































Consistent, accurate data is the foundation of your operational success as a business. For your marketing to make sense, you need a clear (and accurate) picture of your buyer personas. For your sales team to be successful, they need up-to-date records of which companies you’ve already spoken with, who is interested in what services, and who the point of contact is for each lead.
So how do you ensure that your data is accurate and accessible to everyone who needs it? You choose the best data synchronization architecture. In this article, we’re going to show you why the hub-and-spoke method will prevail over point-to-point data synchronization every time, with a five-round fight.
But first, let’s review what each method looks like. Point-to-point integration is an architectural system in which each individual point (in this case, app or software) is connected to every other point it needs to share information with.
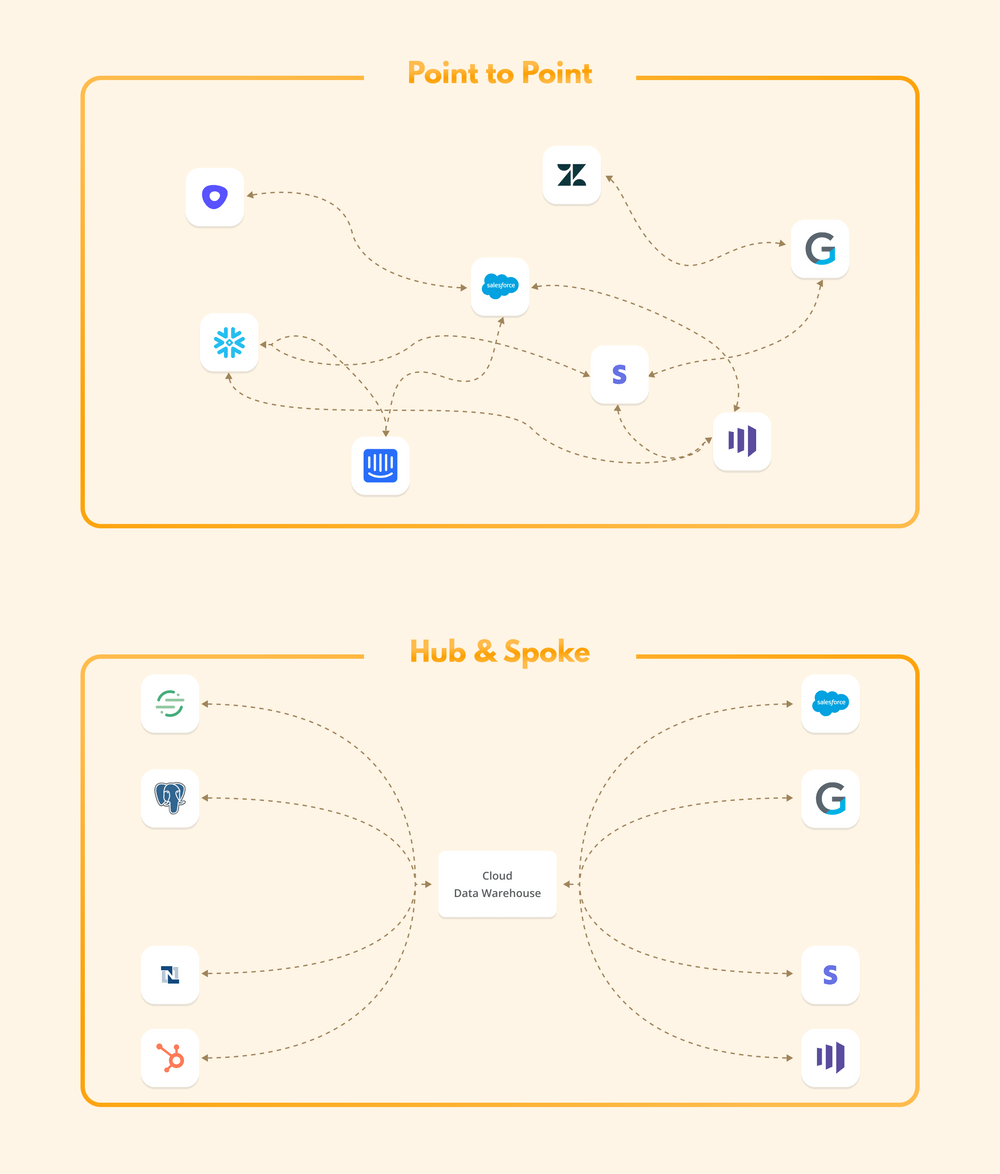
The hub-and-spoke system, on the other hand, is laid out so that one central hub connects to all of the spokes. Now, let’s dive into how our two contenders match up:
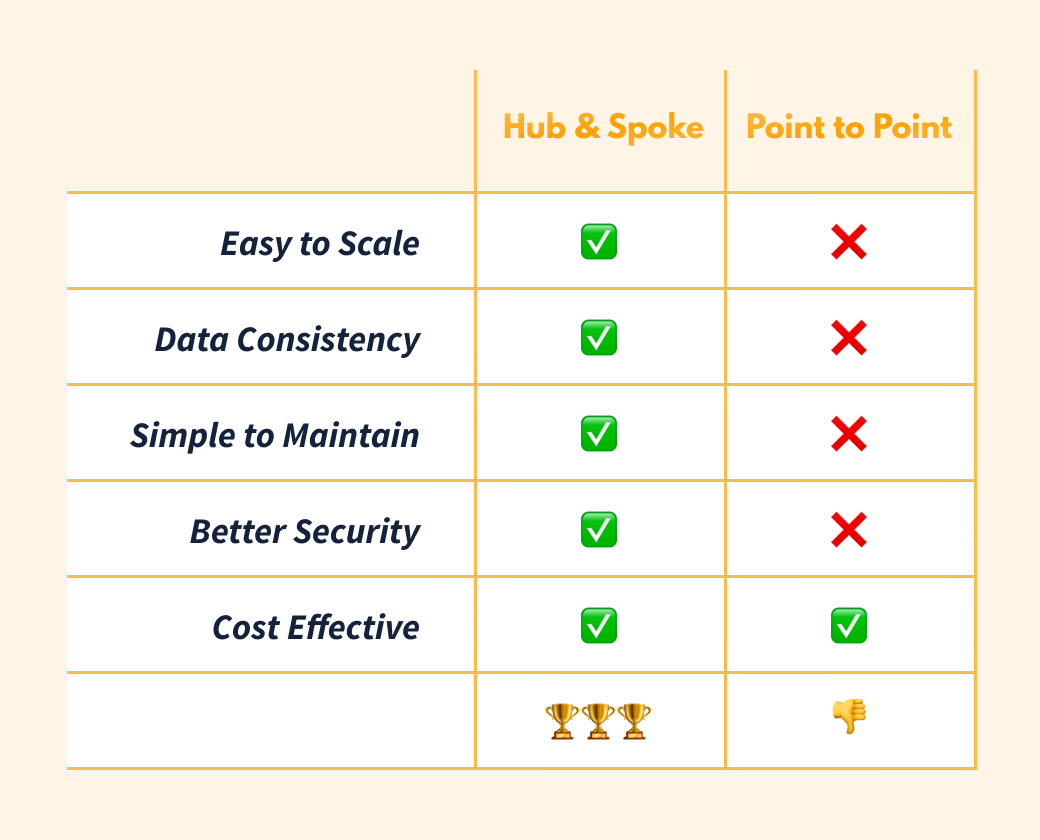
Round 1: Which Scales More Easily?
Point-to-point data synchronization is messy, which makes scaling a serious challenge. When you add a new app to your business, you may initially need to connect it to only one other app. But as your business grows and your teams get larger, you’ll eventually want to connect your tech stack so that each team has access to as much information as possible, so they are empowered to make the best decisions for your business’s success.
But the point-to-point method requires exponentially more connections (or integrations) to achieve a fully connected data and tech stack. In fact, the number of connections grows by the square of the number of apps. So, if you have eight apps, you may need as many as 64 connections to achieve full data synchronicity—and a fully scalable business.
As Chris Tiernan, senior director of software engineering for IT business applications at Splunk, wrote:
“Many organizations have learned the hard way, an infrastructure based on P2P integration quickly becomes unmanageable, brittle, and damaging to both the IT budget and the organization’s ability to meet current and changing business needs.”
The hub-and-spoke system, on the other hand, requires only one connection (to the hub) for each app. So no matter how many apps your business needs as you grow, your integration and setup time won’t go through the roof. If we use the same example of a business with eight apps, the maximum number of connections required for a fully synchronized data and tech stack is only eight. That’s 56 fewer integrations to set up and maintain.
Round 2: Which Synchronizes More Accurately?
When it comes to data consistency, point-to-point synchronization falls short again. Disparate apps within a point-to-point system often wind up with conflicting data because there is no one central point, or hub, that determines which information is the most up-to-date or accurate. Once this happens, it’s a nightmare to figure out which data set is correct.
