































Rumor has it that Redshift was named for its desire to shift people away from data warehousing offered by Oracle (whose brand used to be “red” ). In that line of thinking, you can think of Snowflake as Redshiftshift.
Snowflake is a modern data-warehousing solution that’s built with the needs of today’s data teams in mind. Amazon Redshift is a huge legacy data warehousing product that, while powerful, doesn’t address these needs. Put simply, right now, Snowflake is better on almost all fronts and for most businesses than Amazon Redshift. Here’s why.
Snowflake Makes Your Life Easier
Snowflake has invested in quality-of-life features — like how easy it is to share data and the user experience — from the ground-up, while Redshift is still trying to catch up. Even if all other aspects, such as pricing or concurrency, were equal (and they aren’t), this alone should tip the scale for most.
One big way Snowflake makes your life easer as a data person is that it make sharing data super simple. It’s about as simple to share data with Snowflake as it is to share a Google Doc.

On a technical level, this simplicity is made possible by Snowflake’s unique ability to copy databases within your own data structure and then grant instant read access to those databases (dive deeper into the documentation here if you want). Copying a database in a safe, secure way with Snowflake takes only one click, and it’s all self-contained. When you’re done, you just click “deprovisionize” and you’re good.
The alternative is the more traditional way of sharing data that Redshift represents. Redshift (and other traditional data warehouses) require that you go through the messy, insecure, and stressful process of managing multiple duplicate ETL (extract, transform, load) data pipelines. And with Redshift, you need to work with production data (😬) if you want to copy databases within your data structure. It’s flat-out riskier and more stressful.
We could go on and on here about specific features, but at its core, Snowflake takes care of the crap for you so you can actually do your job. One user on the r/bigdata subreddit described it like this when they first switched to Snowflake, “I was skeptical but [Snowflake] actually does seem to make performance management easier and allows me more time to actually work with the data.
”As you can guess, these quality-of-life improvements have made Snowflake their fair share of fan boys/girls, us included (can’t you tell?). If you work in data, Snowflake just makes your life better.
Snowflake Is Cheaper, but Not for the Reason You Might Think
Of course, the price of data warehouses depends on a ton of factors, but overall (according to our friends at Fivetran) Redshift and Snowflake will cost about the same. The true cost-savings come from the tighter infrastructure Snowflake can help you build.
The big difference in cost between Snowflake and Redshift is the fact that Snowflake was built to decouple computing and storage costs. Redshift has tried to go this route, but, again, it’s a game of catch-up. What this means is that storing data with Snowflake is cheap, and you pay only when you need to compute (i.e., use) that data.
Getting into the details, Snowflake uses credits whose costs fluctuate depending on the region you’re in — for instance, in the western United States, credits range from $2-$3. You can use these credits for computing purposes and other features. This credit system combined with relatively cheap storage costs — $40 per TB per month in the western U.S. — can help ensure that you pay for only what you use.
One slight downside is that with Snowflake you need to keep an eye on “credit munching.” Andrew Ferrier in the dbt Slack community described working with Snowflake like this
“On the flip side, we do munch through the credits, but most of this is due to optimizations that we can do on our side. One key tip here before deploying would be to think about setting up different types of processes on different warehouses, so that you can scale the warehouse according to need.”
Redshift’s RA3 allows you to decouple compute and storage costs as well, but most Redshift users have dc2, which doesn’t decouple. No matter what, if you want more space in Redshift, you need to buy more nodes, and it charges “per-hour per-node,” according to Panoply, which breaks down the formula like this:
Redshift Monthly Price = [ Price Per Hour ] x [ Node Cluster Size ] x [ Hours per Month ]
We’re getting into the weeds here, and others cover it more cohesively, particularly Clearpeaks. Our main point here is that, despite these nuances and formulas, the real difference in costs comes from the data infrastructure Snowflake can help you build.
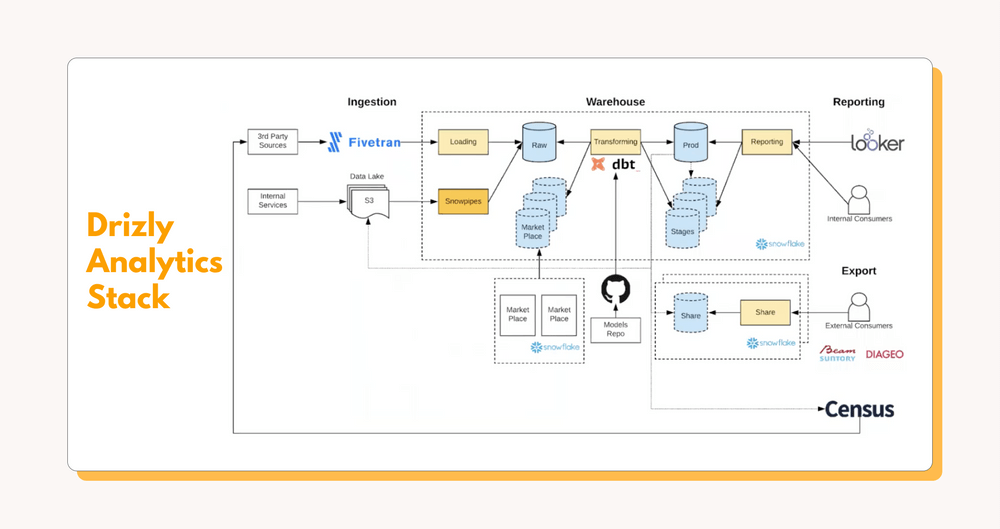
In their webinar with Fivetran, Drizly explains the evolution of their data team and data stack, which included a migration from Redshift to Snowflake. Their process was to spin up Snowflake parallel to Redshift and then slowly perform the Redshiftshift. When fully implemented, they were able to start cutting the fat in their data stack, relying solely on tools that do one thing really well. Their core stack ended up being:
- Fivetran for data ingestion that they don’t have to customize or babysit
- Snowflake for semi-structured data storage and easy data sharing
- dbt for transformations and a consistent modeling logic
- Looker for analytics aimed at the end business user
- Dagster for overall data orchestration
- Census to send transformed data back to source tools for operational analytics
On this lean foundation, Drizly can build the data stack they need as they need it, instead of spending time, money, and effort with one-off solutions or ambiguous third-party tools. In the end, even though a massive spike in data processed due to COVID-19 (Drizly delivers alcohol by mail; what do you expect?), their operating costs didn’t significantly change.
