































Reverse ETL is exciting because it syncs live data to your tools. Our customers use Census to power automated workflows like personalized referral emails or fresh product analytics for go-to-market teams.
However, as data engineers know, one small edit in dbt can result in real business mistakes. Decisions are misinformed, machine learning models train on misleading data, or customers receive the wrong experience from your marketing, sales, and success organizations.
Our vision is to create an environment where Operations and Data teams can collaborate on data projects with confidence. Creating a reverse ETL sync also creates an implicit contract between teams that data will continue to be trustworthy, high quality, and available. Enforcing a Data Contract requires capabilities that alert the right people about changes that impact business workflows, so they can proactively prevent breakages.
Census already provides end-to-end visibility into your data flows via robust observability and monitoring features. These are critical to understanding and debugging reverse ETL syncs, and our customers currently use them to guarantee healthy data pipelines. However, we think the real opportunity is to prevent issues before they happen.
Today, Census takes the first step towards enabling Data Contracts for Reverse ETL by integrating with your data CI/CD process. We’re releasing dbt Continuous Integration (CI) Checks: a feature to help you double-check that your dbt work won’t break your Census syncs.
Announcing Census’s dbt CI Checks in GitHub
dbt is like your data cookbook. You use it to write recipes on how to transform raw ingredients into a wonderful meal – or in this case, a dataset. 🥘

When you’re working upstream in dbt, it can be hard to remember which reverse ETL syncs depend on a particular dbt model. You could potentially break a sync that keeps a live metric up-to-date.
When using the Census dbt integration, dbt CI Checks will run in your GitHub account and let you know if you’re about to drop, rename, or move a dbt model that a Census sync depends on.
Now, you can get an early warning if you're going to break your workflows when you make a change – directly within your GitHub pull request.
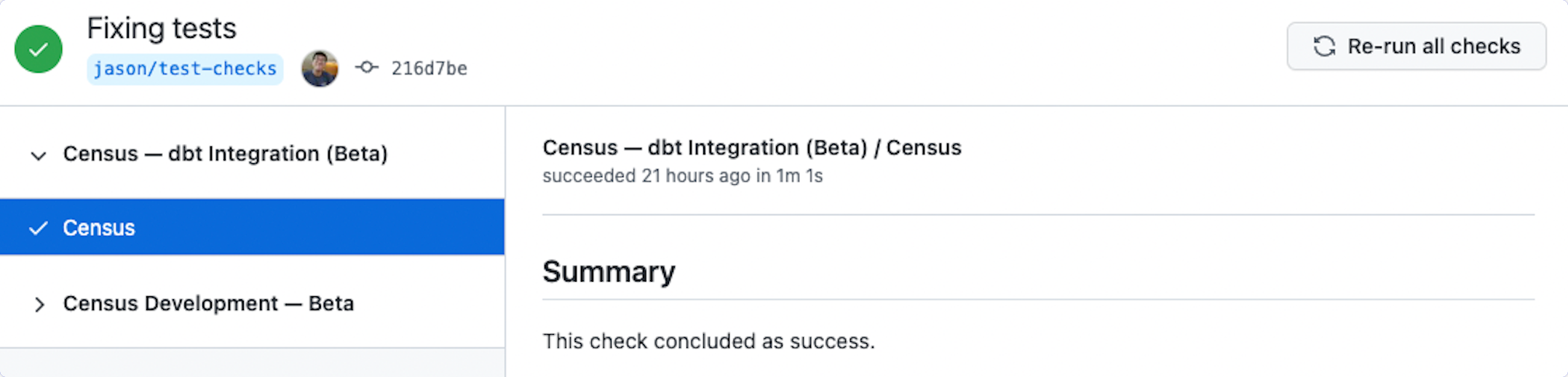
How do Census’s dbt CI Checks work?
Check out our product documentation, or watch a handy video tutorial:
When you create a Pull Request (PR) in your dbt repository or commit to any branch with an open Pull Request, Census will run an integration test in your GitHub instance to confirm whether any Census syncs will break because the dbt model is being renamed, deleted, or moved to a different file path.
