































Data activation is a critical piece of a new stack that turns your data warehouse into a Customer Data Platform (CDP) — AKA a “composable CDP”.
When building out the composable CDP, it can be tempting to look at solutions promising to solve every potential data problem. But the real value of a composable CDP is the composability, combining the products that work best for your business.
In this article, we’ll discuss the importance of investing in a best-in-breed data activation platform, why you’re thinking about ROI wrong, and why most “all-in-one” solutions won’t support your data activation needs.
Why Data Activation is so important for data teams
At this point, most data engineers have heard of the process of reverse ETL.
Reverse ETL is the process of syncing data from a source of truth like a data warehouse to a system of actions like CRM, advertising platform, or other SaaS app to operationalize data.
But reverse ETL is only one chapter in the much bigger data activation story. 📖
Data activation enables business teams to take action on data from the warehouse. It goes beyond traditional dashboards and reverse ETL to provide a warehouse-native way for business teams to activate customer data through tools like segmentation and audience management.
It’s the difference between simply looking at a static customer lifetime value (CLV) in a dashboard and actually sending a re-engagement email campaign to your highest-value customers. Better yet, it takes away the typical data team burden of building and maintaining customer pipelines and applications, while enabling business teams to activate and experiment with data much faster. ⏱️
When thinking about ROI, most data teams only factor in the requests for the data pipelines they are getting today. Don’t get me wrong: This number is still significant. Believe it or not, data teams often take more than a quarter to service the data requests of the marketing team. And when it comes to internal data roadmaps (hello, data migration 👋), they’re often delayed by 6 months because of ad-hoc requests that pop up.
But what they don’t factor in is the opportunity cost of the requests they are not getting. It’s likely that if marketing requests have been sitting in the backlog for a long time, most marketers will learn that there’s no point in even making that request. This loss of marketing agility compounds, resulting in lost revenue from campaigns never launched and advertising dollars wasted on ad platforms with the wrong data inside.
