































Businesses need data to need to drive more conversions. But expectations and regulations around user privacy are rising – and rightfully so – which can make it hard to meet both performance and privacy needs. That, paired with all the buzz around reverse ETL might have you wondering:
Should I add a server-side tag manager or reverse ETL to my stack?
What about both? 🤔
In order to answer this question, you need to compare your options.
Wait a second, we can compare server-side tag managers and reverse ETL?
Yes, we can. Allow me to explain.
But first, let’s start with some definitions to make it easier for us to draw comparisons between both solutions. 👇
What is a server-side tag manager?
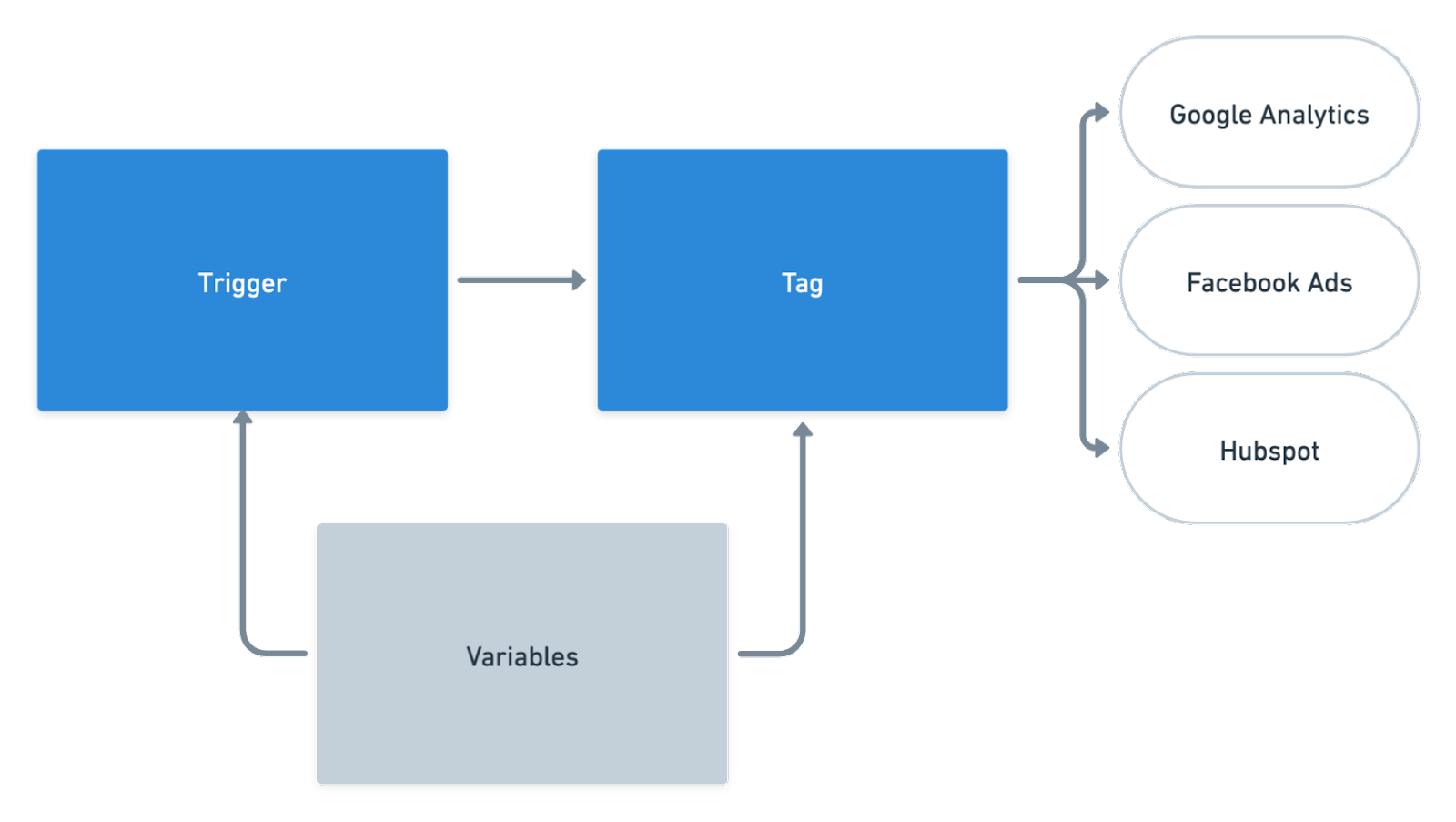
Let's start with what you can do with a tag manager in general (client- and server-side):
- It's a central place where you define which destinations you want to send data to
- You can define when something should be triggered in the code of your website (i.e. if someone clicks on "add to cart")
- Everything happens in real-time. User interaction triggers a tag, and the data is immediately sent.
