other hand, people without an understanding of the engineering context were being asked to review the code. This had the potential to cause multiple different definitions across point-to-point integrations, which got messy fast.
When you build a resilient system, you have a central source of truth for definitions. This is important because stakeholders in sales, customer success, and engineering may have different viewpoints of the same issue.
With Census, the data being passed into Salesforce is now described and managed by dbt models on top of Wistia’s Redshift data warehouse. To make a change, users submit a request in the dbt repo, which is much faster and easier than going through the main application. The central source of truth dbt provides prevents the definition confusion that marked the earlier process.
Challenge 2: There was a language barrier
The Rails database is built in Ruby, a language few of Wistia’s data team members are fluent in. Like me, they prefer SQL and programming in Python. This constrained the number of people who could actually make changes to the custom integration pushing data from the application into Salesforce. As a result, requests for updates were often put off as a chore no one had time for.
With Census and dbt, changes are made in SQL and jobs are orchestrated in Python. Since many people are familiar with this much more common language, the workload of making updates can be spread across a larger team.
Challenge 3: Information had to be carefully sequenced
Not so much a pain point as a requirement, the data moving into Salesforce has to be sequenced in a very specific way to maintain the integrity of Wistia’s internal data model. The company worried this would make its custom integration difficult to replace. They were relieved to find the Census integration is still customized and syncs data in the exact sequence the data model requires.
“We’re relying heavily on the API to run all our syncs, and we’re able to sequence the syncs to make sure that when new records are inserted or updated in Salesforce, those updates are happening so that all the data ends up where it should be,” Chris said.
Challenge 4: Lack of data visibility
The whole point of a resilient system is a visible single source of truth for all business definitions. Wistia’s pipeline only provided access to application data and–even for the ad platform, Hubspot marketing data and Stripe payment data already in Redshift–the data team had to develop and maintain multiple separate integrations via third-party SaaS tools to Salesforce.
“To get something like our derived business logic into Salesforce, we had to decide whether it was worth building out that business logic into the Rails application – even though it had nothing to do with that application,” Chris said.
Now, these definitions are defined in dbt and living in Wistia’s Redshift, capable of being actioned in their tooling thanks to Census. For example, Salesforce has access to all the data in the data warehouse: including Stripe, Hubspot, and ads platform. It doesn’t require point-to-point integrations with every tool.
“We now have this whole slew of data we’re able to push into Salesforce,” Chris said.
Challenge 5: A garbage fire of overalerts
Wistia’s old system resulted in lots of overalerting, which actually prevented them from proactively fixing errors. When missing or incorrect data was reported, engineers would have to dig through a pile of notifications to find the error in question and fix it.
Alerting goes hand-in-hand with data observability. There’s a delicate balance between a system that endures silent failures and one that is disruptive when nothing is actually broken, a classic boy-who-cried-wolf scenario.
For example, I once worked on an Airflow pipeline that always succeeded on the second run. The first failure triggered an email alert, but I ignored Airflow errors in my inbox because I knew they would recover.
Problem is, when something would actually break, I wasn’t paying the attention I needed to – going in, playing data detective, and fixing what was broken.
Wistia’s new pipeline is designed to only alert people when an error is important enough to warrant someone to go into the UI and figure out what went wrong.
Failures trigger email alerts that contain all the details of the error. Another message is sent when the system recovers.
“Because we’re using the API, it’s very easy for us to pull back all the information about our syncs – how many records failed, how many records succeeded, how many records tried to sync – and we can plug that information into our internal monitoring systems,” Chris said. “That’s very powerful for us.”
Interoperability is so important in optimizing how your company uses data. It gives a salesperson the information they need at their fingertips without having to learn SQL or go into three different apps. It gives a data engineer a window into what’s happening in the pipeline.
According to Chris, the next place Wistia plans to leverage Census is in its marketing automation platform, HubSpot. Because the HubSpot integration and the Salesforce integration were written at different times by different engineers, he said, there are some inconsistencies in data and definitions.
“When you have the hub-and-spoke model, you have a single source of truth,” he said. “When you have the same dbt models backing the sync to Salesforce as you have backing the sync to HubSpot you can be totally confident the information is going to match. We’re really excited about where we are now and where we’re going shortly.”
All this to say that a hub-and-spoke model operationalized by reverse ETL has helped companies like Wistia dramatically improve their pipelines and free up their data teams to do more than just wrestle with custom integrations all day.
If you’re looking for ways to improve how you handle your data (and how the people in your org use that data), check out The Operational Analytics Club, a community dedicated to helping data practitioners sharpen their skills and learn from each other. I’m frequently hanging out in the community and would love to talk data with you. 🙌