































Our previous blog post got a lot attention, and people asked us how to implement sparklines when they don't have access to an external data source like a warehouse or if the data is coming from another app, like Marketo's Score for example.
I'm pleased to say you can achieve a similar result by relying on the ISCHANGED() and PRIORDATA() functions in the Salesforce Process Builder. 🎉
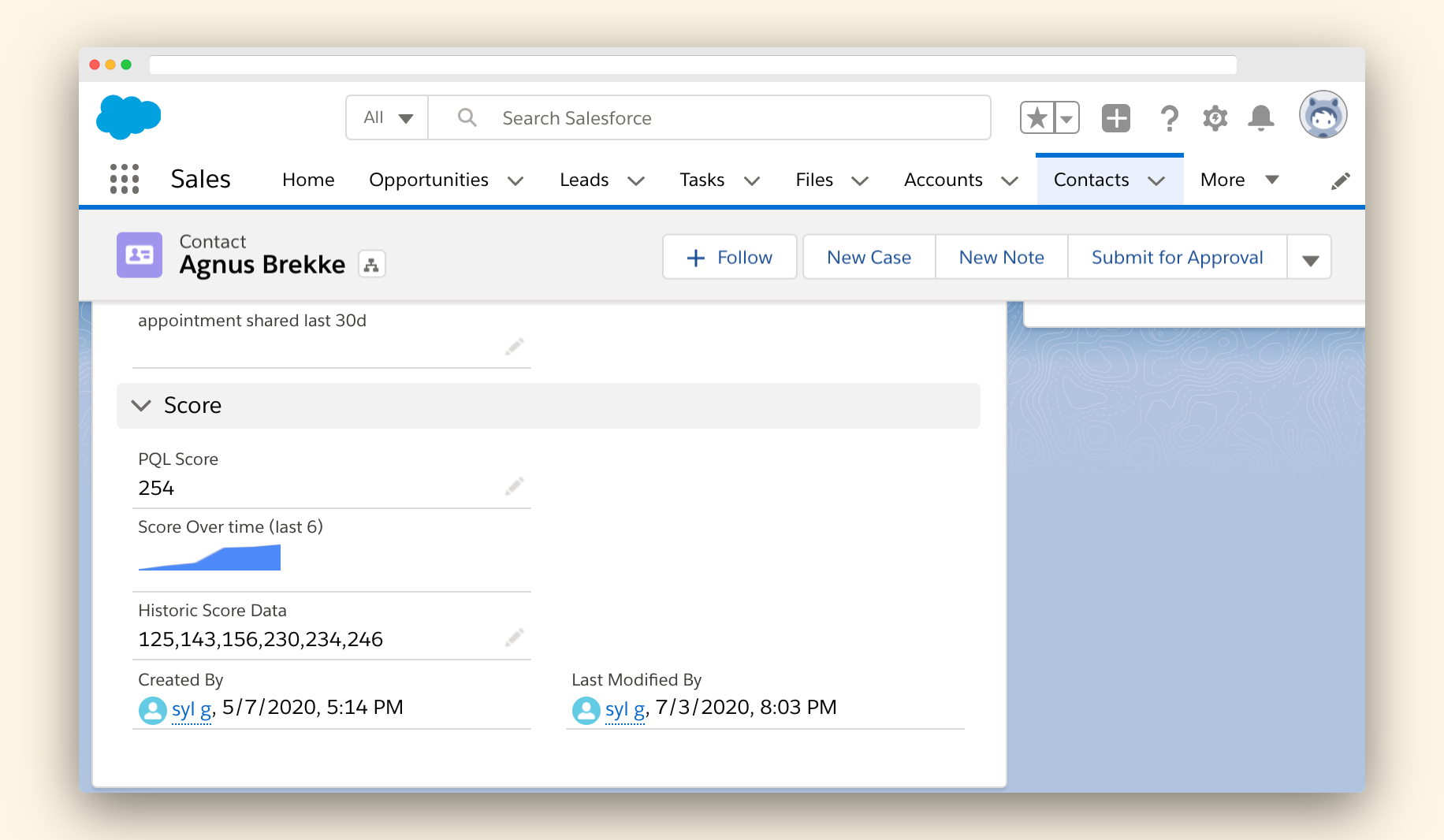
💡 Please be aware, you won't be able to use historical data to populate the graph. It will only work for future data. This is the main drawback of not using an external data warehouse as the source of the data.