|
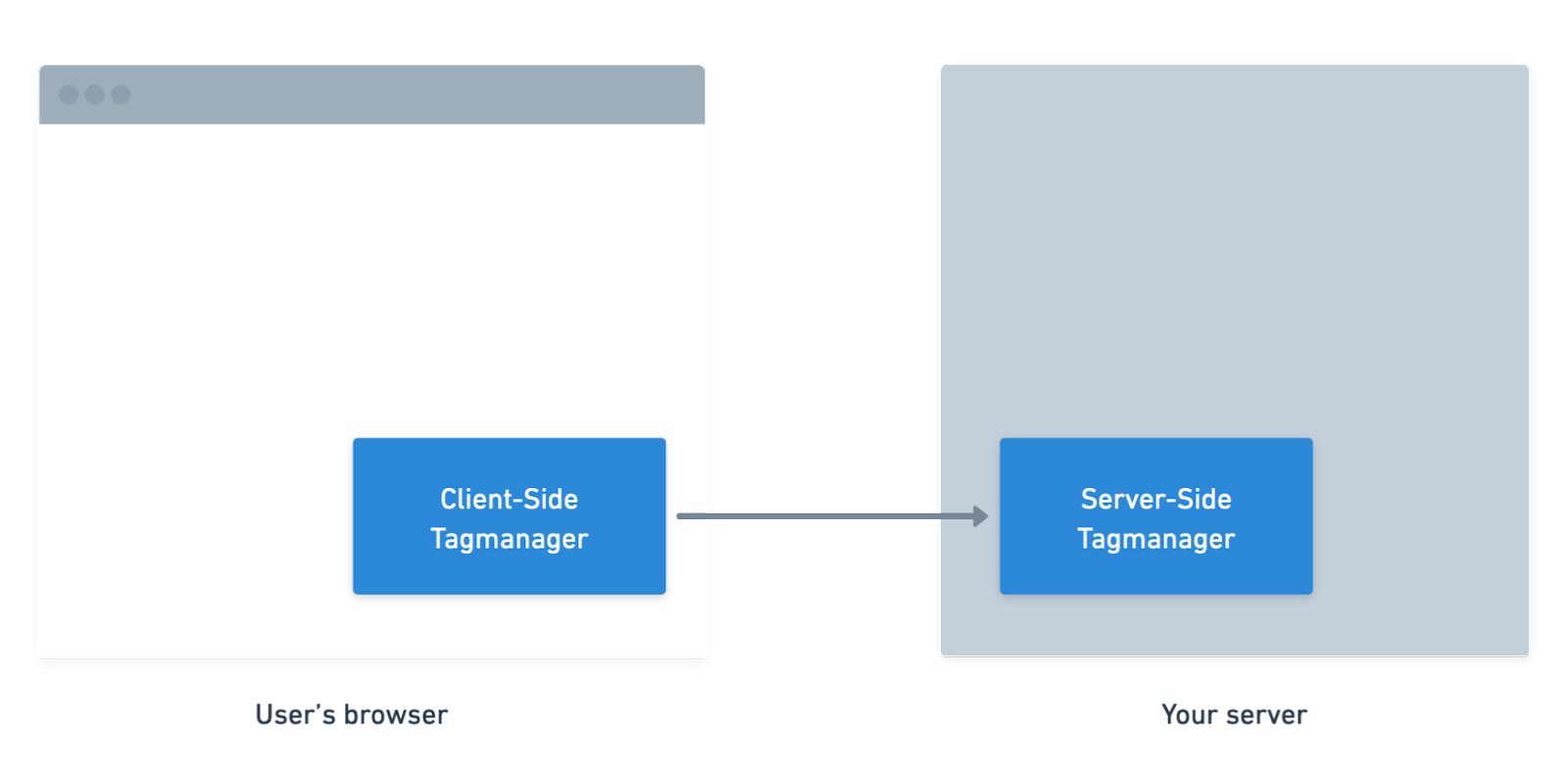
Now, what makes a server-side tag manager different from a client-side tag manager?
