































When I first joined the Operational Analytics Club, I initially viewed this as simply another means to network with members of the data community.
Instead, I quickly learned there are many opportunities to connect more deeply with folks within this club, including technical workshops, mentorship programs, and, my personal favorite, a book club. I immediately joined the book club to motivate myself to regularly read books on the data world and gain insights from veterans in the data space.
TitleCase: OA Book Club
Originally, I joined the OA Book Club since their chosen book piqued my interest: Fundamentals of Data Engineering: Plan and Build Robust Data Systems by Joe Reis and Matt Housley (which, fun fact, I’d actually had the opportunity to chat with Joe at a couple of data meet-ups in the Greater Salt Lake City area).
This book is a must-read for anyone entering into the tech space — whether that's data engineers/scientists looking for a more abstract view of an extremely complex landscape or business leaders who want to better understand the intricacies of the data lifecycle in order to drive strong ROI from the data gathered by their businesses.
Before we get too deep into the summary of this first part of the book, a note on the overall theme: Focus on the abstract rather than specific tools and technologies. Before reading, I honestly felt lost about which direction to take and what tools I needed to learn before others. 🤷 This book has completely shifted my view on how to understand data engineering; I need to understand the entirety of the data engineering lifecycle without focusing too much on the specific tools.
This article is the first of a three-part series covering each book club meeting on The Fundamentals of Data Engineering in The OA Club (here’s more info if you’d like to join). Part one covers the discussion regarding chapters 1-3. The two main takeaways I gathered from the first meeting are:
- Every decision regarding data needs to be driven by business needs
- Reversible decisions should be prioritized for each step in the data engineering lifecycle.
Let’s get into it! 🤓
Business needs drive decisions on data
At the end of the day, everyone working on data within an organization needs to start by asking themselves: “How does this project/tool/technology create value for my business?”
There are many metrics you can use to figure out how much value a new project or tool can create, including ROI, opportunity cost, etc. The authors exemplify how a business can instill this question into company culture by discussing their data maturity model. There are three tiers to this model 👇
- Starting with Data: These companies are early in building out their data infrastructure and teams. Or, as Housley and Reis write, “Reports or analyses lack formal structure, and most requests for data are ad hoc.”
- Scaling with Data: These companies have formal data practices in place, but they have not established scalable architecture that can shift at a moment’s notice based on business needs or technological disruptions.
- Leading with Data: These companies are truly data-driven. Again, Housley and Reis are spot-on with: “The automated [data] pipelines and systems created by data engineers allow people within the company to do self-service analytics and ML. Introducing new data sources is seamless, and tangible value is derived.”
I truly believe the most successful companies for the foreseeable future will all be data-led companies. Companies that create robust, modular data architectures and base all decisions on driving value for the business will leave their competitors in the dust. 🚀
Business leaders can not afford to stop thinking about their end users or customers; once a company begins to pursue new technologies or projects simply to do them, they have lost sight of the end goal. As the authors write, “Data has value when it’s used for practical purposes. Data that is not consumed or queried is simply inert. Data vanity projects are a major risk for companies… Data projects must be intentional across the lifecycle.”
Vanity data projects or “passion projects”, while fun, can quickly take a data team’s focus away from creating value for the organization or end users’ needs. These projects tend to be nothing more than a massive waste of time and capital.