How to set it up
In our example, we will create a Process that automatically stores the previous value of a field (PQL_Score__c) in another text field (historic_score_data__c). We will only store the last six values. Finally, we will use a formula field and the IMAGE() function to display a sparkline. 📈
1. Trigger the process when the field changes
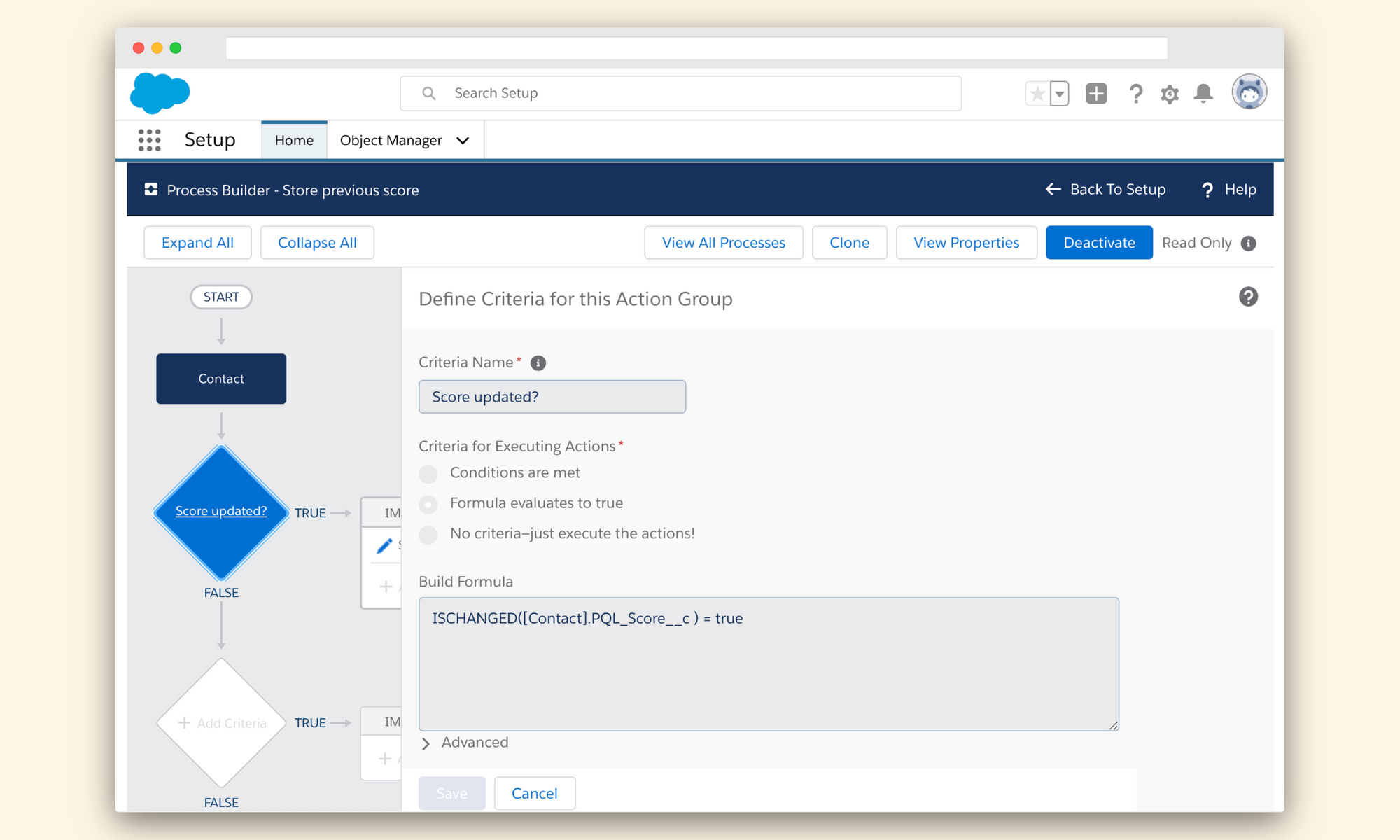
First, you need to create a process builder that will trigger every time the field gets updated. In our example, we are using a PQL Score field on the Contact Object.
We will then create a condition called "Score Updated?" using a formula to check if it needs to continue.