There’s one key difference: The client-side tag manager runs in a user's browser, while the server-side tag manager runs on your server.
What does that mean for you? Code that runs in your browser is inherently less reliable since your browser can block things, or the network connection can be reduced.
Also, it can allow advertisers to inject faulty Javascript in their code (that you add in the tag manager) and send your data to different places — especially places you likely have not agreed to. Or it can track form inputs, user interactions, and submissions and collect sensitive business data.
Ultimately, the server-side tag manager gives you more control over your data because:
- You send the data to a defined API endpoint and not to places you don't know about
- You can remove data you don't want to send to ad platforms (like your personal information).
- You can load and send data asynchronously to reduce the load from the browser
- You can enrich data with sensitive information (like profit margins of products) without it being visible to website users
|
Right now, however, the server-side tag manager still needs the client-side tag manager because
- Not all ad platforms support sending data from the server side
- Some data is only available on the client side (like scrolling)
So, today, you'll always see both versions working in tandem. The client-side tag manager collects user interaction and sends it to the server side, and from there, the data is sent to the final destination (analytics, ads, CRMs).
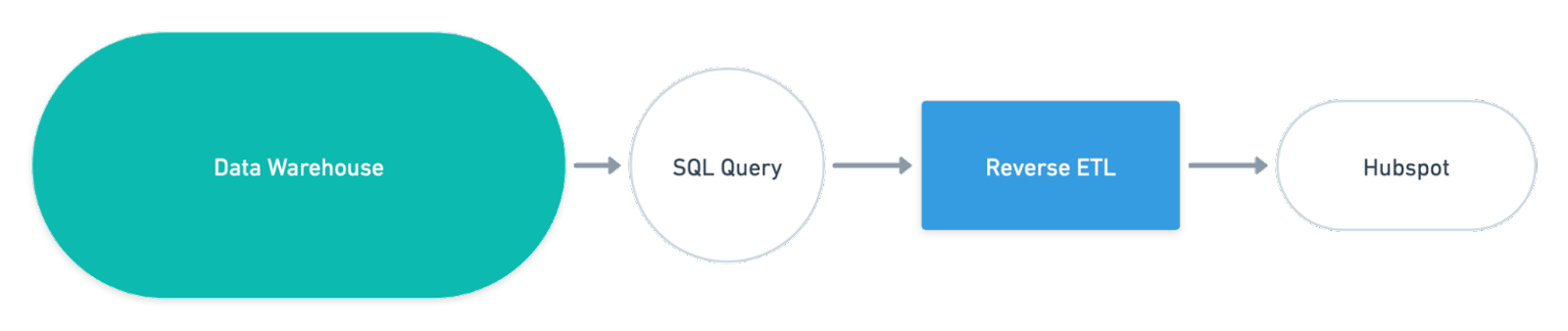
What is Reverse ETL?
