































This debut edition of Select Stars series was updated on December 12 to expand on Prolific’s use case. This Census series of profiles highlights data practitioners driving more impact with Operational Analytics.
Jim Lumsden is the data lead at Prolific, a two-sided marketplace that helps researchers of all kinds conduct online research. In this interview, Jim shares how he became the first data hire at Prolific, and how he drove more impact with the company’s brand new sales team by syncing key product analytics to Hubspot with the modern data stack, including Census, Snowplow, and Redshift.
What led you to a career in data?
I completed a PhD in online research methods at the University of Bristol, tackling the question: “How can we make data collection better?” During my PhD I was actually a Prolific customer – I was running lots of online studies, looking at what type of people are taking part in research on the internet, specifically uncovering why they were doing it and how we could incentivize them. By the end of my PhD, it was quite natural to step into a role at Prolific. When I joined, the company was only eight people, and as the first data hire I don't think I really knew what I was doing; I just figured it out as we went along.
What is your role at Prolific, and what are the responsibilities of the data team?
I've been through many job titles in my time at Prolific. Over the four years that I've been here, I've been everything from a data analyst to a growth analyst, and everything in between (including cold calling people in sales and marketing – that was an interesting time!). After we became part of the YC batch in 2019, I started settling into the Data Lead role. Since then, I've spent most of my time building our hard data stack and hiring a data team to serve our product needs, all while supporting our business intelligence and financial reporting divisions.
The data team manages all-things data at Prolific. So, when we break it down, we have three main functions: managing the infrastructure, providing ad-hoc analytics support, and building data products. Even though we’ve separated our duties into “functions”, there's a lot of blurriness between those different functions – especially in our small team of six.
How would you describe the mission of Prolific’s data team?
If there's one strategy that we live by, it's this: Self-serve access to data is crucial for decision making. With a small team like ours, there's no feasible way that we can tend to the constant demand across the company, at least not at the level of data-drivenness that we want to see.
To compensate, we've set up tools like Metabase that give people hands-on access to data, in conjunction with tools like dbt to transform the data in our data warehouse – which are intuitive and easy for anyone to work with. With that setup, we can serve 20% of requests deeply, and the other 80% can be self-served, giving customers the freedom to make those decisions without feeling like they’ll be slowed down waiting for someone to resolve their request.
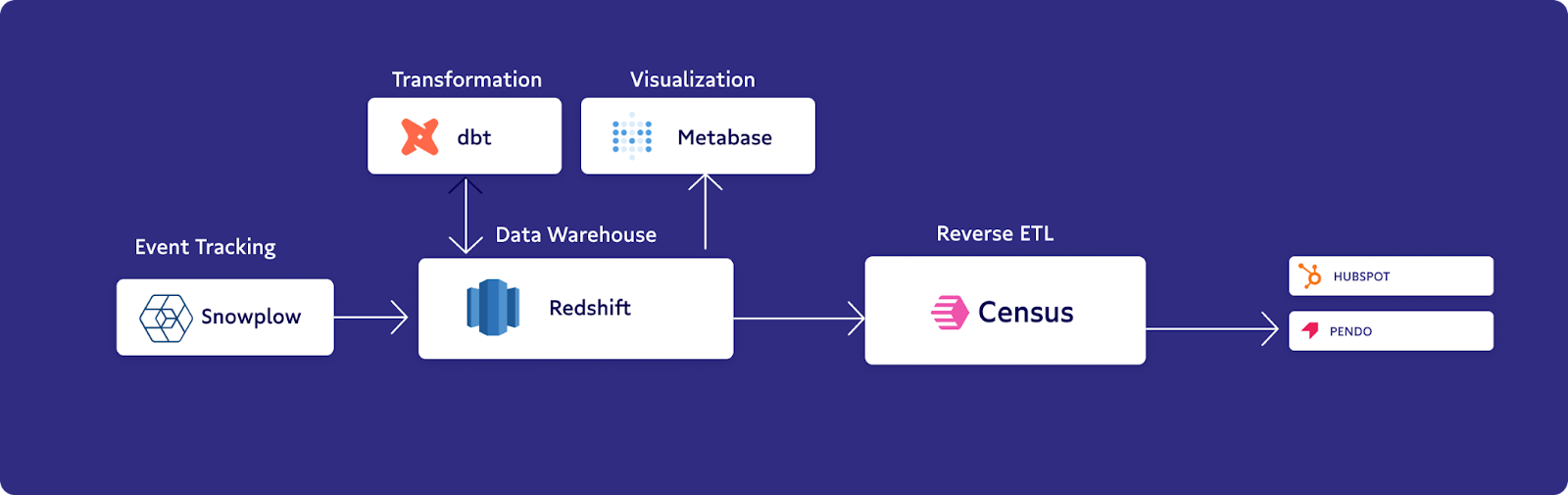
Next up, we asked Jim to deep dive on an impactful operational analytics use case with us.
Show & Tell: Getting key user product metrics and actions in Hubspot for Sales
Reverse ETL became a core tool for our team in the last couple of months, especially since we started setting up our sales team with HubSpot as our CRM. We wanted to send a summary of customer data over to HubSpot so that our salespeople could make informed decisions and interact with potential or actual customers at the opportune moment.
Snowplow was really the snowball that got our whole data stack rolling back in 2020 when we had an aspirational data dream, a smaller team, and the early stages of our infrastructure. From there, we started to do transformations in Redshift and dbt, and then were able to send the results of those transformations via Census to HubSpot. The end result is basically like having a friend or consultant with all the data you could need standing over your shoulder.
