































This is an excerpt from our full ebook, the Guide to the Modern Data Stack: Operational Analytics and Reverse ETL, which dives into how reverse ETL unlocks operational analytics at scale (and makes behavioral data more actionable in the process).
We often liken the data warehouse--powered by cutting-edge modeling tools like dbt--to the brain of your organization. It’s your knowledge and decision-making hub, capable of running everything from the day-to-day vitals of your company to the high-cognition, blue-sky goals that unite all your teams.
To quote one of my favorite (human) brain and thinking experts, Daniel Kahneman, author of Thinking, Fast and Slow: “The world makes much less sense than you think. The coherence comes mostly from the way your mind works.”
Your data brain is the same way. The value isn’t in the zeros and ones themselves, but the way you can pull a story from them about the world of your product.
But, if you’re neglecting the other parts of your data nervous system, all that work your data brain does goes to waste. And the only way your teams, and the tools they use, can reach it is through a convoluted, manual set of strings that play telephone with your source of truth.
This, as you can probably gather, isn’t great. Processing between the body parts of your organization is slow, and by the time the information gets all the way out to the limbs, the data is probably stale. Even if the data going into your brain is great, your business can become dumb and laggy (no offense).
Companies--like living, breathing organisms--can only survive if they have consistent, accurate data to act on and a system that relays data to the correct endpoints.
Just like how you can’t navigate a tricky line mountain biking with bad eyesight, your company’s marketing won’t make sense without a clear picture of your ICPs. And just as you’ll singe yourself on a hot surface without real-time tactile feedback, your sales reps can burn your customer relationships without real-time contact records.
The data nervous system empowers companies to interpret information from the world of their customers and respond accordingly.
Why we liken your modern data stack to the nervous system
We get it, metaphors are tricky business and often pretty iffy because they fail to represent the true complexity of the subject they’re describing. But we’re pretty passionate about this one, and when you peel the layers back it’s easy to see how your data systems drive vital actions for your company in the same way that your biological nervous system keeps you living and breathing.
To make organic and digital systems alike work, receptor cells take signals (data) back from an environment and send them as electrical signals to the brain (warehouse + modeling) via nerve fibers (the tools within your modern data stack). If any part of this network is broken, or if the brain itself isn’t functioning with complete information, we can’t respond to stimuli (customers) effectively.