That's exactly why warehouse-native data activation is so important. It makes data teams less reactive and more proactive when it comes to enabling the data needs of their internal stakeholders, signifying an important shift for the data team – from builders to enablers – as the organization grows. It also reinforces the data warehouse as the source of truth for customer data in the organization and simplifies data governance strategies.
Read more about the benefits of the data warehouse as a source of truth in our hub-and-spoke article.
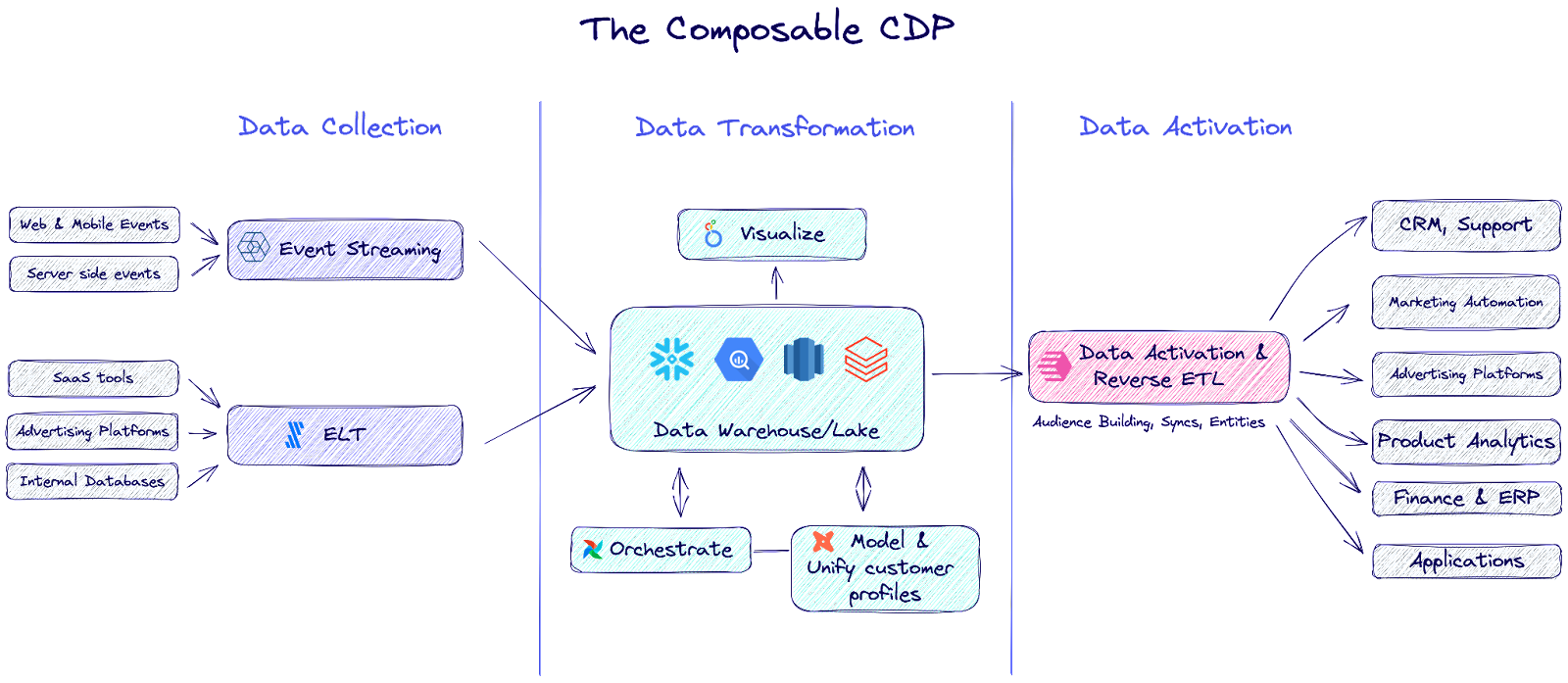
Why you shouldn’t compromise with an all-in-one CDP for data activation
If you’re sold on data activation and looking at building your own composable CDP stack, then you’ll know that your event collection architecture will be a key piece of that stack. 🔑 Data collection covers both batch ingestion (usually through an ETL tool like Fivetran) as well as event collection.
With the rise of digital transformation, most organizations have shifted to a more event-driven architecture to support the large volume of user events being collected. As a result, event streaming or collection can end up being one of the most expensive pieces of your data stack. 🫰 Generally, these tools have volume-based pricing models, which is exactly why you’ll see many large enterprises opting for open source or building streaming pipelines themselves.
When you’re thinking about building a composable CDP (where each piece of the stack is modular), it can be tempting to look for bundled solutions as a way to save money. But one of the more common dilemmas we see is data teams choosing between event collection tools with limited data activation capabilities or investing in a dedicated data activation platform like Census.
Companies may feel like it’s worth betting on an all-in-one solution that has strong data collection capabilities today (e.g. Rudderstack) in the hope that their data activation features might catch up in the future. But if we’ve learned anything from CDPs, it’s that the all-in-one dream has not lived up to its promise with only 1% of companies actually meeting their needs with CDPs (Forrester 2022).
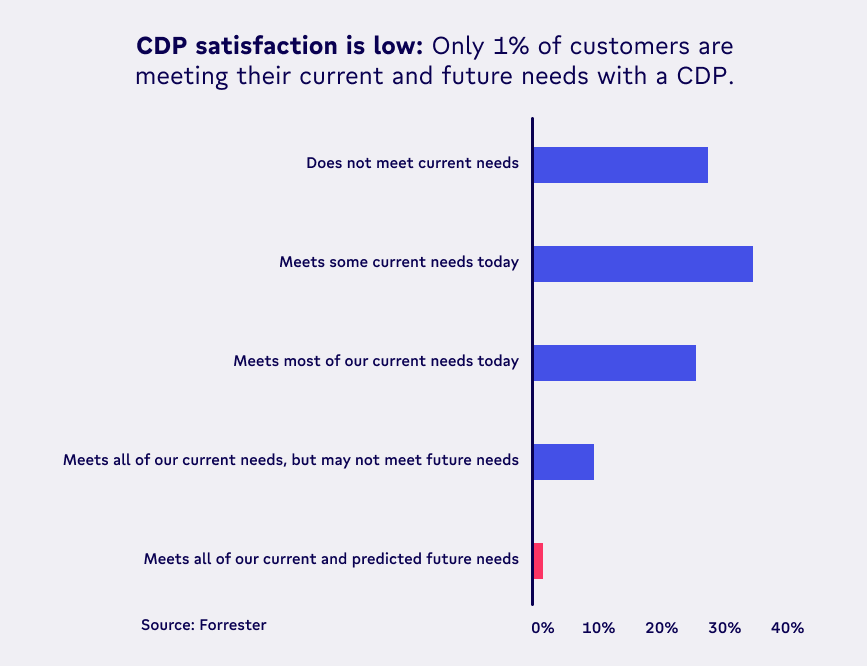
Tools like Twilio Segment and Rudderstack position themselves as all-in-one CDPs, but the reality is they are primarily event collection tools with limited other capabilities. 😬 Rudderstack, for example, is a data collection tool for developers that offers an extremely limited set of reverse ETL capabilities, and no data activation capabilities.
