































In this article, you'll learn an effective way to get started as a first-time Census user. Specifically, I’ll go over:
- How to learn the “Who”, “What” and “Why” of Census
- How to learn the “how” of Census (meta, I know)
In 3rd grade, I chose “How To Start a Fire Without Matches” as my science fair project. I was so excited to show my classmates my skills (and hopefully not burn the building down). My teacher gave me the necessary tools (bow, spindle, fireboard, and notched wood) and an instruction manual. I ran home that day and immediately put the tools to the test.
To nobody’s surprise, I failed miserably.
I burned my foot, blistered my hands, and got nowhere near sparking a flame. When my teacher discovered I hadn’t made any progress, she kindly said “Well, did you read the directions I gave you?” (Hint: I hadn't.)
The next day, I sat down to read the instructions. It gave me the confidence and know-how to start my fire. Later that evening, I picked up my tools, created an ember, gave it some oxygen, and voila, I started a fire!
Fast forward two decades, I made a similar mistake: I tried to get started learning Census by going all-in without an instruction manual. I did too many Google searches and ran into too many errors. It resulted in frustration, headache, and most of all, wasted time.
First-time Census users: I don’t want you to learn the hard way. In this article, I’ll share the starter guide I wish I had followed so you can get up and running with Census and reverse ETL quickly (and without starting too many fires). 🚀
The four w's of Census: Who, what, what not, and why
Before you dive into implementation, dedicate 20 minutes to understand the who, what, what not, and why of Census. This will help you see not just how Census helps you, individually, but how it can help your entire team and organization do more with data.
If I had followed this advice, it would have saved me five hours, no joke. The two articles below gave me a great foundation of Census. Give them a read to get an understanding of the landscape reverse ETL sits within, and what operational analytics can do beyond just solving your immediate data pain points.
- Ebook - Guide To The Modern Data Stack (15-minute read). Don’t worry! You only need to read the first 16 pages.
- Blog - What Is Operational Analytics? (5-minute read)
I’ll summarize key learnings from these articles below, but I strongly encourage you to read the articles on your own in full when you have time.
The who of Census: Meet your friendly neighborhood data nerds
Before you dive into the product-specific information, let me introduce you to the data nerds behind Census. Our leadership team firmly believes there are two types of people in the world: Filers and pilers. The former is obsessed with how information is organized, processed, and made more usable, while the latter takes a more “throw that data over there and we’ll figure it out later” kind of approach.
Guess which we are? (Hint: It’s filers, and chances are if you’re interested in reverse ETL and operational analytics, you’re a filer, too).
We’ve been growing quickly since our Series A earlier this year. We’re now a team of 26 (and counting!) across 13 states (and occasionally spanning international borders).
Our mission is to build a single source of truth about customers, accessible across the entire business. What does that mean? It means every department (engineering, marketing, sales, etc) in an organization can rely on a single source of truth to understand who their customers are and how to serve those customers best. We believe in a world where data is democratized and the data team is recognized as the powerhouse of the business.
The what (and what not) of Census: Reverse ETL and operational analytics
So what is Census? Census is a reverse ETL tool, which means we act as the bridge between your warehouse and your operational tools (and between your operations and data teams, too). As the pioneers of reverse ETL, we define this tooling class as:
Reverse ETL syncs data from a system of records like a warehouse to a system of actions like CRM, MAP, and other SaaS apps to operationalize data.
You can use our tool to extract data from your warehouse, transform it, and load it with your target applications (Hubspot, Zendesk, Salesforce, Marketo, and many more), all without custom code and engineering favors. If this sounds like we Uno reversed ETL tools like Fivetran, you’re pretty on the money.
