































Scale, scale, scale was the name of the reverse ETL game in 2021. The Census team’s work over the last year reflected this focus (both within the company and within the product). As we continue to build the best reverse ETL platform available, we’re doubling down on our mission to also scale the impact of data teams on the business, as well as GTM teams’ ability to do more with data.

All this to say: It’s been a phenomenal year of growth for us (and for all the companies using reverse ETL in their stacks).

Each row of data synced represents more data about a customer-related entity (user, company, workspace, account, etc). We’re so excited to think of the number of ever-increasing personalized customer interactions that data has powered.
Amidst all the industry predictions we know you’re seeing at the end of the year, we wanted to take a breath and celebrate the top five product updates we’re particularly proud of from 2021 (and what they meant for data heroes along the way).
#1. Building the best reverse ETL connectors around
At the beginning of this year we had one goal: Build the best quality reverse ETL connectors on the market. We know connectors sit at the core of your infrastructure and you need to trust them to deliver business-critical data into your operational tools. As such, we doubled down on quality and reliability.
Since day one, we’ve dedicated ourselves to building not just the fastest reverse ETL tool out there (though we’re pretty fast, at 89x faster than other tools on the market), but the most reliable, too. This has meant making critical architectural investments and bets along the way, which have really paid dividends as we and our customers scale.
- Destination connectors: We’ve added a whole slew of high-quality connectors that unlock a range of new use cases and categories for reverse ETL, from marketing and sales (e.g. Gainsight, Iterable, Sailthru) to product analytics (Mixpanel, Amplitude) and finance (Netsuite, Stripe, Chargify). You can check them all out here.
- Universal connectors: Beyond sending data to SaaS tools, we added a set of more “universal” connectors to open up integration avenues with more general standards. For example, you can now send data to Webhooks or file systems via SFTP, S3, and GCS.
- Data source connectors: We’ve tapped into a range of new data sources as well. Our new sources make it easy to: Get started with Google Sheets, leverage existing investments in BI tools with Looker, tap into production databases with MySQL and SQL Server, and get the most out of cutting-edge, real-time databases with Rockset.
- Custom API connector: Our investment in a Custom Destination API connector lets you “bring your own” SaaS tool while using all the core platform reverse ETL benefits Census offers, such as alerting, logging, scheduling, and more. We’ve worked hard to make our custom API connector easy to use and we’ve loved seeing customers, as well as partners like Calixa and Endgame, quickly adopt this functionality.