What we’re saying is: Ultimately, it’s a mistake to associate how much event collection tools cost with the value they generate.
Data is only as valuable as the business value it drives, so event data by itself is useless. Best-of-breed data activation tools like Census cost a fraction of your event collection budget but are an ROI multiplier by actually unlocking value from that data. 🔐 Better data results in increased campaign revenues, optimized ad dollars, and huge time savings for your data engineers.
But if that’s not enough, here are three key reasons why you shouldn’t compromise on an event collection tool for your data activation needs 👇
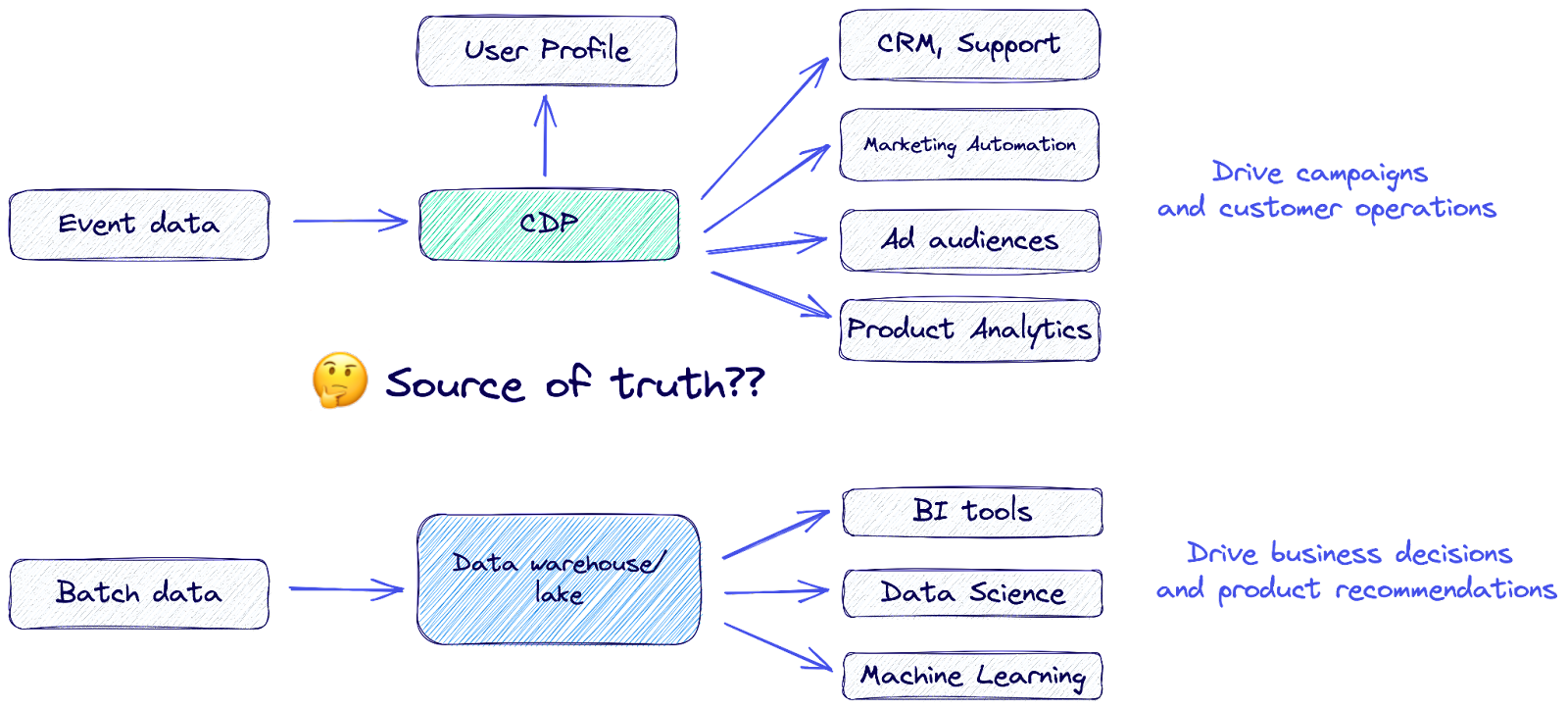
1. Event collection tools are not a source of truth for customer data 🙅♀️
Event collection tools stream events from either the client or the server, directly into downstream destinations, storage databases (like your data warehouse or lake), or their own proprietary database (as is the case with CDPs).
So, how you choose to architect your event streaming comes down to a fundamental question: Do you believe the data warehouse should be the source of truth for customer data?