Data quality is a huge concern for businesses of all sizes. You don't want your teams making strategic decisions or developing business processes based on bad information. If Salesforce, for instance, shows 160 active clients but Marketo only shows 130, your marketing team could be tailoring ad campaigns based on a misrepresented user base. If your data transfer between Salesforce and SalesLoft is broken, you may wind up with two sales reps who waste time reaching out to the same company. Or, worse yet, one of your sales reps could cold call an existing client and unintentionally put that account at risk.
Point-to-point data synchronization also makes you more vulnerable to data stomping—where information submitted by one app is overwritten and completely deleted by another unintentionally. Say, for instance, you have two employees working on the same account. Each employee adds notes to your client’s file at the same time, one in your CRM tool and one in your sales engagement tool. If you’re using a point-to-point integration to share information across this software, you risk losing part or all of that data as the two apps struggle to sort out which information is the most current. One set of data may completely overwrite the other, or you may wind up with an unintelligible jumble of both sets of notes. And if you don’t catch that error right away, valuable client notes may be lost forever.
Luckily, our second contender solves this problem. It’s a lot easier to ensure data consistency across your company with the hub-and-spoke model since all apps have the same source of truth—your data warehouse or hub.
Think of the hub as the brain of your operation and the spokes as your five senses. If you smell smoke at the same time you see someone grilling burgers, your brain will know which information should supersede the other and determine that there is no immediate risk.
Round 3: Which Is Easier to Maintain?
Spoiler alert: point-to-point is going to lose this round, too. The more API integrations you have, the harder your system is to maintain. In Tray.io’s guide, What are APIs and API Integrations, they explain that:
“trying to get your data to sync up [using API integrations] usually requires error-prone manual work, jury-rigged workarounds, or filing a ticket for IT support.”
The image below is an actual diagram of GitLab’s point-to-point data infrastructure in 2020.
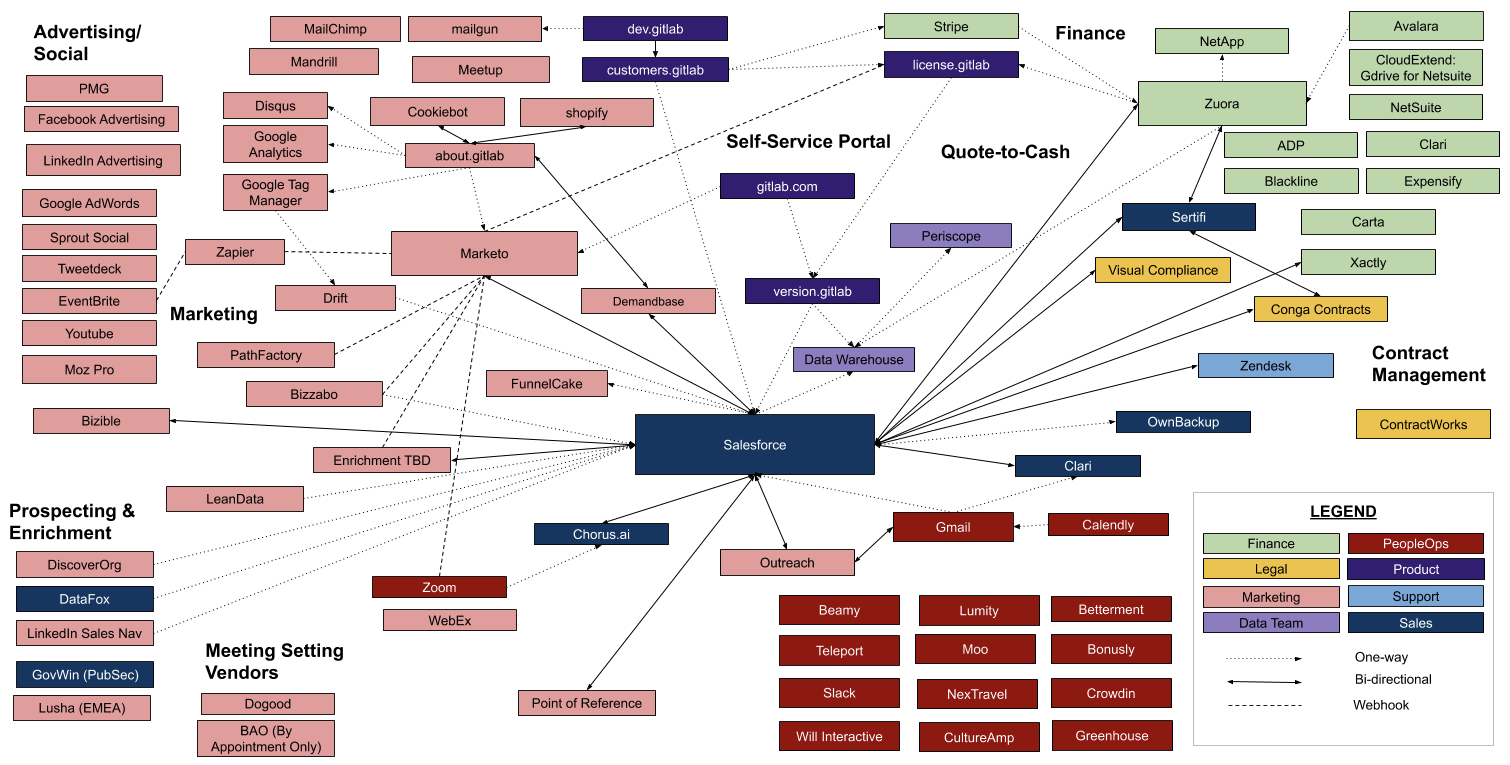
A web with this many lines, or API integrations and webhooks, requires a lot of maintenance. Whenever one of those apps or programs is updated, you run the risk of the connecting API integrations failing. So, for GitLab, based on this diagram, a Marketo update could mean eight different integrations will need to be fixed. If Salesforce updates, 26 integrations may need recoding or fixing.