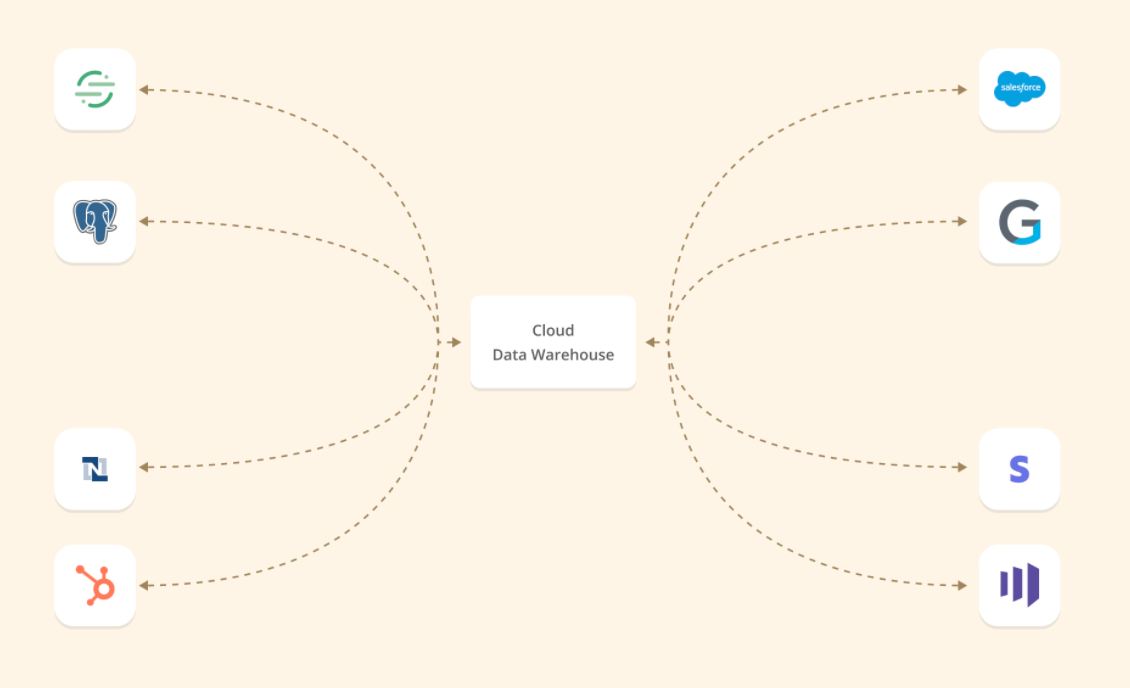
Reverse ETL is just a (very important) piece of your overall data puzzle though. Its real power lies in helping you unblock all the other awesome data tools currently in your stack (and set you up to add even more data tooling in the future when needed). The Guide To The Modern Data Stack eBook explains the “what” of Census through the lens of a nervous system of data.
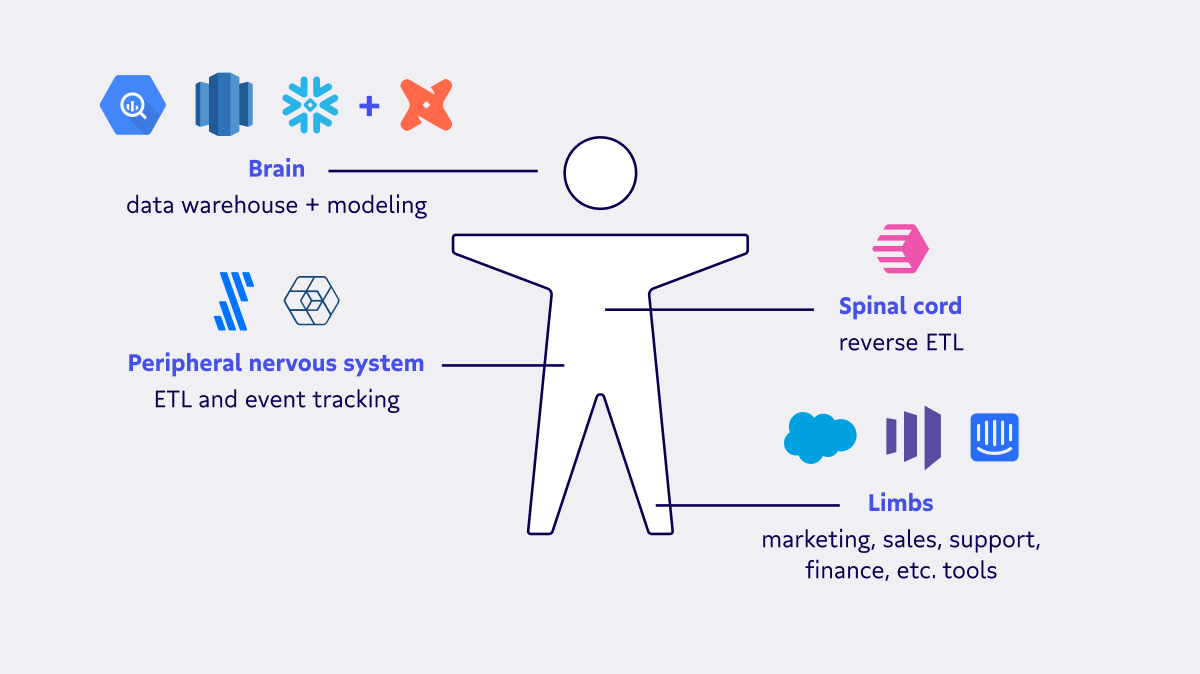
Here’s the TL;DR.
