































✨ This interview is part of our Select Stars series, highlighting use cases of data and ops practitioners driving more impact by activating data in their business.
Clockwise is a time orchestration platform that helps busy professionals manage their calendars to create more time in their days. Users can entrust certain meetings to Clockwise, and Clockwise will then use AI to find the best possible times for team members to meet. In doing so, the tool helps resolve conflicts, creates more focus time in calendars, and ultimately improves team collaboration and productivity.
Michael Tappel, Business Operations Manager at Clockwise often collaborates with the data team. Michael is intent on helping team members across the organization gain better access to information so they’re well-equipped to do their jobs.
In this interview, Michael explains how data functions at the company and shares a specific use case of how Clockwise syncs onboarding segmentation data to HubSpot.
How are the data teams structured at Clockwise?
We have a central data team made up of data scientists, data engineers, and data analysts. They're responsible for creating our core data infrastructure and curating all of the product, billing, and financial data into our data warehouse so that it can be used by other teams across the organization.
At Clockwise, the business operations team is basically an extension of that core data team, specifically because we create reports that pertain to financial and operational data. We also do a lot of data analysis that supports our go-to-market teams. The data we analyze and reports we create support marketing, sales, customer success, and customer support.
How does the business operations team collaborate with the centralized data team?
The biggest point of collaboration comes when we need to onboard new data types. For example, our sales team wanted better segmentation to support their lead generation strategy. As part of this effort, they wanted to onboard a lead enrichment vendor that would provide more information about our users.
Once this need was identified, the business operations team became the champion to procure this vendor, and then we worked with the data team to set up the ingestion processes for this data into our data warehouse. Then, we used Census to take the data from our data warehouse and send it to our CRM platforms so that our go-to-market teams can make use of it. For instance, the sales team has used this data to create more refined customer segments and a smarter lead-scoring engine.
We also collaborate with Data any time that a go-to-market team wants more complex metrics readily available. For example, our teams wanted lead scoring and customer health scoring powered by a predictive engine. To make these metrics available, the business operations team worked with the data team to create that engine, then used Census to feed those scores and metrics to the internal end users.
Can you describe your data stack?
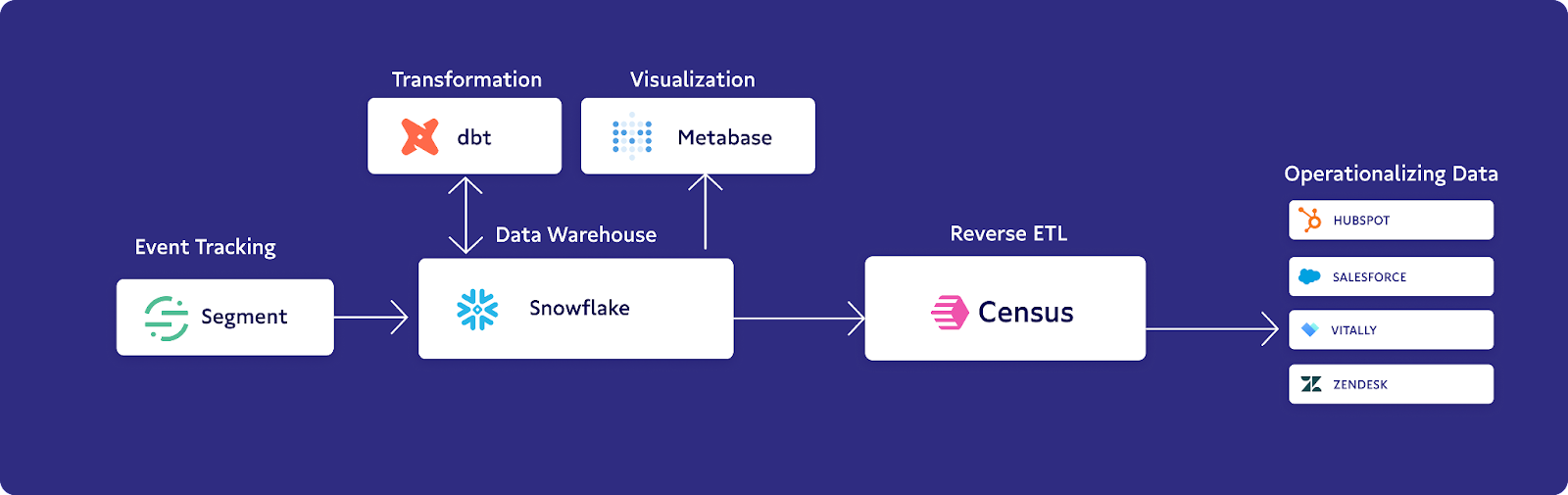
We use Snowflake for our data warehouse, and we perform transformations of our data using dbt within Snowflake.