If all your events are being streamed into multiple destinations directly from the source, that begs the question: Where is the source of truth? Although some might argue that the source of truth for an event is the moment it’s generated, where is the record for that source of truth?
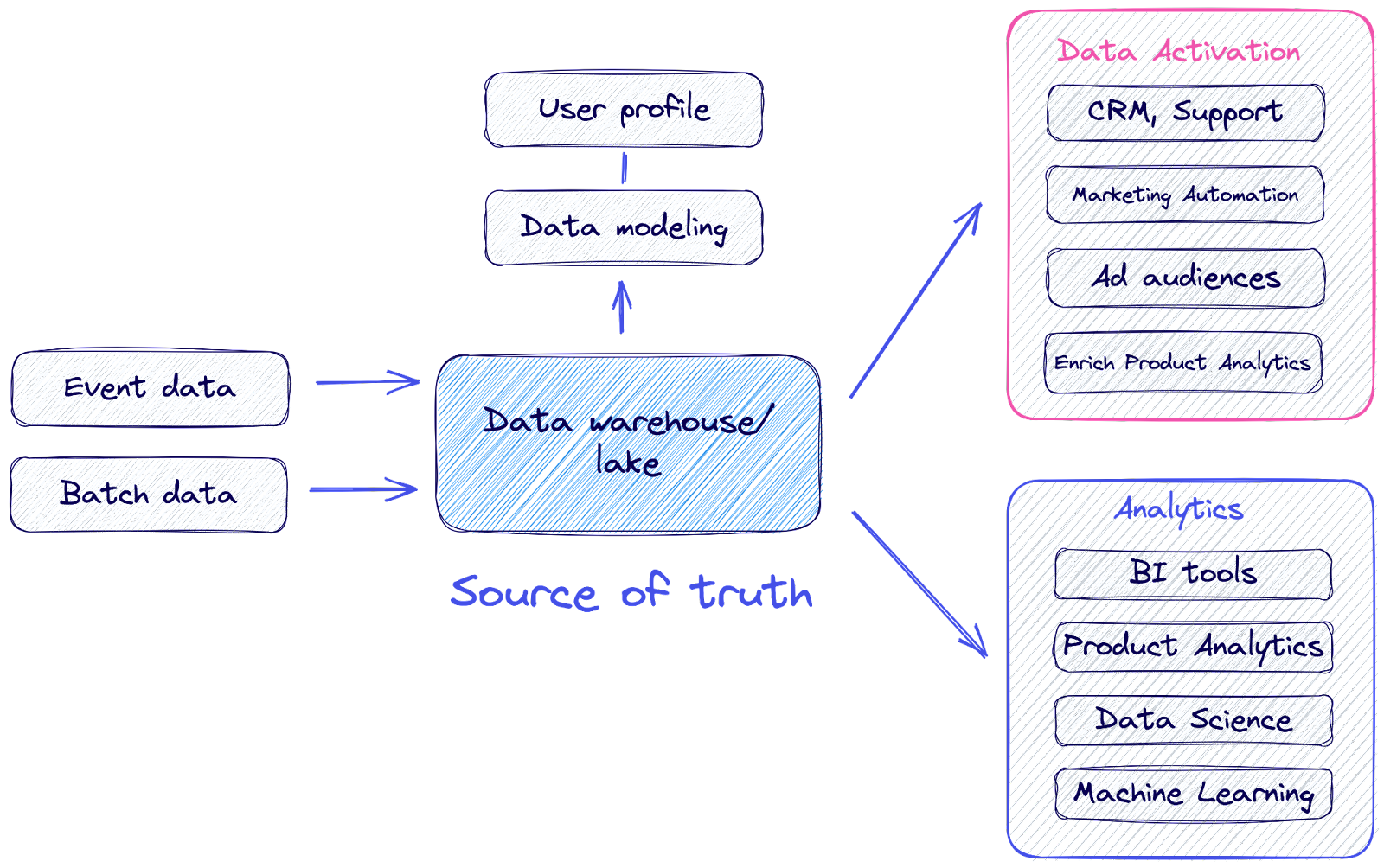
In a warehouse-centric architecture, the data warehouse is the source of truth (or record) for all events. All events are stored in the data warehouse, and most activation happens from the data warehouse. In this architecture, the data warehouse is not an unnecessary middleman – instead, there are several benefits to having your event data go through your data warehouse:
- You can define the data warehouse as the canonical source of truth for that event.
- You can model your data in infinitely flexible ways, using SQL or dbt. You’re not locked into any particular vendor’s modeling structure and you can merge event data generated from different vendors to simplify migration over time.
- The data warehouse gives you governance, observability, and security for free. And allows Data Ops best practices like git-based version controls.
- If you need to clean up or edit your historical event data, you always have that option (e.g. Google Analytics 4 migration).
Some of the data teams we’ve spoken to primarily raise these two questions about the warehouse-centric approach:
1️⃣ What about real-time use cases?
Well, exactly how real-time is your “real-time” use case? Data warehouses continue to get more and more sophisticated, especially in relation to streaming use cases.
In that sense, they are near real-time. The end-to-end latency from an event being generated to reaching a destination tool can be as fast as 5 minutes. Specialized reverse ETL tools like Census can even support “continuous” syncs, meaning they ping the data warehouse every 1-2 minutes to check if there’s new data to sync over.
There are very few true use cases where you need data within 5 minutes, but for those extremely low-latency use cases, you can use your event collection tool to stream events directly to your destination. In this case, we’ve seen most companies follow a hybrid approach, where only specific events get streamed directly into marketing tools to activate in true real-time, but those same events are also streamed into the data warehouse.
Keep a close inventory of those low-latency use cases, but ultimately, the canonical record for those events will still be the copy in the data warehouse. This is the record that will be used for analytical purposes and also the record that can be amended down the line if necessary.