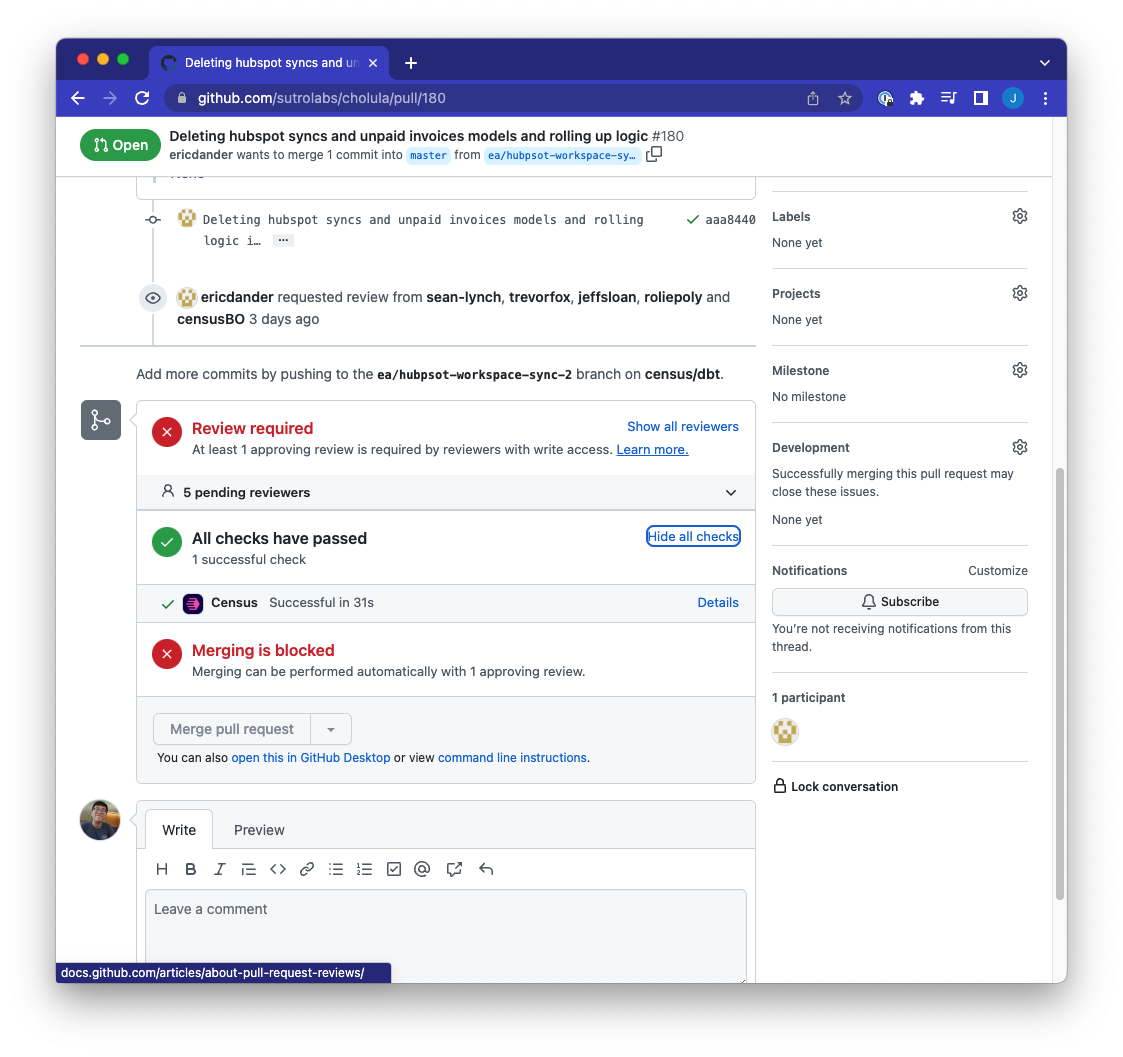
If the dbt model name or directory change will break a Census sync, Github will warn you before you merge the pull request.
