































If there’s one lesson you walk away from this article with, it’s this: You (the data team) already have datasets that can drive revenue and support marketing initiatives. But they’re sitting unused in your data warehouse.
It’s just a matter of unlocking that data from the warehouse and activating it in the tools that actually send emails, serve ads, send flyers to your mailbox, etc.
This topic was the focus of my afternoon workshop at ConCensus 2023. In a three-part series summarizing this workshop, I’ll explain how to drive revenue with three HubSpot marketing use cases:
- Right person by segmenting users based on trial activity (inactive v active) 👈 We’re here!
- Right message by personalizing a free trial report with usage data
- Right time by emailing users about upgrading just after they attempt a paid feature
You can think of it as the data person’s cheat sheet to email marketing personalization. I want to show you exactly how your data can make a difference in a marketing system like Hubspot. No weasel words. No Gartner reports. Just practical examples of connecting the world you know (data) to a world we don’t frequent every day (marketing).
Throughout this series, we’ll think of our examples through the lens of an imaginary business called Marker, a visual design product used for whiteboarding ideas (and sharing those canvases with other users).
But before we dive into the nitty gritty of our right-person use case - let’s talk about why the marketing team relies on your data insights so much.
Note: If you’re a marketer reading this who wants to build campaigns off of active vs. inactive user segments, send your data person this article.
The holy grail of modern marketing: Right person, right message, right time
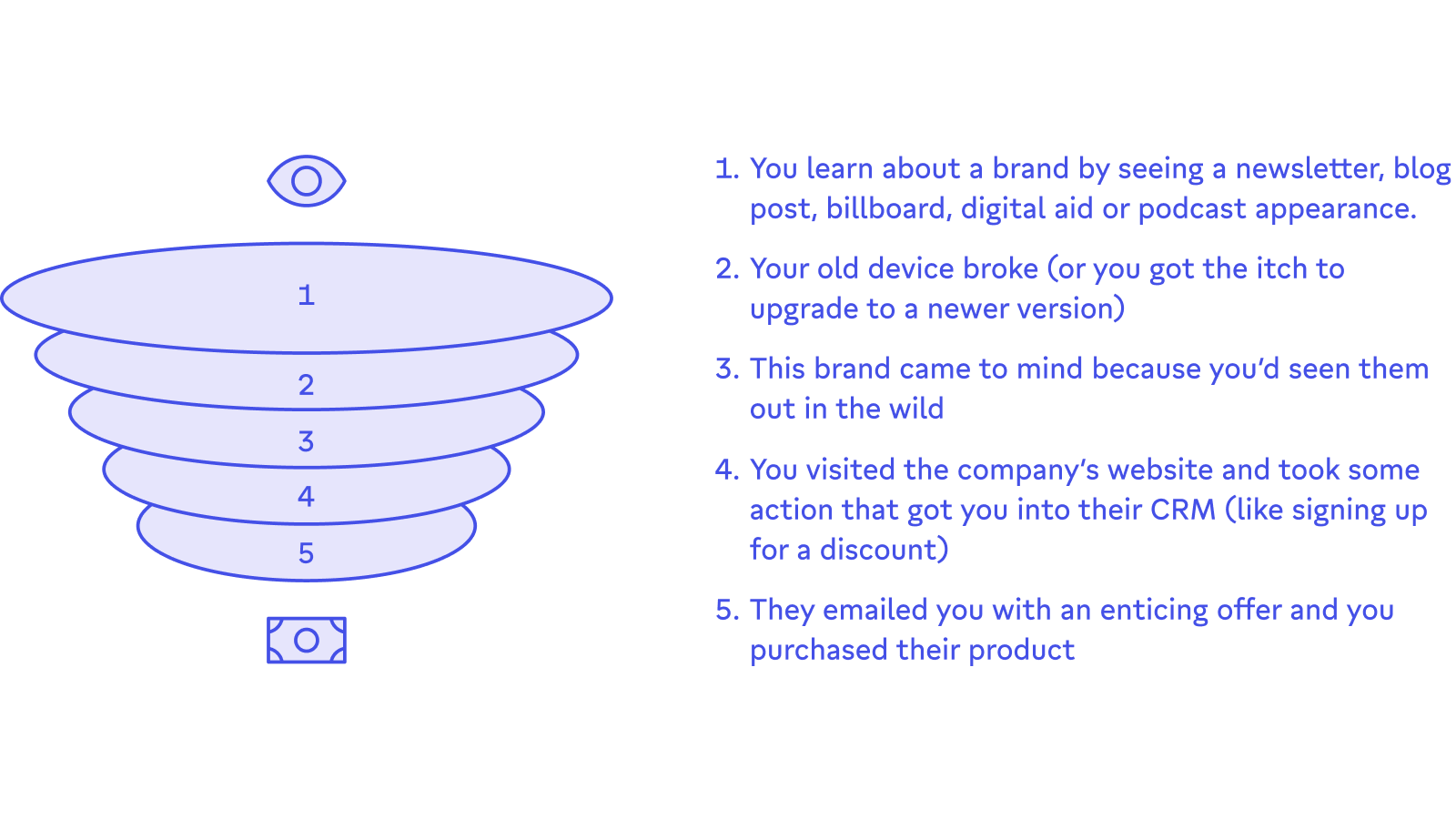
Think about the last time you set out to buy a new product (doesn’t have to be software, it could be a fancy component of your home stereo system or a new set of headphones, too). Your buying process likely looked something like this:
- You learn about a brand by seeing a newsletter, blog post, billboard, digital ad, or podcast appearance.