Anything that a data team undertakes simply to use a new technology or tool without considering how the project will benefit their organization could be considered a vanity data project. An interesting point from the book is that “technology distractions are a more significant danger [for companies that lead with data]. There’s a temptation to pursue expensive hobby projects that don’t deliver value to the business.”
A good representation of how to avoid “passion projects” is The Data Science Hierarchy of Needs (shown below). 👇
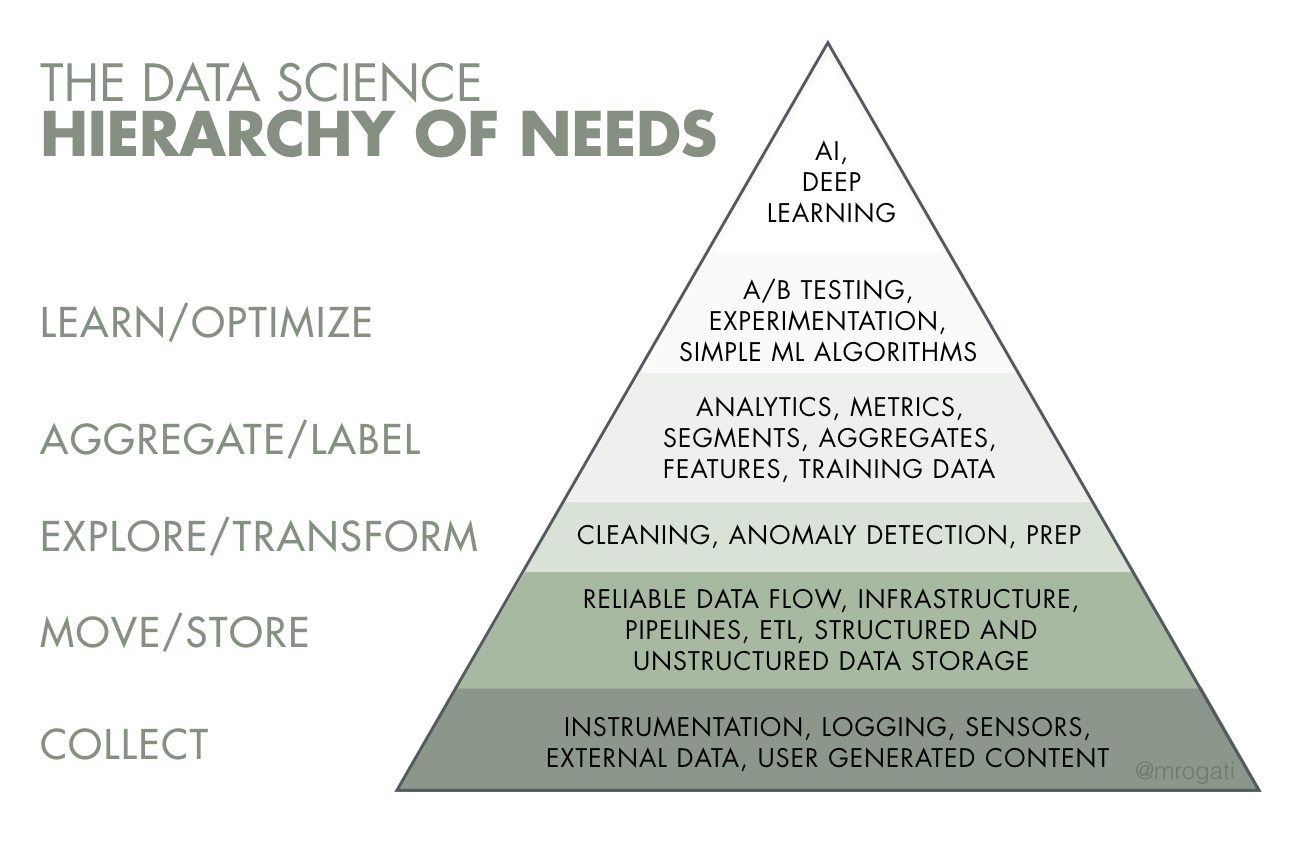
If your organization does not have a reliable data infrastructure that can collect, move/store, and transform data, then it is probably best to hold off on creating any ML models or using complex AI. Or, as Housley and Reis put it, “[We have] seen countless data teams get stuck and fall short when they try to jump to ML without building a solid data foundation.”
These teams most likely wanted to jump into machine learning without considering how this would drive meaningful value for their organization.
Reversible decisions keep your business agile
Reversible decisions — those that can be undone if results are subpar or unpredictable — should be the bread-and-butter of all decisions made within a company. Irreversible decisions leave your organization stuck with the outcomes, and these decisions will often cause significant pain down the road. While this concept seems relatively obvious, in practice it is anything but.
This principle applies neatly to data architecture decisions. As many of us know, creating data architecture within an organization is full of trade-offs: If each decision made can be reversed at a moment’s notice (or close to it), any future business risks can be mitigated.
The authors sum up this sentiment well: “Since the stakes attached to each reversible decision (two-way door) are low, organizations can make more decisions, iterating, improving, and collecting data rapidly.” 🚪 Jeff Bezos coined the terms one-way vs. two-way doors to describe how organizations/people can make decisions 👇
- A one-way door means that you walk through the door, and if you don’t like what you see, you can’t go back through the door. ⛔
- A two-way door on the other hand allows you to survey the outcome of going through the door, and if you aren’t satisfied, you can go back through the door (i.e. reverse the decision). 🔙
The idea of making reversible decisions goes hand-in-hand with building loosely coupled systems. 🤝 In a tightly coupled system, there are significant inter-dependencies among components of the system. In other words, if one component of the system fails, the entire system fails. In a loosely coupled system, components work independently from one another. If one component fails, the entire system does not collapse.
Building loosely coupled architecture was a topic that came up throughout the first book club meeting. Many members explained one benefit of the loosely coupled architecture is it allows for plug-and-play solutions, allowing for modularity and aligning with the ideology of making reversible decisions.
In a loosely coupled architecture, if you and your organization realize one tool in your data stack has either become obsolete or no longer suits your business requirements, you can simply replace the tool without significant downtime.
However, if your organization has a tightly coupled architecture, you’ll experience significantly more headaches and struggles when trying to replace one specific tool. So, if you and your organization are trying to completely revamp your data stack, it would be wise to identify any aspects of your architecture that are irreversible and replace them earlier.
Beyond decisions: Looking ahead at our next learnings
I have learned much more than I could have anticipated just from the first few chapters, and I am thrilled to dive deeper into the subject of data engineering with this group. Again, the key arguments that I have picked up from the authors thus far are:
- Business needs ultimately drive all decisions regarding data.
- Make reversible decisions within your business as much as possible.
Honestly, I would not have found this book had I not joined the OA club, and I’m ecstatic to be part of a community full of data practitioners who are so willing to offer guidance and advice to someone much earlier in their data career.
The OA Club and TitleCase have been a blast, and I can’t emphasize just how much I’ve gained in this first segment! I can’t wait to see you at the next Book Club meeting. 📚 👀
👉 If you’re interested in joining the TitleCase OA Book Club, head to this link. Parker Rogers, data community advocate at Census, leads it every two weeks for about an hour.