On top of Snowflake, we have a data visualization platform called Metabase, which functions as our consumer platform and analytics platform for data. Our executive and go-to-market teams reference charts, dashboards, and analytics within Metabase.
Census plays an important role, as well, hooking up directly to Snowflake, and then sending data primarily to our four CRM tools which are used by the different go-to-market teams. HubSpot is used by our marketing team, Salesforce is used by our sales team, Vitally is used by our customer success team, and Zendesk is used by our support team for ticketing.
What are some of the challenges you’ve faced when it comes to accessing data?
When I first joined the team it was clear that our customer-facing teams were not equipped with real-time product engagement and usage data within the tools they were regularly using.
For example, our first salesperson was looking to identify champions that she could reach out to and potentially try to locate a buyer among these organizations. It was really hard for her to do that without having information on which users at a given organization were using Clockwise the most and getting the most value.
We had worked with a member of our engineering team to promote product metrics directly to CRM and other tools via an API endpoint. But of course, engineers have a whole backlog of other projects they're working on, often prioritized above go-to-market and business needs. And so, it would often take us weeks after we would request a new metric from Product for the engineer to have time to promote that into a tool like HubSpot. In that waiting period, our go-to-market teams would be flying blind.
We were able to overcome this by setting up a reverse ETL tool like Census to promote those product-related usage and engagement data into HubSpot (our sales CRM at the time) so our sales team could better identify product champions.
Show & Tell: Syncing product segmentation data to HubSpot to drive more personalized onboarding flows
Our product growth team was launching an experiment to test whether segmenting users during their onboarding experience would lead to increased product engagement and growth over time among our customers. They developed an experiment within the product that would send users down different paths in their onboarding.
The go-to-market teams wanted to know which users went down which onboarding paths and then to be able to send targeted communications, particularly emails, to those users based on their paths. We needed to create product-generated tags in our data around the onboarding path, then send these tags to HubSpot, which is our marketing team’s system of record, so that the team could take action and send the right emails to the right users.
The onboarding paths are dictated by how a user enters the product– whether they’re coming from a certain landing page or a jobs-to-be-done survey. We set up a model that pulls the onboarding source for every individual user, which pulls data from Snowflake and sends it to HubSpot, mapping to their email address as the identifier. Snowflake essentially sends the onboarding source and the date the onboarding began.
Thanks to this model, you can see a list of contacts within HubSpot based on certain segments. Based on the onboarding source, automated workflows are triggered within HubSpot that enroll users in specific marketing email sequences.
What advice would you give to those using data to serve go-to-market teams?
Make sure that the needs of the end user, the individual consuming the data, are clearly defined for the team who will be generating that data.
For instance, if a marketing team member wants to segment users into five different groups based on five different onboarding paths, make sure that the team who's responsible for generating that data is thinking about it in the same way as the marketing team member and is creating a data schema that marketing can actually use for the segmenting they want.
If you neglect to communicate clearly to the team responsible for creating the data, it requires a little bit of back and forth, which takes unnecessary time and creates a clunky process.
👉 Learn more about how Clockwise uses Census here.
⭐ Want to be featured in our next Select Stars profile? Apply here and we’ll be in touch soon!