- Your old device broke (or you got the itch to upgrade to a newer version)
- This brand came to mind because you’d seen them out in the wild
- You visited the company’s website and took some action that got you into their CRM (like signing up for a discount)
- They emailed you with an enticing offer and you purchased their product
The early steps of this marketing process created stickiness in your mind by priming you with messaging about the brand - even when they didn’t want you to buy right now. Then, when you were ready to purchase, they were able to reach you with more direct prompting. It didn’t feel pushy or spammy because you completed actions that showed them you were ready to buy a new device.
 |
This is the “right person, right message, right time” framework in action, and it relies on data about you (and users like you) to work.
We can see this in the wild at companies like Canva, a graphic design platform for the low-lift creation of assets like social media posts and infographics. The Canva team collects a ton of data about their users’ product behavior, which then informs the kind of information they send to their user base (and the timing of that information). By merging their user and product usage data together in their CRM, they can personalize messaging to millions of users at once.
The same is true for you (even if you’re not, yet, at millions of users). When you help your marketing team reach the right people, with the right message, at just the right moment in their buying journey, you can turn the data team and the warehouse into a powerful revenue driver for your company.
This doesn’t just make you new friends in the marketing department (they will love you) but drives three key benefits:
- Impacts revenue directly, which is especially important in our “show me the money” era
- Justifies spend on data team personnel and tooling, which helps you get the resourcing you need to scale up as the business grows
- Gives your data team a seat at the decision-making table as a strategic partner, not a service for others to request at a whim
As we explore three HubSpot use cases for marketing, I’ll explain how you stitch together your user and product event data to drive revenue from HubSpot (and other CRMs like it).
What kinds of data does HubSpot need for active vs. inactive user segmentation?
First, a definition. HubSpot is a customer relationship management (CRM) platform that helps marketing teams email customers at relevant times.
To do this, HubSpot leverages three types of data points:
- People (“Contacts” in Hubspot-speak) and attributes about them
- Lists of people
- Actions that people have taken (events)
For the use case in this article and our fictitious company Marker, HubSpot Lists are the most important data point we care about.
To send emails to the “right people,” we’ll first need to create segments of people based on the characteristics we care about (free vs. paid account plans, product usage, etc.). In HubSpot, these segments are called Lists. When setting up an email campaign, we can email different Contacts based on their membership to these Lists.
There’s real revenue in automation and accuracy for HubSpot Lists. The “right people” yesterday may be the “wrong people” today, which means we should remove folks from your Lists of Contacts when they no longer fit our criteria. In addition, we need to source these groups of people from the best, most reliably updated source of truth for our business. For most companies, this source of truth is the data warehouse.
A practical example: Identifying active users in a free trial and encouraging them to upgrade
Now that we’ve set the scene around why reaching the right people matters so much in marketing let’s look at a hands-on example: segmenting active and inactive users in a free trial to encourage upgrades.
As a reminder, we’re using our example company, Marker, for this walkthrough. Their data stack includes HubSpot, Snowflake, and Census.