Snowflake Scales While Redshift Flails
Snowflake is built from the ground up to scale linearly, while Redshift simply doesn’t. Scaling this way is ideal for small startups looking to grow on a solid foundation of data. Trying to replicate this scaling ability with Redshift or other data warehouses can become prohibitively expensive.
If you have 40 minutes to spare, we recommend hitting “pause” and going to watch Alessandro Pregnolato’s, head of data at Marfeel, talk on addressing complexity at scale. His main point when it comes to Snowflake is that its ability to quickly and cheaply spin up virtual warehouses is a game-changer. He plays out the following scenario:
- If you have a query to run on a small machine (i.e., virtual warehouse) it might cost $3 an hour.
- It could take an hour and will cost $3.
- Or, with Snowflake, you spin up a machine that’s 10x bigger and costs $30 an hour.
- Then, it could take you 6 minutes and still cost $3.
Alessandro goes on to say, “I can take these monster machines and 5-hour queries and make them run in 10 minutes. And I pay the same.” Redshift can’t do this. Even if it could, the fact that its most commonly used version can’t decouple storage and compute pricing, running a larger machine would break the bank. You’re forced to move slower.
Another aspect of scalability is concurrency and the handling of real-time data. Snowflake does it better. But don’t just take our word for it. Sami Yabroudi from the Ro data team has a fantastic write-up about their Redshiftshift to Snowflake.
He echoes Alessandro’s point about spinning up computing resources: “Snowflake can automatically ‘spin up’ more computing resources and run all of the concurrent queries in parallel with zero drag on the execution speed of any individual query.“ Alessandro, for his part, just comes out and says, “[Redshift] doesn’t scale well in terms of concurrency.”
And for real-time data, Sami says, “With Snowflake, there is no performance impact if we have real-time data syncing - all data in our warehouse is current to within 30 minutes.” This fact was echoed just about everywhere people talk about Snowflake, from Drizly’s webinar to Alessandro’s talk to Medium articles like Sami’s. The point is, Snowflake is built to scale in the way modern companies scale.
Snowflake Is Flexible and Spry While Redshift Is ... Old
We’ve been pretty harsh on Redshift in this article. The truth is that Redshift has a well-established role in the data industry — and by “well-established,” we mean old.
Redshift was built to be cutting-edge in 2013. That’s the same year Thrift Shop topped the charts (if it’s that outdated, maybe it belongs in a thrift shop?). Seven years is practically a century in data-industry terms, and it hasn’t made many significant improvements since then — at least until Snowflake started eating its lunch. There are a lot of relics Redshift still carries around that keep you from being as agile as you need to be in the modern data marketplace.
For instance, Redshift incentivizes long-term commitments, which is just them trying to lock you in. To stay agile and up to date with the seismic shifts in the data industry occurring every quarter, you need a flexible data infrastructure. And Snowflake, right now, is the best centerpiece for that infrastructure, thanks to its scalability, storage of semi-structured data, ease of use, concurrency, and more.
But the important caveat here is that Snowflake may go the way of Redshift come 2027. And we’ll be making fun of the fact that Savage topped the charts at the time of its IPO. The point is that Snowflake is “that bitch.“ For now.
Convinced? Here Are a Few Things to Know About Migration
Migration from Redshift to Snowflake is a bit of a process, and there are a few quirks you need to keep in mind. There are, of course, nuances we can’t cover comprehensively here. But here’s a short list of things to watch out for:
- Audit your AWS (Amazon Web Services) credits. If you have enough on hand (which may be the case if your company is embedded with AWS), you can use them to buy Redshift at a much cheaper out-of-pocket rate than Snowflake. That said, you can also use AWS credits to buy Snowflake. As we covered a bit above, pricing is all over the place when it comes to data warehouses, and the AWS credits you already have can tip the scale one way or the other, budget-wise.
- Redshift and Snowflake have a similar SQL dialect (ANSI-SQL), but as one user in the dbt Slack community pointed out, “Watch out for timestamp with timezone fields. Very surprising things can happen.” It’s fairly seamless, but it’s not perfect.
- Snowflake’s credit-based pay-per-use model can take some getting used to and can lead to sticker shock, but, overall, you’ll likely get more value out of it. Nathaniel Adams, business operations manager at Stitch, described the cost change after switching to Snowflake as, “We’re spending more money on Snowflake. We could have upped our spending on Redshift, and likely would have gotten performance improvements, but we think we're getting more value from our spending on Snowflake.”
- There’s a bit of a shift in thinking that will happen when it comes to executing jobs. As Clearpeaks says in their comprehensive post, “Correctly sizing the warehouses will allow you to execute the jobs in less time at a similar cost.” This fundamentally changes the calculation of labor costs, computation costs, and on and on. You likely won’t see these benefits immediately.
To get a grip on these nuances, you can read Snowflake’s documentation, read Sami’s guide, watch Drizly’s webinar, or get involved with the dbt Slack community. No matter what, the transition will be unique to your business needs. We help a lot of our clients think through their own Redshiftshift, and we’d love to get on a call to discuss your options.