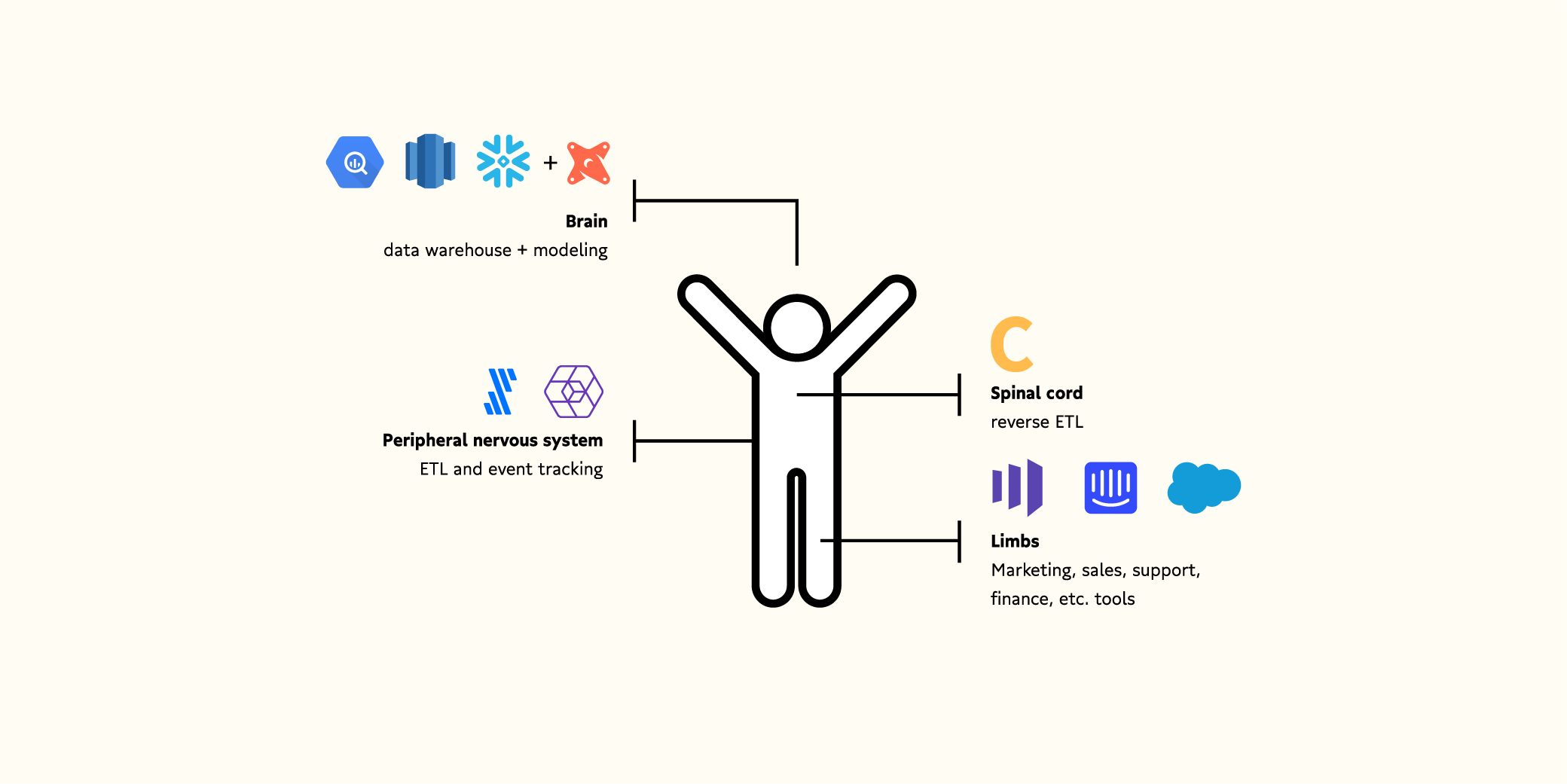
If we think of the modern data stack the nervous system to our living, maturing business, we can see each layer take on a unique role:
- The data warehouse and your data modeling tools act as the brain of your nervous system, processing, and shaping all the data coming in and out from your body into a single source of truth.
- Reverse ETL tools act as the spinal cord of your organization, not just transmitting information but contextualizing it in the right format for your brain to act on.
- Behavioral data collection and ETL tools represent the peripheral nervous system between your spinal cord and your limbs and are an integral relay system of sensory input throughout your business body.
- Marketing, sales, and support teams (and their tools) represent the limbs of your organization, interacting with the world and moving you forward.
Each part of the nervous system of your business builds on the data warehouse (and the modeling that helps it learn) as the brain to operationalize data. As your brain gets smarter and learns from the data fed into it, you can watch your business go from wobbly toddler to lanky teenager to sophisticated adult.
A brief history of the evolution of the business brain
We’ve touched on the concept of the data warehouse as the brain of your organization before, and argued that, as with the human body, the brain should sit at the center as your hub. From the hub, spokes (your applications) can connect directly to the freshest data available. This hub and spoke structure is your data nervous system.
But to understand the pivotal role of this system, we have to take a step back and recognize the brains that came before it.
Before we had the concept of the data warehouse as the brain, and the cloud computing technology that made this concept possible, companies leveraged a hive-mind of real, human knowledge to drive decisions. A single person (or a small collection of people) could act as the brain, and everyone downstream of them could execute on their knowledge.
However, as we tipped into the 21st century, companies began to rapidly grow their customer bases. The human mind couldn’t hold all the data attached to millions of customers at once, so we started to outsource to our digital counterparts piece-by-piece.
We picked ad hoc tools to supplement our saturated brains, which has quickly avalanched into a mess of data stores connected point-to-point in a complex web of dependencies.
While the spirit is right--we should leverage digital means to improve our decision making--this approach effectively tied the shoelaces of our modern, digital businesses together, tripping them up at each step. If your stack looks anything like the example below, you probably know the feeling.