Note: You could also accomplish this task by downloading a CSV from Snowflake and uploading it to HubSpot (for a one-off email) or building a data pipeline yourself… but you’d still have to accomplish the key bolded steps below. To save yourself (and your marketing stakeholders) some time and headache, I’d recommend using a production-grade Data Activation platform like Census (and not just ‘cause I work here).
Marker has a 14-day free trial that gives users access to a wide suite of features, including some paid options. They’re looking to send folks who have actively used the product but haven’t upgraded by the 14-day mark an email to entice them to join their paid plan.
To do this, we’ll go through 5 steps:
- Create our email template and list in HubSpot
- Create our segmented list of relevant users in Census
- Sync our segmented list of users from Snowflake to HubSpot using Census
- Create a sync schedule in Census to automate this process in the future
- Send our shiny new product usage emails to all the right people 🙌
If you prefer, here is the video walkthrough of the use case.
Step one: Set up HubSpot emails and lists
First, we will log into our HubSpot account and create the email we’d like to send our active trial users. We won’t have a list to send it to yet, but go ahead and set up the copy and customized variables (e.g., first name) as you’d like.
Next - we’ll create an empty list that we’ll later populate with the users who meet our activity criteria.
That’s it! Time to Jump over to Census.
Step two: Create our user segment in Census
Now it’s time to get to the meat of our project: Creating our segment of active trial users in Census to sync over to HubSpot.
First, ensure you’ve successfully connected HubSpot and Snowflake to your Census account. Then, go into the Audience Hub and tell Census what users and events we use from Snowflake (joined at the user table by the user ID).
Once our source, destination, and tables are connected and selected, we can create our active user segment in the Census Audience Hub.
When viewing our initial user data without any filters, we’ll see the total count of all users available in Snowflake. We want to target a subset of these users, so we’ll apply the following filters:
- Filter for users on the free plan
- Filter out inactive users (in our case, anyone who has created less than two canvases and shared less than two canvases)
Then, hit refresh. We can now see an updated user total for our filtered segment. After you confirm it’s correct, go ahead and hit save.
Step three: Stand up our Census > HubSpot sync
Armed with our shiny new segment of active trial users, it’s time to set up our sync from Census to HubSpot (bump over to the “sync” tab inside your segment view).
We’ll go ahead and sync our new segment to the contact & static list object in HubSpot and add folks by email. Then, we’ll choose which list to add our contacts to (you can choose a new or existing one, as I have in the example video).
Now - we want to ensure that if a user no longer meets our segment criteria (say, they love the Marker product so much they decide to upgrade on their own), they’re removed from our list. They’re no longer the “right person.” As part of configuring your sync, indicate that if the record is removed from our source data, it should be removed from our list in HubSpot.
Then, click “Next” and “Run Sync.”
Step four: Automate your future work with sync scheduling
The best part about using modern data tooling is that it makes your life easier (and cuts down on the number of jobs you have to think about running). Case in point: Sync scheduling.
Let’s set up a recurring sync schedule so that when folks are added to or dropped from our segment, our HubSpot list stays in…sync…with our source data.
To do this, open the configuration tab inside your new sync and set your schedule. In Marker’s case, we’ll set up a daily sync at 9 am ET.
Step five: View our data in HubSpot and celebrate 🍾
OK - now, for the best part, let’s check out the fruits of our labor in HubSpot.
When we view the list we initially created as empty, we can now see our segmented users there instead. From here, we can easily attach that list to our amazing, enticing product email and shoot it off to the exact right group of people who need to see it. 🙌
Give yourself a high-five - you just made your trial users more likely to upgrade to a paid account.
Your most valuable marketing segments are in your data warehouse. Unleash them to drive revenue.
Now that you’ve set up your first HubSpot sync - the marketing world is your oyster.
By demonstrating your ability to support marketing initiatives, you’re positioning your work directly next to revenue and the business goals your stakeholders care most about.
Remember: You have the means and the datasets already at your disposal; you just need to activate it.
Where should you go from here? Talk frequently with your marketing team to drive experimentation, help them uncover data trends about their campaign performance, and discover new ways you can connect your work with revenue levers like email and lifecycle marketing.
And, if you’re ready to superpower your data stack, check out Census (or drop me a line at jeff@getcensus.com to learn about more marketing use cases you can power with your data).
Want to dive deeper into driving revenue with HubSpot use cases? Check out my 2023 hands-on workshop.