Hub-and-spoke is—you guessed it—easier to maintain because each application your team requires only needs to be integrated with your hub instead of every other app in your tech stack. If one of those apps is updated to a new version, you don’t need to worry about recoding five or more connections to ensure it keeps syncing with all of your other apps. The same thing is true if you want to add a new app.
Hub-and-spoke also makes it easier to clean up or transform data and have those adjustments reflected everywhere that data appears. Say, for instance, that you want to add a customer persona to your target audience divisions. You only need to do this once for it to be reflected across your entire tech stack (in your marketing, sales, and other apps) rather than adding it to each app individually and then having to check the integrations to make sure all of your coding is compatible.
Round 4: Which Is More Secure?
The point-to-point model poses a serious security risk, whether you’re using it for data synchronization or even network architecting. Doug Guth, managing architect at Core BTS, explained that “when you go to a point to point [system]... security is next to impossible. Your visibility of who’s accessing what and where and how, what’s flowing where and how... it’s difficult at best, if not impossible to do.
”When it comes to data synchronization specifically, point-to-point systems require numerous API user accounts. And as Tiernan wrote:
“In general security terms, the more API user accounts available, the more exposure to risk the company has for security breaches.”
In addition, if you’re synchronizing information with third-party vendors from app to app using various APIs, it’s very hard to protect confidentiality and maintain compliance. You can't create clear and consistent access control lists if your data is spread across 30 different apps.
Hub-and-spoke, on the other hand, provides a sort of vault, in the form of your hub, that allows you to protect and limit what information is shared, with which apps or vendors, and how that information is shared. Using the hub-and-spoke model, you can define permissions based on data and people, rather than apps, which ensures more reliable and trustworthy data.
Hub-and-spoke data synchronization seriously limits your exposure to data breaches. Ben Morley, director of product management at Ellucian, wrote, “The bottom line is that it’s [hub and spoke] a more secure approach because you're reducing the number of factors of attack.”
Round 5: Which Is More Affordable?
Those of you rooting for the underdog, here’s where point-to-point throws a punch: on an individual project level, point-to-point data synchronization can be cheaper, which is why you’ll still find it in use.
But zoom out and you’ll quickly see that the total operational cost of managing a point-to-point infrastructure can quickly become cost-prohibitive, even for small businesses with only a few apps. Gartner Research recently published a report on modern data management where they referred to point-to-point integrations as “haphazard reactive measures” that cause costs to “escalate uncontrollably.
”It’s a common misconception that hub-and-spoke data synchronization comes with a large upfront cost. Historically, there was truth to this belief, but this is no longer the case thanks to data warehouses like Snowflake and BigQuery with flexible pricing structures. BigQuery’s pay-as-you-go subscription is just $5 per TB per month. Once you’ve got your data storage set up, you can use synchronization tools such as Fivetran and Census to easily move information to and from all of your apps. And each of these software offers a free trial.
The Modern Tech Stack Champion
The hub-and-spoke model is the clear champion of data synchronization. And we designed Census to make this winning system easily accessible for businesses of all sizes. Forget about writing and maintaining API integrations for every new app your business needs. Schedule a demo to learn how Census streamlines the hub-and-spoke system and automatically synchronizes your data warehouse with Marketo, Zendesk, and all of your other apps.