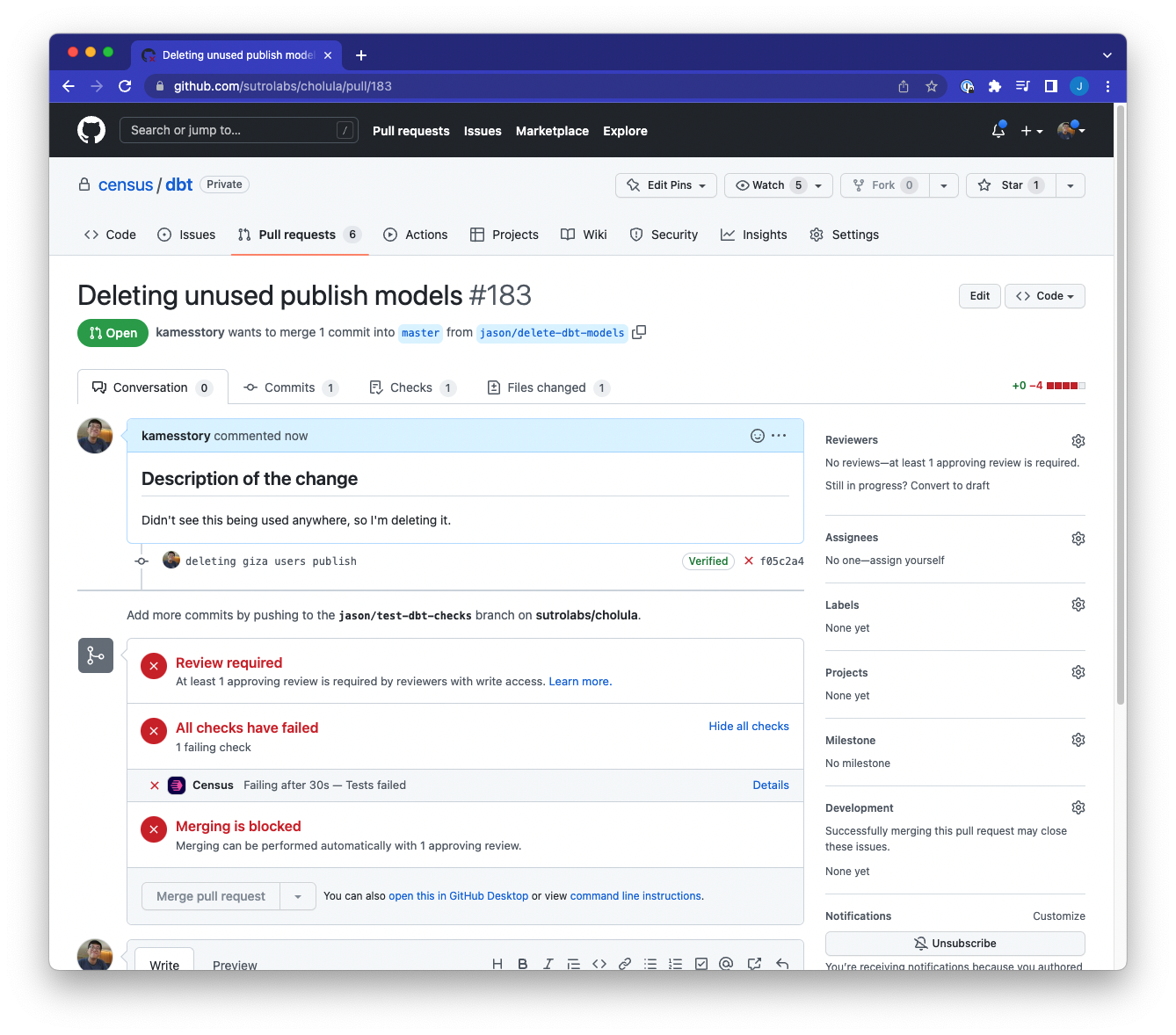
You can see a report of what succeeded and failed, plus which Census syncs or dbt models the PR will affect. Hyperlinks back to Census will enable you to see exactly which data flows will be affected, so you can make plans to adjust your syncs after merging your PR.
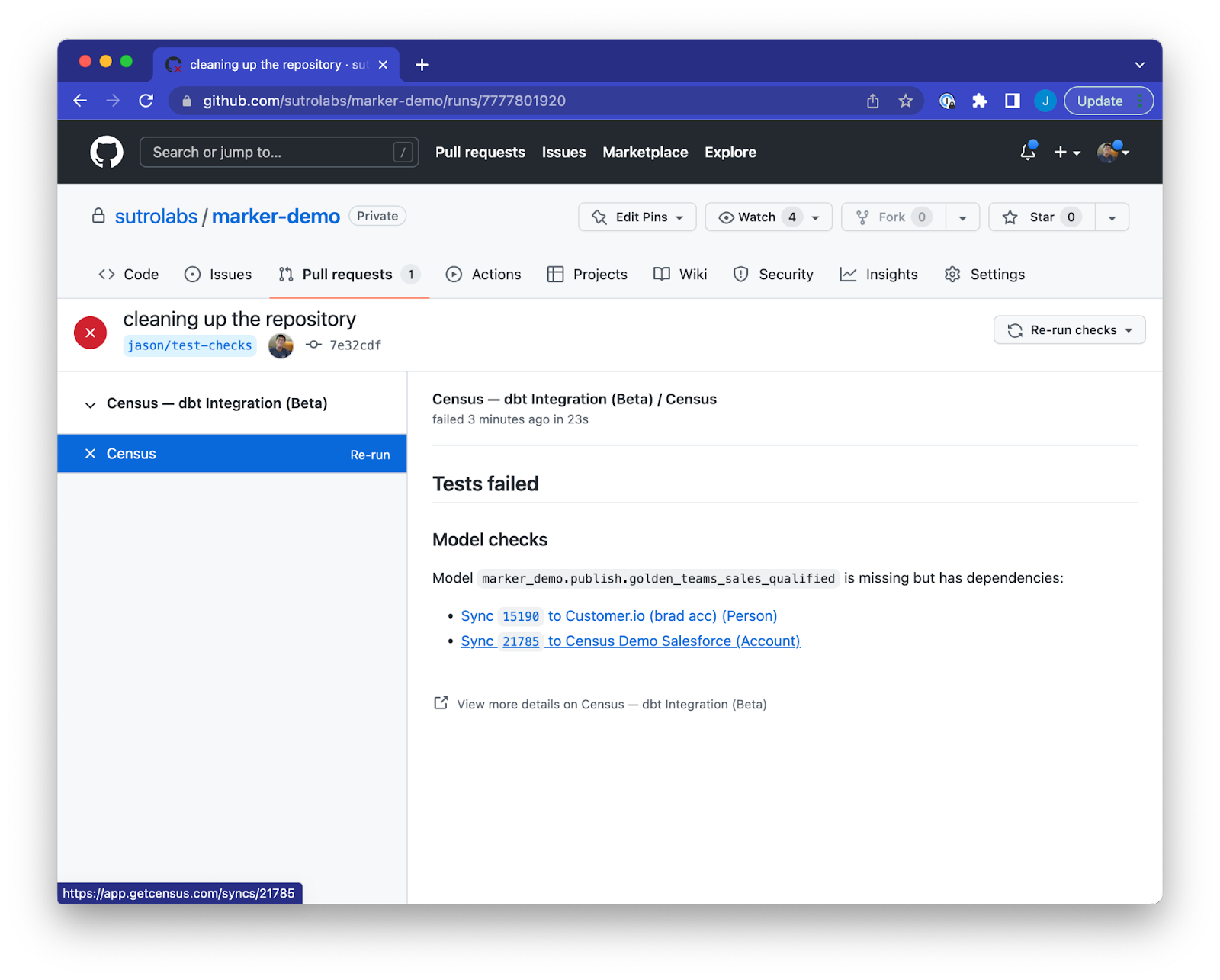
When using the Census dbt integration, you can have further confidence that your modeling work in dbt won’t break downstream data.
Get Started
Here’s how to enable dbt CI Checks for your dbt models in Census.
- Navigate to your organization’s dbt Models page.
- Go to the settings to ⚙️ Configure dbt Project.
- Click the “Enable CI/CD Tests in Github” button to enable dbt CI Checks for your organization. If you’re enabling this for the first time, you might have to grant additional permissions to Census within Github.
For help, follow the product docs, use the in-app chatbox, or reach out to support@getcensus.com with any questions.
👉 Chat with your dedicated Census data consultant or start using Census today with a free trial.
dbt + Census: Do more with your dbt models than just reporting 🤝
With dbt and Census, you can extend your dbt work beyond BI and dashboards. You’ve spent weeks building unified data models – now you can use our native dbt integration to connect those models and materialize them directly into your go-to-market tools.
dbt + Census enables you to:
- Use centralized data models to quickly deliver standardized metrics to all your business apps
- Keep all your transform logic in one repository and streamline the data team’s workflows
- Automate your materialization schedule and data pipelines