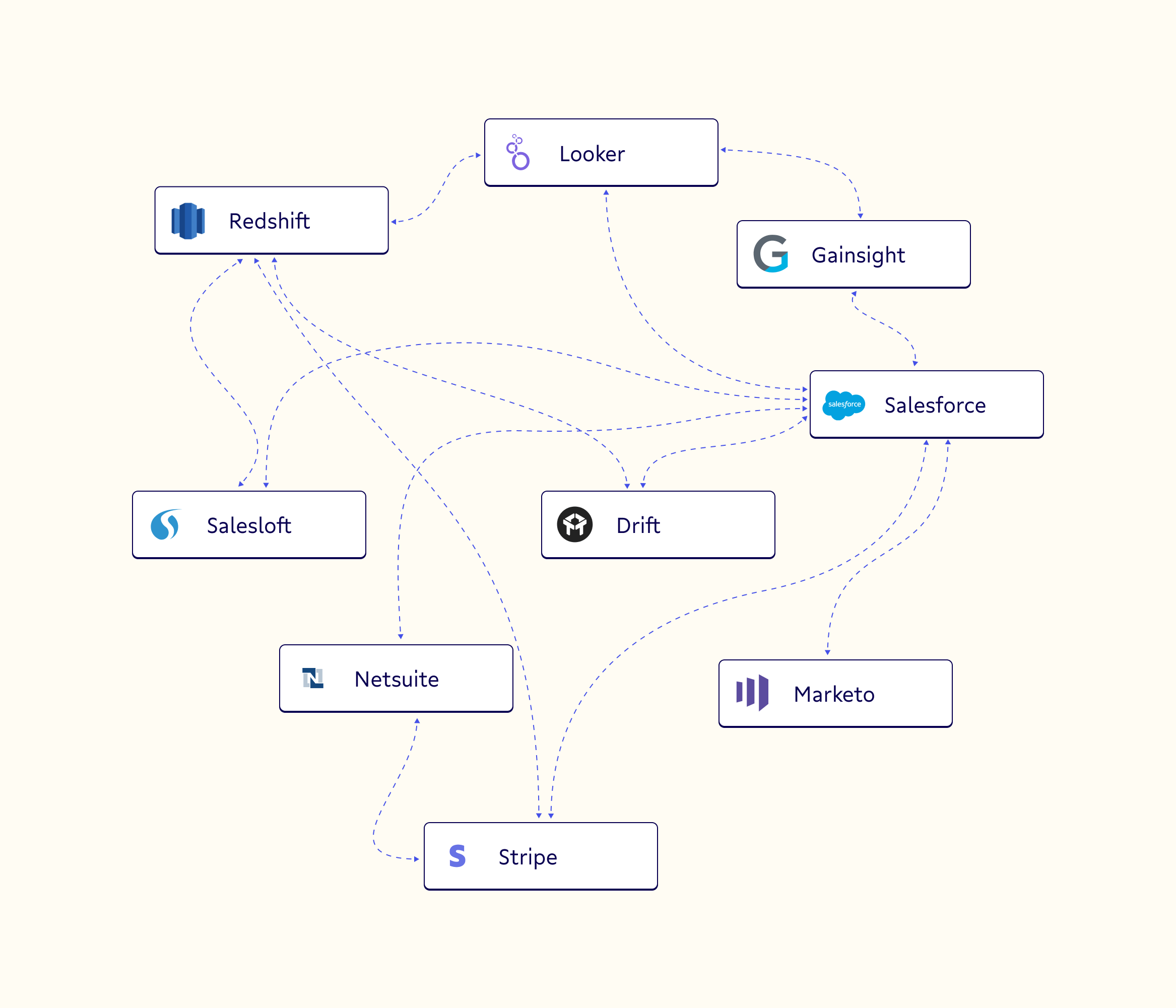
These point-to-point ties between different systems in the business body seem like a quick fix when the body is starting out, but quickly grow to cause problems. They don’t grow with you, and each time one part of the system matures the dependent parts strain to keep up or break. The more connections--whether metaphorical strings or literal APIs and webhooks--you have between each limb, the more dependent and tangled the body becomes.
Essentially, it’d be like limiting your right hand by making it mirror the motions of your left. Sure, you can pick up some of the things you need immediately, but you’ll lack the finesse to execute on anything truly impressive. In our business use case, this misfiring can look like sending the wrong emails to the wrong person at the wrong time.
Furthermore, by bypassing the brain as the hub of your nervous system, the entire system is vulnerable to data stomping, where the movement of one limb (app) can undo or override the movement of another.
Sounds like a hellish mess, doesn’t it?
When you treat your business as an intelligent organism run by an evolving brain of data, your systems can grow with you as they learn the bespoke knowledge that’s unique to your business (e.g. We send X email to Y users when they’ve completed Z action, or show them X promotion when they’ve done Y).