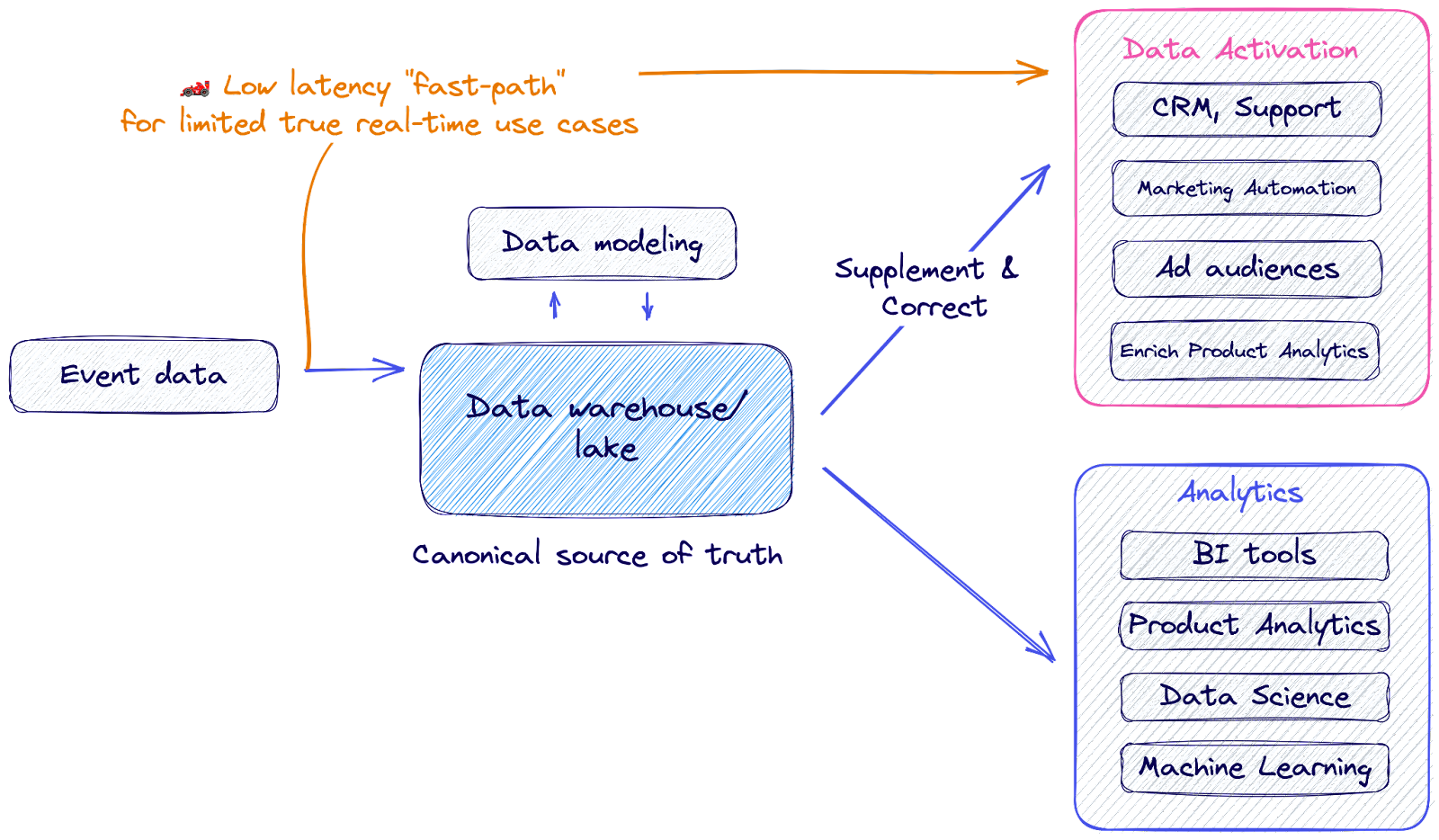
2️⃣ Does my data need to be modeled before I activate it?
Data warehouses require that you write data into an already-defined schema. Some data teams may be concerned that this step could slow them down since new event streams will need to be modeled before they are accessible for analytics.
Although this may have been the case before, advancements in data technology have made it so new events can be production-ized faster than ever (we’re talking a few hours after you start collecting them):
- Event collection tools like Snowplow handle a lot of the structuring and flattening of events into warehouse-readable schemas, so the data lands in an already-readable format in the data warehouse.
- Data teams have adopted software engineering practices like testing and version control to streamline production-izing data
- Data warehouses have increased support for JSON and other complex data types
But keep in mind – from a data governance perspective, it’s actually beneficial for the data team to have data producers model their data before it’s published since they understand the structure of their data the best. This follows the decentralized data ownership pattern outlined by Zhamak Dehghani’s data mesh approach: Decentralized teams adhere to a set of data modeling standards to enable the organization to more easily comply with centralized governance.
Remember: Time spent modeling data now saves 10x time in technical debt later on.

2. Event collection tools don’t have warehouse-native activation features
A core gap with a lot of data tooling is that they are designed to be used only by data people. Many tools tout themselves as being “self-service,” but what they really mean is that they’re self-service for data analysts who know SQL — not business users.