- The data warehouse and modeling tools are the brain of your data nervous system. It processes, stores, and shapes all data coming into your organization.
- Reverse ETL is the spinal cord of your data nervous system. It’s the pathway for data sent by the brain to the body. 👋 That’s us, Census.
- ETL and event tracking tools are the peripheral nervous system. They allow the brain and spinal cord of your organization to send and receive data from the body.
- Operational tools used by sales, marketing, support, etc. are the body, or limbs of your data organization. These are the Hubspot, Zendesk, Salesforce, Marketo, etc. of your organization.
All four of these components depend on each other and work in unison. The operational tools ( limbs) receive data from your reverse ETL tools (spinal cord). Reverse ETL tools receive data from the data warehouse and modeling tools (brain). The data warehouse and modeling tools receive data from ETL, event tracking, and behavioral tools (peripheral nervous system).
This data stack results in strong, unified, and scalable DataOps and data usage. All your customer data, across all your SaaS applications, move in and out of your data warehouse. This means each department has a single source of truth about customers, accessible across the entire business.
However, to understand the “what” of Census, it’s also important to understand what reverse ETL isn’t.
Simply put, Census is none of the following:
- Census is not a SaaS platform that stores your company data. We believe in helping you be good stewards of your customer data, which means never storing that customer data ourselves.
- Census is not a Customer Data Platform (CDP) like Segment, Telium, Insider, or Bloomreach. It’s not limited to a small subset of data that’s only for a segment of your organization. We also have a lower threshold for sync failures (meaning higher data quality overall).
- Census is not an ETL tool like Fivetran that extracts, translates, and loads data from your SaaS application into your data warehouse.
- Census is not just another data pipeline tool. It isn’t simply moving data from point A to point B. We bridge the gap between your data team, your day-to-day SaaS tools, and the employees who use them to change not just were data goes, but how people use data everyday.
Now that you know the who behind Census and what it is (and isn’t), let’s take a look at the why of Census and reverse ETL.
The why: Unblock data (and data teams) at scale
Unblocking data at scale means that every department in your organization, and their operational tools, are utilizing fresh and consistent data to drive day-to-day decisions. It means that your data team is not only managing your data, but they are helping drive growth in your organization.
When you unblock your data and the team that serves it to your organization, you can do some pretty amazing things. Some of our favorites include:
- Sending product data from the data warehouse to Zendesk to help customer success teams prioritize tickets.
- Sending marketing data from the data warehouse to Facebook to help marketers create highly-personalized ad campaigns.
- Sending product analytics data of free trial users to Salesforce to help sales reps identify high-probability deals.
All these use cases have a similar pattern: They’re made possible with Census pulling customer data from a single source of truth (data warehouse) to the various frontline operational tools used by each department. Additionally, they make your data work for you (vs. you working to get something out of your data) to support everyday decision-making in your organization.
Beyond helping ops teams do their job better, Census saves data engineers, scientists, and analysts time, energy, and sanity. Building your own home-grown reverse ETL tool requires significant upfront hours, let alone hours and hours of maintenance down the line. Those frontline tools your operational teams rely on constantly change their APIs, which makes keeping up with new requirements and documentation a nightmare. Data teams are too highly paid and highly skilled to just be number fetchers populating BI tools with semi-fresh data and fixing broken pipelines. Reverse ETL with Census lets them focus on higher-leverage work to uplevel ops teams.