Whereas a piecemeal system would equate 🔥 = danger, an intelligent system with a learned brain can deduce that 🔥 + 🍔 is a good (even desirable) thing, not a threat, and send hunger (not flight) signals as a response. It’s all about the context good data and smart processing provides. At the root of this intelligent system is a nervous system that looks less like the previous jumbled map and more like the streamlined system below:
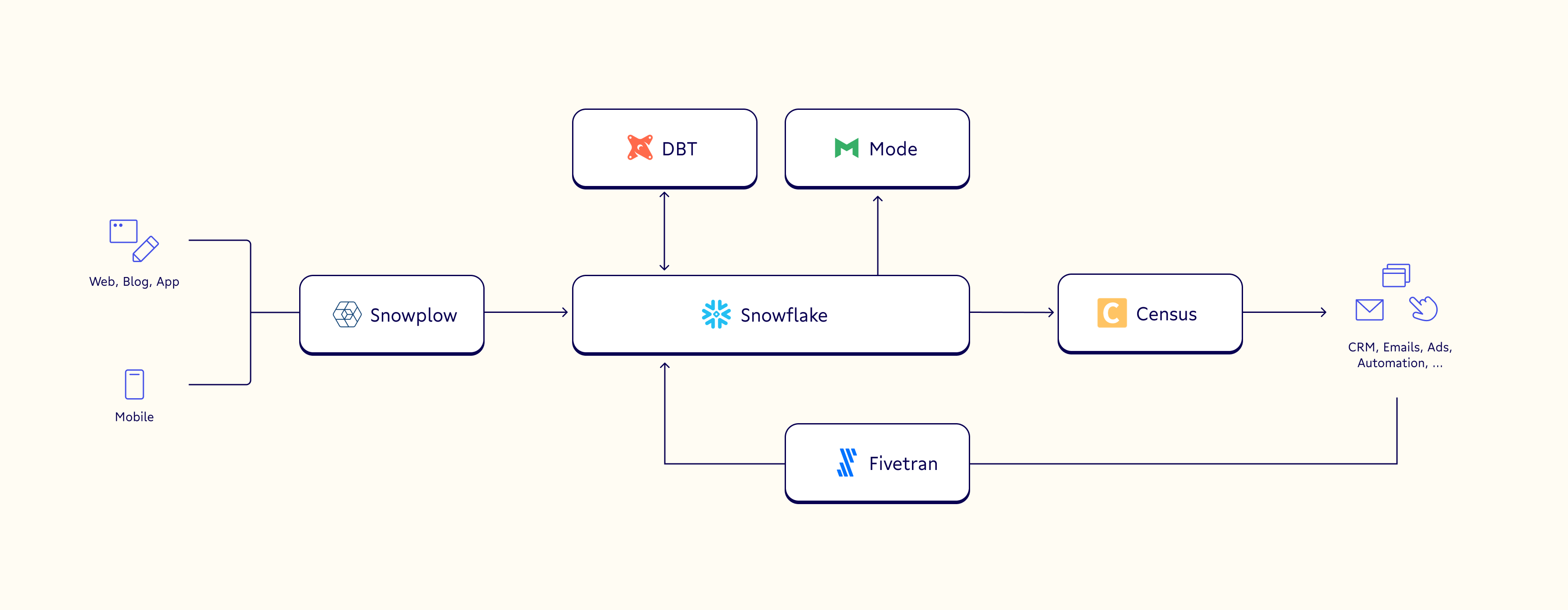
Now, let’s look at the unique role each layer of the data nervous system plays in modern business.
Breaking down the layers of the data nervous system
Our nervous system helps us process the world around us via a series of biological signals. It lets us know when there’s a critical failure or bug in our system, and quickly updates our brain with changes in information from the limbs via organic trigger syncs.
However, our receptor cells don’t give us all the information raw from the world. They prioritize syncing new information and transform it along each step to meet the requirements of the next layer.
As data moves along the pipeline of our stack, it’s encoded and transformed based on a set of computational rules set by each neuron (tool) and its relationship to the next connection. By the time the data reaches our brain (biological or binary) it’s been transformed to fit a predetermined schema for future querying.
This knowledge can then be voluntarily (manually) or involuntarily (continuously/automatically) leveraged for each system within the business. Here’s a breakdown of the role of each layer.