Many of our customers are affiliated with universities and, as you can imagine, there are dozens, if not hundreds of researchers that might want to use Prolific. Previously, we were treating all of these researchers as individuals, but when their data lands in HubSpot, we want to be able to pull them together and group them as part of an organization.
We already had the data models, but what we were lacking was the ability to sync the majority of fields in those data models over to HubSpot. So, we built new data models that aggregated data on researchers at both the contact and company levels, combining first and last key user actions.
You can think about first actions and how long it takes for someone to display some purchase intent or buy their first item. These are good indications of if this is likely to be someone who is going to convert to a high value. Are they going to convert fast? Do they need much support?
To give us the whole picture, we also want the timestamps of their last action to trigger sales workflows in HubSpot. For instance, if someone’s last login is over two weeks ago, we can trigger a workflow that will prompt a salesperson to reach out each morning or just review that account to check that everything is healthy.
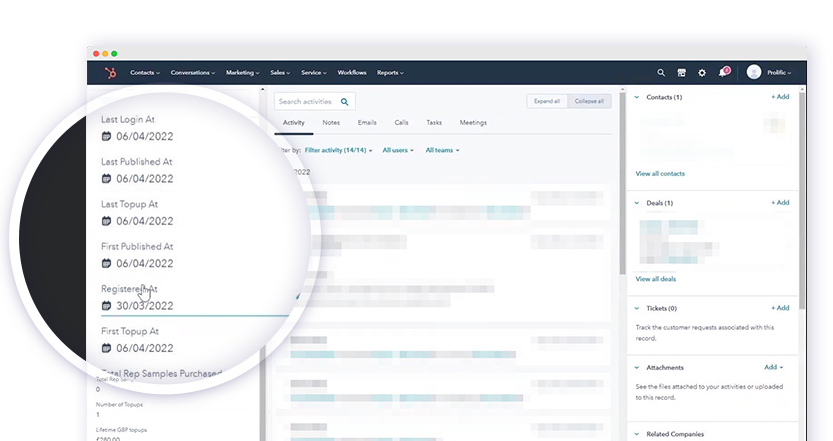
Along with the first and last user actions, we've got aggregate numbers that tell us about the health of the account. How much money have they made us, or how much have they added to their wallet? How many studies have they conducted on Prolific? What country are they based in?
Basically, we want to give our young sales team as much context as possible about who they're interacting with. They need to be able to pinpoint a customer and go, “Okay, this person has literally used us hundreds of times.” That’s going to change the way that they talk to them, how they interact, their use of language, and the way they deal with different concepts. In our case, this is all really important because we're a seven-year-old company with a three-month-old sales team.
What impact did this use case have on your business?
Since integrating this workflow, the level of visibility we now have over customers’ interactions with our platform is huge. Everything in a product comes down to how well you understand the customer's psychology and, unless you understand their thinking and their behavior, you're flying blind.
Although that data has always been accessible to our salespeople, it's usually stored in another app or another tab. Now, it's right there in HubSpot, ready to automatically trigger workflows, so we can use it to strike at the opportune moment. We can see if someone has high purchase intent, and we can be there with an email saying, “Hey, I saw you were doing this on the platform yesterday. Is there anything I can do to help you get it over the line?” That kind of time-sensitive action is what makes the Hubspot plus data warehouse team work so well.
We've closed more than 10 new, big logos in the short time that we’ve been up and running with this data in HubSpot. For us, the added visibility has allowed us to unlock the power of our sales team; they’re no longer working blind. Every morning they know what their customers are doing because the data lands in HubSpot overnight.
Smoothing out our data pipelines and making reusable, scalable self-serve a reality has freed up the team to focus on new data growth frontiers to help support the business better.
Building out these first initial use cases has also fueled even bigger data dreams for 2023 and beyond, including thinking of ways we can dive deeper into the behavioral data of our researches to create Customer Behavioral Profiles for churn prediction, lifespan analysis, and reengagement opportunities. That’d be incredibly powerful since, especially with sales and customer success, timing is everything.
What advice would you give to other small data teams trying to prioritize their work?
First: Get everyone on board with the importance of building Customer Behavioral Profiles early on. It doesn’t matter what team you’re on, the entire business is built around customers and the data they provide. The only way to boost engagement with those customers is by serving contextual personalized experiences based on the descriptive richness of their behavioral data - how they act on your site and in your product, for how long and in what patterns.
Second: I think there's a tendency within small data teams to try to solve every single problem at once. The fact is: Building out a good data stack takes some time, but the advantage of doing it is that it saves you so much time in the future. There's a reason that tools like dbt are considered “best-in-class” – they take your raw, messy data, transform it, and make it easy to send to other places without messy connections or unmaintainable infrastructure. You need to get a data warehouse, put dbt on top of it, and start doing very basic visualization for end users.
Follow that up by going deep with a specific team. Whether that involves working with the sales team to set up the day-to-day needs to do successful sales, or working with your finance team to do water-tight monthly reconciliation, there's going to be some area in your business that sorely needs data. You can't fight all the fires at once, so pick a specific area, work really closely with those stakeholders, understand that problem space, and build data products that serve their needs.
The knowledge you gain and the infrastructure you put in place along the way will serve you across other areas of the business – focus on delivering value in one specific area rather than drowning in the demands of data in the small business.
You don’t notice each day that you’re getting more and more self-sufficient and flexible. But what we can do now with our full stack (and with all these tools in combination) was just unimaginable in 2020.
✨ Learn more about how Prolific use Census for Operational Analytics and deep dive into how they chose their stack in our webinar with Jim. 👇
🤩 Want to be featured in our next Select Stars profile? Apply here and we’ll be in touch soon!