Event collection tools like Rudderstack do not have self-service data activation capabilities for business users, nor is it the main focus of their business. For example, Rudderstack does not have any audience-building or segmentation capabilities.
Specialized data activation tools like Census are unique because we have features designed for both data teams and business teams. We have robust version control, logging, and observability features for data teams, plus a visual segmentation interface for business users.

While CDPs that have a data collection focus – like Twilio Segment – do offer self-service activation features for marketing teams, these capabilities are not warehouse-native. They only operate on the silo of customer data that the CDP has collected, so getting data from the warehouse into CDPs is expensive and cumbersome. 😞
And even if you do get your data from your warehouse into your CDP, you’re stuck with additional data latency and another silo of data. Keep in mind that since CDPs are an all-in-one solution, that's reflected in their price tag. So while you can definitely purchase a CDP for data collection alone, know that you’ll be paying a hefty fee to only activate a fragment of your customer data. 💰
Event collection tools treat all integrations as event streams
Event collection tools have all been fundamentally architected the same way: For event streaming. Although streaming is often talked about as the future of data, not all use cases should be or need to be treated as event streams.
Sure, CDPs may be good at syncing raw event data to downstream destinations, but they’re poor at syncing transformed batch data and lack robust support for batch APIs. Rudderstack, for example, has limited support for bulk APIs, event endpoints, list endpoints, or even updating custom objects downstream. 🌊
This makes it impossible to activate data in various common formats (such as updating more complex CRM objects, or syncing lists to advertising platforms). Rudderstack also only supports two behaviors: Upsert and mirror, meaning they don’t support non-destructive sync behaviors like ‘update only’ or ‘create only.’
Treating every use case as an event stream creates a data firehose problem and forces you to sacrifice control over what data is synced. 🚰 By syncing all the available data into your downstream tools you may be inadvertently driving up costs – since many downstream tools like Braze charge to store data – while simultaneously creating multiple copies of the data with no governance. Many data teams prefer to have the data warehouse in the middle so they can ensure data quality and control what data is being synced to downstream tools.
Warehouse-native data activation tools, on the other hand, are purpose-built to sync data from the warehouse to downstream tools at scale. This means they have robust support for bulk APIs and give you more control over what data gets synced.
With Census, you can sync any custom object, customer list, or behavioral event data to your downstream business tools. You can even sync data directly to file systems like SFTP and send notifications to your favorite messaging platforms (i.e. Slack). Census supports several sync behaviors like ‘upsert’, ‘update only’, ‘create only’, ‘mirror’, and ‘append’ – all while providing robust warehouse-native observability on all requests.

Do I need an event collection tool before I buy data activation?
If you have no event collection set up at all, we do recommend that you first choose the event collection solution that is best for your needs before looking at data activation.
That being said, many organizations already have some level of event collection in place and may be looking at replacing or upgrading their existing event collection solution. At this point, it’s important to ask yourself, “What is the biggest challenge my organization is facing today?”
If you already have some level of event collection in place today, don’t fall into the trap of “data perfectionism” – believing that you need to collect more data or model it to perfection before you start activating it.
The reality is that 73% of company data isn’t being used today and data activation unlocks more value from your existing data. Once you learn how business teams want to use data, you can make more informed decisions on upgrading your data stack.
Start activating data today ✅
Get started with putting your data into action with a small use case. For example, you could work with your marketing team to come up with a list of 10 high-priority audiences that could be used for new campaigns. That can be something as simple as targeting your rewards program customers with more than 2 orders in the last 2 months with a special promotion.
The key, though, is to expose whatever data you have to your marketing tools using a best-of-breed data activation platform like Census. ✨ Start a free trial today to see how easy it is to connect your data and start activating it in minutes.
Don’t compromise on data activation. The benefit of implementing a best-of-breed data activation platform on your data warehouse now is that it will be agnostic to whatever data collection solution you have now or in the future.
Learn more about how Census can help you activate your existing customer data today. Book a demo with one of our product specialists to see how we can help you build granular audiences, and sync customer data to all your marketing and advertising tools without code. 💪