#2. A grade-A user experience for both data and ops
It’s no secret we think of Census and reverse ETL as the bridge between data and ops teams. This isn’t just a pretty vision, but a mission we’ve worked toward by building an amazing data experience to satisfy the needs of both sides of the business. To make this a reality, we’ve made it easy for anyone to sync data without code, while still offering powerful below-the-hood customization. Here’s a look at how:
- Ever-improving product user experience: This year we’ve made significant investments in the overall user experience of the product. A better UX means more context information related to syncs, models, and connections. One of our fan-favorite improvements was flipping the source and destination in our field mapper! We’re never done working to improve UX, so keep the feedback coming.
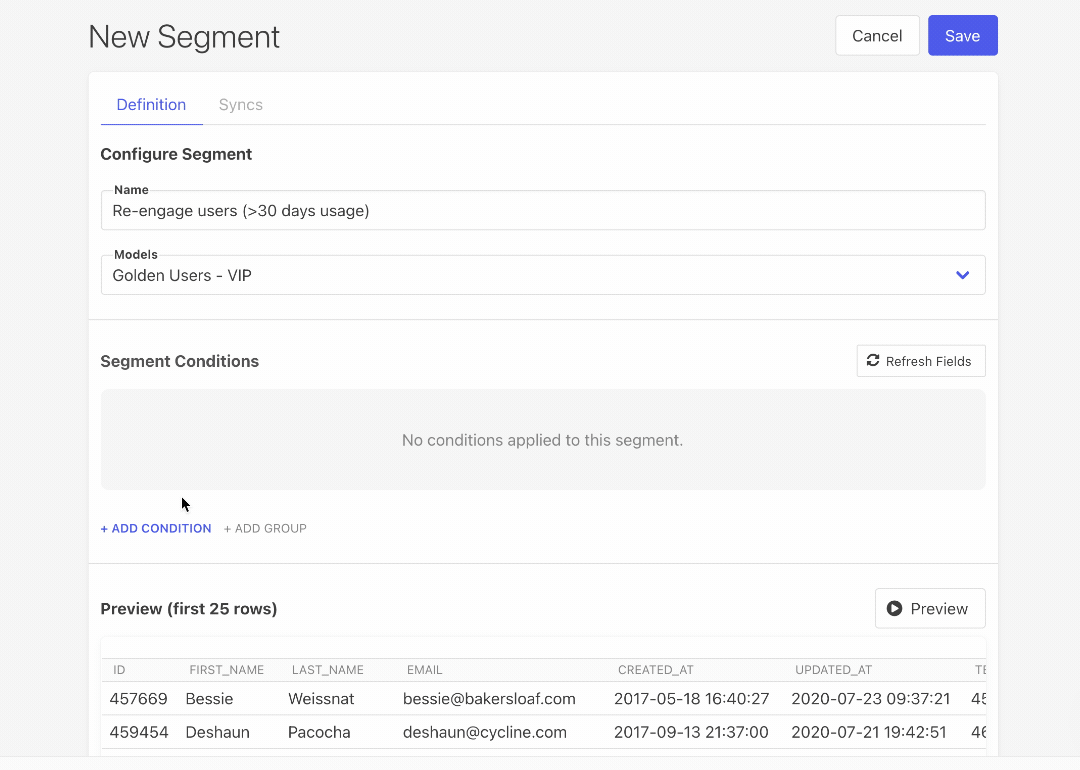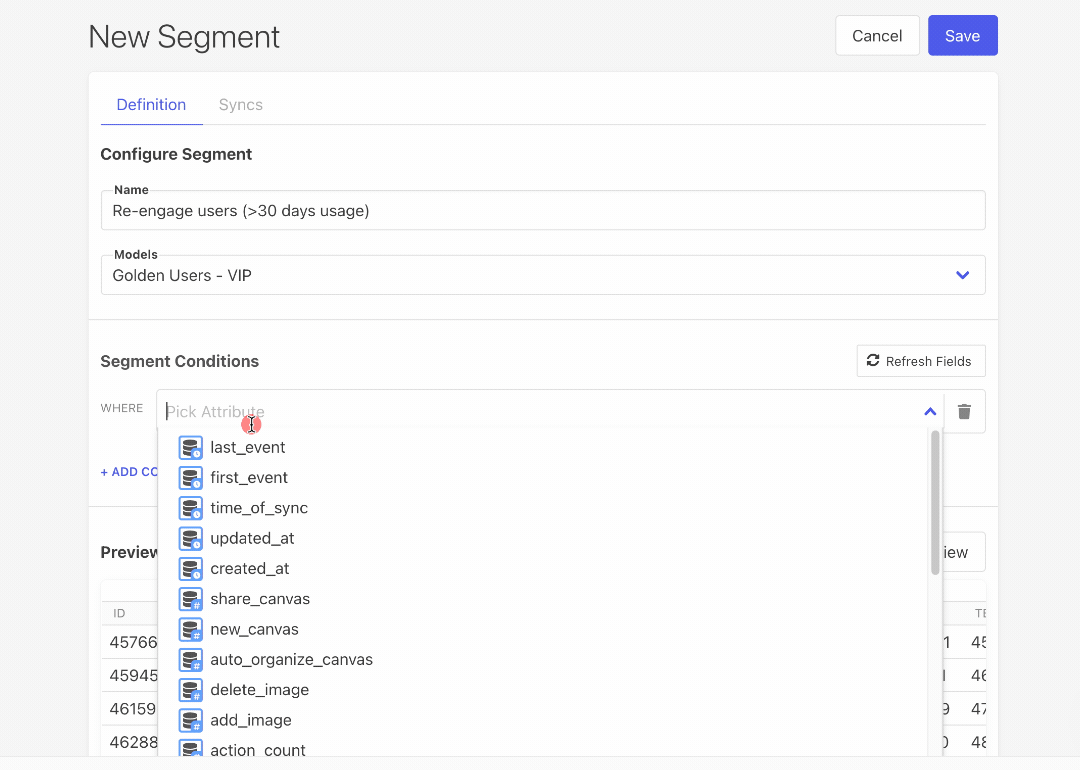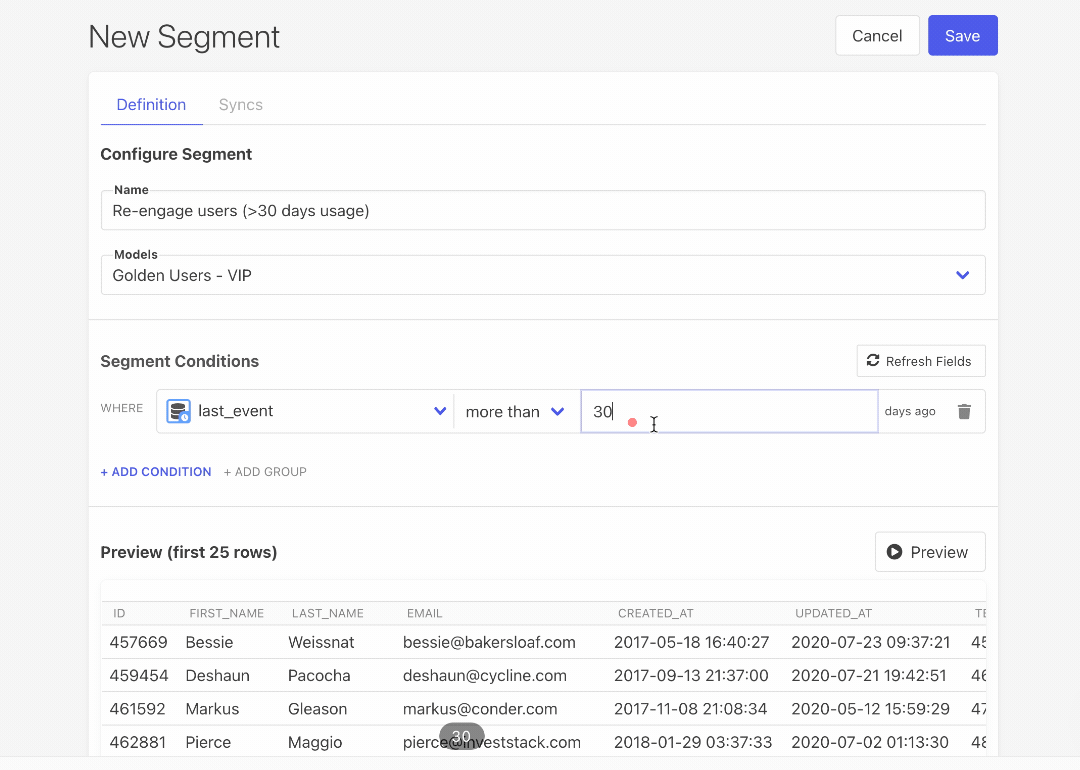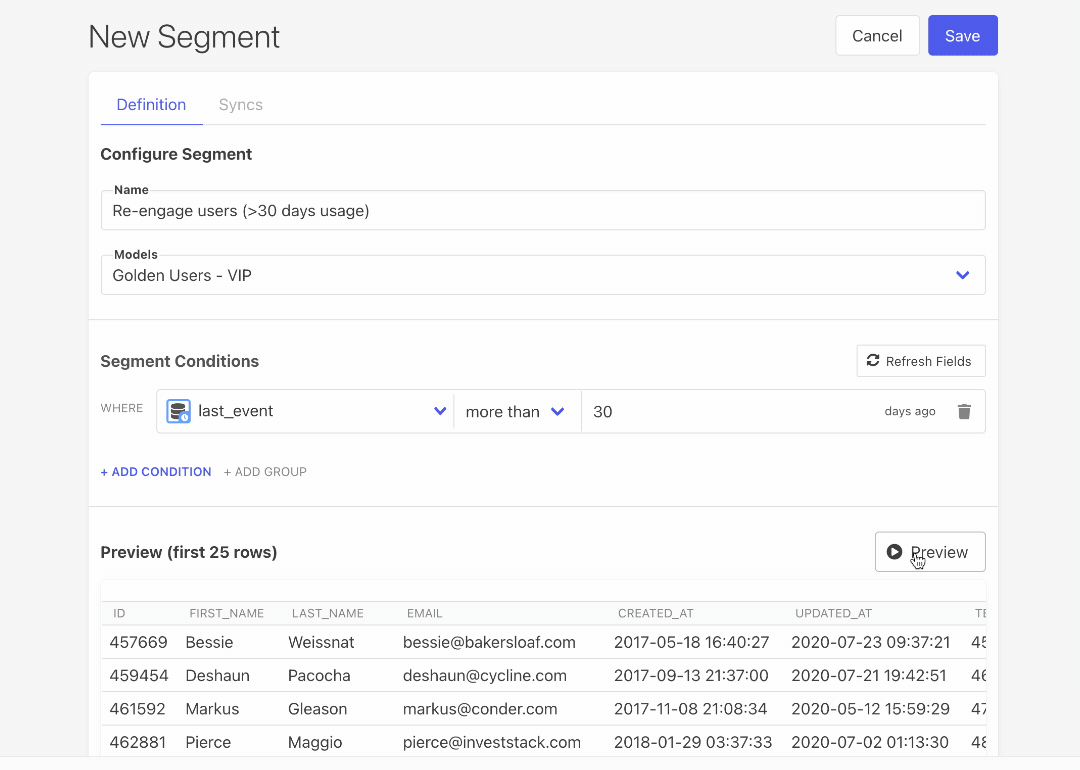
- Visual Segment Builder: Our new Visual Segment Builder lets marketers build segments and audiences of users without having to write SQL. This considerably lowers the barrier to entry for powerful user segmentation and operational analytics for every team relying on data.