ISCHANGED([Contact].PQL_Score__c ) = true💡 ISCHANGED() is a powerful function you can use to check if a field was updated. You can learn more about it in Salesforce's documentation
2. Store the previous score value in another field
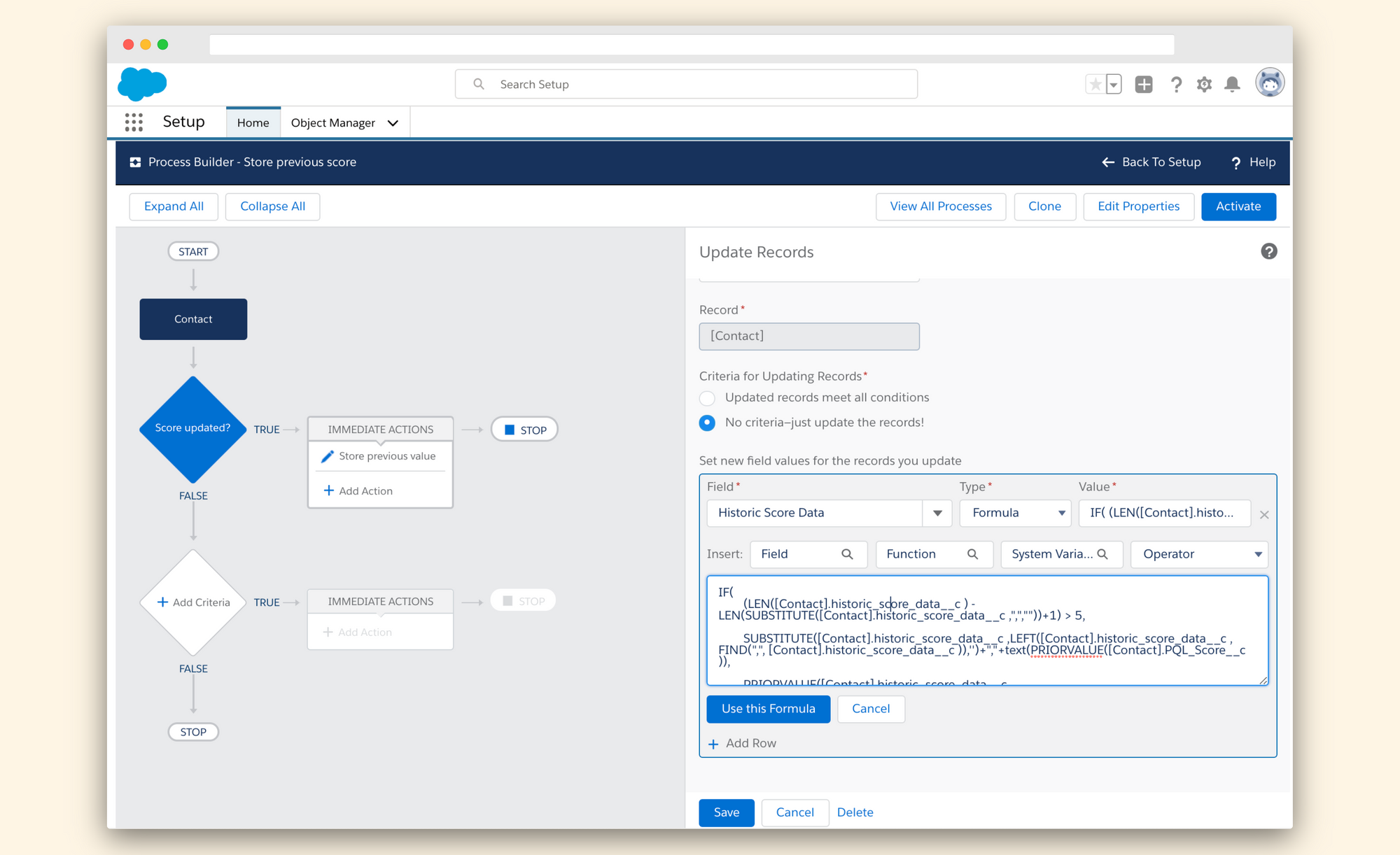
We will then add an immediate action on the Contact Object to store the prior value in our Historic Score Data field by using the following formula:
IF(
/* Check if there are already 6 values in the field */
(LEN([Contact].historic_score_data__c ) - LEN(SUBSTITUTE([Contact].historic_score_data__c ,",",""))+1) > 5,
/* If there are 6 values, remove the oldest one... and append the new score */
SUBSTITUTE([Contact].historic_score_data__c ,LEFT([Contact].historic_score_data__c , FIND(",", [Contact].historic_score_data__c )),'')+","+text(PRIORVALUE([Contact].PQL_Score__c )),
/* If we have less than 6 values, append the latest score */
PRIORVALUE([Contact].historic_score_data__c )+","+text(PRIORVALUE([Contact].PQL_Score__c ))
)💡PRIORVALUE() is a super helpful function that lets you get the previous field value during a process or a workflow. You can read more about this function in the documentation.
I would love to hear from you if you have any ideas on making the formula prettier or shorter. Ping us on Twitter 🐦
3. Display a sparkline in a field on our Contact
Here we can follow the instructions from our previous post.
We will be using Quickchart to generate the sparkline by using the IMAGE() function in a formula field to render the chart.
In our example, we have a score_progression__c formula field where we will display the sparkline. The formula is straightforward.
IMAGE( 'https://quickchart.io/chart?bkg=white&c={ type: "sparkline", data: { datasets: [{ data: [' + historic_score_data__c + '] }] }}', 'score progression', 20, 100)Congratulations, you now have sparklines in a Salesforce object that automatically chart the changes in a field value over time. 🎊
Let us know how you are using sparklines in Salesforce; we would love to hear your use cases!