Census compiles your models on the fly whenever a sync is scheduled so your data and your models are always up to date.
If you're using dbt Cloud to run your dbt project, our integration goes even further. You can configure Census to automatically run syncs whenever your models have been rebuilt. See our docs on connecting and configuring dbt Cloud.
If you’re new to dbt-world, check out our explainer blog: What is dbt?
What’s next?
The release of dbt CI Checks expands our support for software engineering best practices for DataOps, and deepens our integration with dbt – one of the most popular data transformation tools in the Modern Data Stack.
Data Contracts will only become more important because downstream users make decisions based on live data flows. As data practitioners become more critical to their organizations, their data ecosystems are also becoming increasingly complex. Automated testing and detection is the only way data and analytics engineers can keep up with their infrastructure at scale.
In fact, we believe that in the near future, features like Census’s dbt CI Checks will be the default. On top of CI tests for data quality (like dbt Cloud’s native continuous integration testing), there will be checks on every dbt repo that ensure changes won’t break downstream processes. For Census’s CI Checks, the future will include checks on dropped and renamed columns, as well as validation that data type changes won’t disrupt your reverse ETL syncs.
Any thoughts? We’d love to chat with you about the future of DataOps, how to design tests, or dbt best practices. Find us in the Operational Analytics Club Slack community!