- Onboarding with sample datasets and connections. To help you get to the magic faster, we’ve made it easier to start using Census with sample datasets and connections, so you can spend less time setting up and more time experimenting with OA use cases.
#3. We ❤️ dbt
It’s no secret we love dbt over here at Census. We want to be a multiplier on the investments of the data team in centralizing model governance with dbt, by helping them send that data into downstream SaaS tools to power operational analytics. That’s why we’re really proud of our seamless integration with dbt.
One of my favorite Census <> dbt stories comes from the team over at HOVER, who successfully trained their marketing teams to use the modern data stack. When Hurricane Ida hit the east coast of the US, HOVER’s senior growth marketing lead, Max Caldwell, was able to add an attribute into Braze that same day that would help the marketing team reach out to help affected homeowners, simply by updating their dbt model.
We’re excited to see more impactful use cases like HOVER’s as more customers use Census to get more mileage out of their dbt models. Here are a few ways we’ve helped support dbt’s data world takeover in 2021:
- Integration with dbt models: Our dbt integration lets you pull in dbt models to sync data out to the operational tools that rely on them. We compile your models on the fly whenever a sync is scheduled so your data and your models are always up to date.
- Automatic trigger syncs from dbt runs: You can set up syncs connected to dbt models to automatically trigger when your dbt model refreshes.
- Build visual segments on top of dbt models: Our Visual Segment Builder lets you build user segments on top of your dbt models, too!
#4. Observability and data quality features

As Sarah Krasnik, data engineer at Perpay, recently reminded us at DataEngBytes: “With great power comes great responsibility.”
The operational data you sync into business tools is truly mission-critical: The consequences of getting it wrong aren’t just bad. Errors in data can cause you to send thousands of users irrelevant emails or spend thousands of dollars on wasteful ads targeting the wrong audiences.
That’s why the ability to sync with confidence is more important than ever. With trust in data comes trust in downstream tools, and trust in the data team itself. Here are some of the areas we’ve invested in to foster trust in all things data:
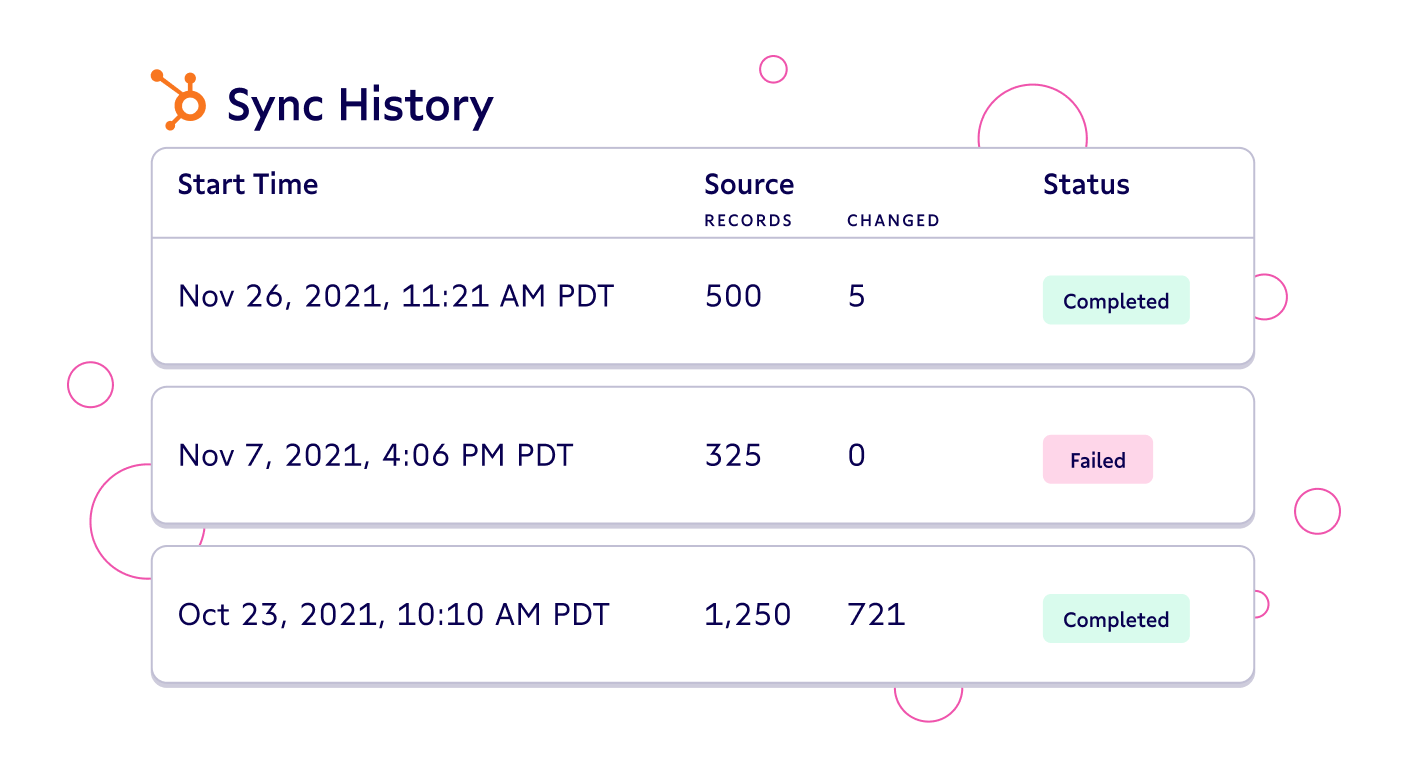
- Alerting: Set-up alerts for not just failed syncs, but syncs with invalid source records or records rejected by the destination. You can also configure thresholds for alerts so you don’t have to deal with alert fatigue. Receive alerts via email and Slack.
- Logging: You can easily see logs for failed records, with error messages to help you debug data quality or sync issues.
- Dupe detection: Census automatically runs multiple checks before we sync data, such as automatically detecting duplicate key records and flagging them as invalid before we sync.
- Send a test record: Send a test record into your downstream tool to validate your Sync is working properly.