Finally, while we’re really proud of the tool that we’re built, operational analytics isn’t just about the tech. It’s about the people. The great people that work for you, the experts on our team with the industry expertise needed to help you bring your data to the next level, and the all-star combination the two halves make. When you bring reverse ETL into your stack, you’re not just adding a new tool to your tool belt, you're re-architecting your whole data blueprint to build something better.
The how of Census: Resources to get you started
Spoiler: When I say “how” I’m not referring to technical documentation. That already exists and offers you step-by-step video tutorials and written resources to help you get up and running. Plus, when you start with Census, you get access to a dedicated customer data architect (many of whom are former heads of data themselves) to help you build your warehouse-to-operational-tool syncs.
Instead, I want to focus on the process and people part of getting started with Census. After all, if your sync doesn’t actually help the stakeholders you’re creating it for do their jobs better, it’s not really reaching its true potential. Our friend Sarah Krasnik explains working with stakeholders perfectly in this piece if you want to take a deeper dive.
For now, let’s break this down into two parts: looping in stakeholders early and starting with the low-hanging data fruit.
Loop in stakeholders early and often to align on goals
If I’ve learned one thing during my first few weeks here at Census, it’s this: Reverse ETL and operational analytics aren’t just about bridging the warehouse and operational systems but bringing together the teams that rely on those tools.
Sure - you can get up and running with Census in a silo if you really want to, but you’ll struggle to realize the full scale and impact that reverse ETL can offer your business. In order to run, you have to walk over to the other side of the Data/Ops divide and collaborate.
Ops teams: Chances are you came to reverse ETL and Census looking for a way to get fresher data into your tools to run better experiments and drive better customer relationships. In order to make sure that you get the most out of our tool (and help every other customer-facing team in your company support your strategies), you need to loop in your data team early. If it’s been a second since you’ve talked to them, don’t worry. We can help (but they should be pretty stoked on the idea of less integration work and the chance to create next-gen data infrastructure). Loop them into early conversations about your data needs and the kind of data that would help you do your job better so they can better serve your team.
Data teams: Regardless of what department or team you’re working with, you need to have an open conversation (perhaps several conversations) about what data your internal customers would like to see in their operational tools. This will help you get a clear picture of the data they need to reach their individual and team KPIs. It’s important to remember you’re not the ones using the outputs of the syncs; the stakeholders and their teams are. As such, the stakeholders should make the decision of what data is synced, and where it's synced to.
Both sides should collaborate to make sure the use case is well understood and everyone knows what kinds of data should be shared. If the initial use case belongs to the marketing team, for example, the data team could ask the frontline folks what customer data they’d like to have in the CRM that isn’t currently available. From there, the data team can help them narrow in on the exact ask with questions like:
- We have product usage data of your free trial users in the data warehouse, could syncing this data with your CRM help you achieve your Q1 goals?
- We have a new tool that allows us to sync warehouse data to your sales tool. What warehouse data would you like us to bring into Zendesk so that you can better serve our customers and achieve your Q1 goals?
You likely already know how to plan projects with your stakeholders, so use this as an opportunity to refine that muscle and build a better data future together.
Go for the low-hanging fruit: Start with the use case that can make the most impact, quickly
We get it. New tool day is the best day, and you want to start using reverse ETL in every single data process you can. While I’m totally here to see all the awesome stuff you can do, I’d recommend starting small to prove value (and ensure you don’t go a little crazy during the implementation phase).
To start, work with your stakeholders to find the most urgent pain point they’re experiencing. This should be 1) immediately achievable and 2) crucial to their success.
For example: If you’re a product-led growth company testing out new free trials, you might start with sending metrics around free trial usage to your sales tool. This will help the sales team know who they should contact first, and you’re likely already sending this event data to your warehouse.
Start small. Start somewhere that will make an immediate impact for your stakeholders and build hype around what’s possible when everyone is working with the same, high-quality data. Over time, you’ll be able to solve bigger and more complex problems.
Ready to get started with reverse ETL (or need some help figuring out your first use case)? Go ahead and sign up for a demo and check out our docs to get into the nitty-gritty of the integrations you need most today. We’re excited to have you! 😊 And if you have any questions about my onboarding experience (or just wanna talk about data in general), drop me a line.