Warehousing and modeling: The brain of your data nervous system
In your modern data stack, the brain is made up of two parts:
- The data warehouse (BigQuery, Snowflake, Redshift) acts as a clearinghouse for all your data.
- The modeling tools (dbt) that contextualize all that data and allow you to learn from and use it in a bunch of different situations.
With these two layers of your stack working in tandem, each team downstream can reference a single source of truth for the most up-to-date and intelligent information. This can make the difference between your marketing team burning out a prospect that your salesperson has already talked to and your marketing team being able to effectively retarget information your warm leads need to convert.
This functioning brain enforces data consistency, syncs data across all the tools and limbs of your company, and can be easily queried when those downstream sources need assistance.
When you pair together a competent data warehouse with a cutting-edge modeling tool, your organization can process and learn from large amounts of data that the human hive mind wouldn’t otherwise be able to get through fast enough. If your business were a human student, this pairing is what enables it to go from solving basic addition to quickly parsing advanced calculus.
Reverse ETL: The spinal cord of your organization
Reverse ETL tools represent a new stage of evolution in the modern data stack and the businesses that rely on it.
Prior to the emergence of reverse ETL--or operational analytics platforms, as we sometimes call it--there wasn’t a great way for the well-armed data brain to get the information it learned back out to the limbs of an organization. Engineering teams within the business body had to build custom connectors every time a team at the edge wanted to improve how it showed up in the world. It was slow, tedious, and inexact all around.
With the addition of reverse ETL tools like Census, a whole new world of action and coordination is available to those teams on the front lines. Reverse ETL tools, when built like Census, integrate with modeling in the data brain and enable the company to sync clean, unified data back into the body via pre-built API integrations.
As a result, engineering and data teams behind the business body don’t have to constantly keep an eye on the manual string connectors that link together the body. Instead, data can be validated automatically out of the warehouse and sent to the limbs that need it most.
Behavioral data collection and ETL: The peripheral nervous system
Your peripheral nervous system is the series of nerves that connect your central nervous system (brain and spinal cord) to the rest of your body. In the modern data stack, ETL tools like Fivetran and behavioral event tracking tools like Snowplow relay vital data between the outside world and your data brain.
These tools, which combine together to gather sensory data from your teams and tools at the edge, relay and transform information for your brain to learn from.
Your behavioral data platform (Snowplow) takes information from your web and mobile apps and sends them to your brain for further analysis. This layer of collection gives your data brain a clear picture of how users interact with your program in the wild so downstream recommendations are tied to the experiences in the real world.
Your ETL data loader lets you copy data from systems of records like Salesforce and Marketo and clean and transform it back into the common structure used by your warehouse for storage and later modeling.
The combination of these two layers of tools helps your data brain contextualize raw data from the world and learn from it. This ensures each team at the edge of your business--whether sales, marketing, support, or beyond--works together in real-time to assist your customers and evangelize for your product.
Sales, marketing, and support teams: The limbs of the company
At the end of the day, all the data processing work done upstream of your sales, marketing, and support teams is to enable your limbs to function better.
After all, it’s these tools--such as Salesforce for sales, HubSpot and Marketo for marketing, Pendo for product data analysis, and more--that make your business and your customer relationships possible. And they can’t do their jobs well without intelligent recommendations from your brain or the real-time relays on your connecting nerves.
When these limbs are powered via a healthy nervous system, you get amazing results. Your frontline teams can use segments of users to drive personalization, leverage account health score and reports, retarget Facebook and Google ads to the correct people, and receive notifications for account activities.
The secret to a long and happy life with data? Operational analytics.
To reach new heights, it’s not enough to just act on what’s happened in your organization's life so far--you need real-time data to power in-the-moment decision-making to make better decisions moving forward.
This is only made possible if your data nervous system is healthy--and connected to the world around it with the strong spine of reverse ETL with Census and behavioral data collection with Snowplow.
If you want to learn more about how Census and Snowplow combine to help you and your team operationalize your data at scale, check out our ebook, the Guide to the Modern Data Stack: Operational Analytics and Reverse ETL, which dives into how reverse ETL helps companies operationalize their behavioral data.
It includes insights building on the foundational concepts we've introduced in this article, including:
- Why we need to look beyond CDPs to deliver excellent experiences to customers
- Delivering behavioral data for actionable outcomes
- Enhancing the Snowplow trial experience with Census
We also released a companion episode of The Sequel Show featuring Snowplow CEO and Co-founder Alex Dean that you can check out here.