- Proactive model change detection: Census automatically checks that sync configuration is still valid against the source and surfaces any warnings so you can easily remove or rename a column inside of a model (without breaking everything).
#5. Interoperability with the modern data stack
Reverse ETL isn’t just another data tool or pipeline. Reverse ETL unlocks operational analytics and data-driven business at a scale never before possible and, as such, we want to ensure Census is a good data citizen within your stack. This means prioritizing strong integrations with the rest of the ever-expanding data ecosystem. One of the ways we build with best practices in mind is by subscribing to the DRY ("do not repeat yourself") philosophy from the DevOps world and maintaining a strong focus on interoperability.
In addition to our investments in features like our dbt integration and Custom API connector that we’ve already covered, we’ve backed up this philosophy on the product side in 2021 with:
- Integrations with orchestration tools like Airflow and Prefect.io so you can orchestrate your entire data pipeline end-to-end from ETL to reverse ETL in a single place and avoid repeating job steps (or having to check multiple tools for a status). Trigger Census syncs and receive feedback on sync status via our integrations.
- Improvements to the Census API to ensure a strong foundational public API to programmatically create and trigger syncs.
Bonus: Security and compliance are at the core of everything we do
We know security and compliance really matters, and so it deserves a special mention here. We’ve always built security from the ground up so our customers don’t have to worry about it. We’re the only reverse ETL tool that keeps your data in your warehouse, and we’ll continue to follow that security-first principle in the coming years.
What does that mean in the product? Thus far, we’ve focused on the following core pillars of security:
- Data stays in your warehouse: We set the security standard for reverse ETL by keeping your data in your data warehouse to reduce your overall security surface area.
- SOC 2 TYPE II: Beyond undergoing regular internal security audits and third-party penetration testing, Census received our SOC 2 Type II examination, which demonstrates a commitment to auditing standards for a longer period of time.
- GDPR, CCPA, HIPAA: We take regulatory compliance seriously and have continued to expand our compliance in each of these areas.
The past year has far surpassed any of our expectations. It wouldn’t be possible without you, our Census Champions. Thank you for the constant support, engagement, and product feedback. You inspire us every day with all the amazing things you do with data.
Looking forward to next year, we’re excited to not only build amazing products to support your vision but also help you inspire each other with The Operational Analytics Club, our dedicated community to help data practitioners and data-driven rev ops professionals learn and grow together to scale their impact.
If you haven’t already, sync yourself some SQL-based swag with our newest bonus destination connector: Sync-a-Swag.