Reverse ETL describes the process of loading data from an analytical database into destinations (like CRMs, customer service, and other databases). So, what makes it reverse? ⏪
History. Classic ETL loads data from sources like an application database or a CRM in an analytical database; reverse ETL is now the other way around. In the end, both are ETL, but the "reverse" descriptor identifies the specific process from the analytics database to a destination.
|
Here’s a simple example of what you can do with a reverse ETL product like Census:
- Identify and gather the data you want to send to a destination, either by selecting a table or by writing a SQL query
- Select the destination this data should be sent to (like a CRM)
- Define the identifier in the destination the data should be matched against (like the customer ID)
- Define the fields to which the column values of the query should be added
- Run the sync and schedule it (this is usually done in batch runs)
How server-side tag managers and reverse ETL compare
As you’ve probably noticed, server-side tag managers and reverse ETL deal with similar concepts. But which one is better for your use case?
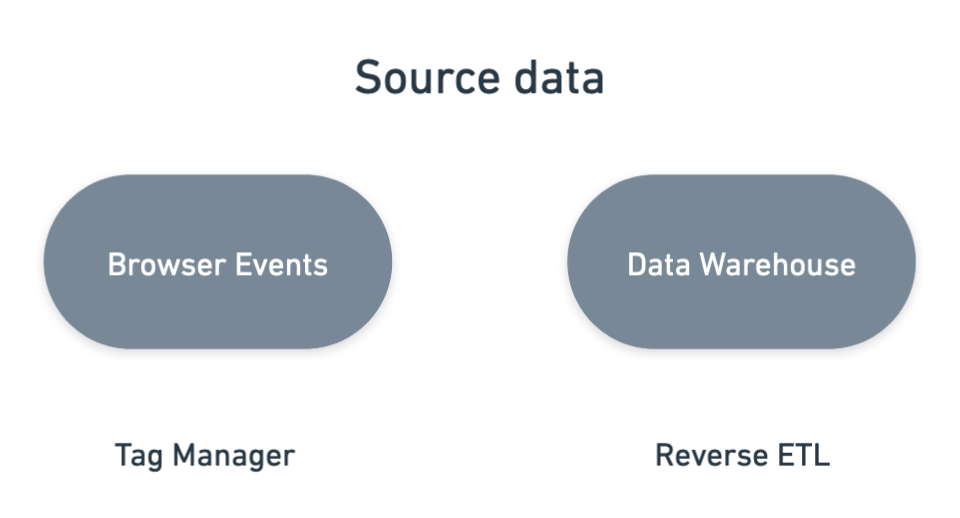
Source data
In the server-side tag manager, we get the initial data from the client-side tag manager which collects it from the website. The downside is that this data is often limited to what is visible on the website. 🔍
In reverse ETL, we get the initial data from the analytical or application database by running a query which can be extensive depending on what data has been added to the database.
What can happen when you pull your data straight from the warehouse? Check out how Coalition uses reverse ETL to provide secure, clean access to data.
|
Destinations
The server-side tag manager maps the data to the destination's endpoints based on their API definition. But to do the mapping, you may need to write some custom Javascript code. Also, the server-side tag manager can send data using predefined configurations (aka tags) to custom HTTP endpoints (not supporting complex authentication).
Similarly, reverse ETL also maps the data to the destination's endpoints based on their API definition. To do the mapping in this case, you’ll usually need to write a custom SQL query.
It can also either send data to predefined configurations (AKA destinations) or to a custom destination using Census's Custom Destination feature.
To see how this works in the real world, check out how Prolific supercharged its new Sales team with data in Hubspot using Census.
 |
Syncs and schedules
The server-side tag manager runs based on requests. When the client-side tag manager sends data, the server-side tag manager passes it on to the destination in real time. But it can only pass on the data it gets (with small enrichments); there’s no way to do historical syncs.
Also, the server-side tag manager has no fail handling. When a request fails, it can't be recovered and retried, so constant monitoring and alerting are essential. Unfortunately, though, it doesn’t come with these features out of the box. 📦
On the other hand, Reverse ETL usually runs in batches at defined times — commonly, this is every hour or every night —and it can sync all historical data into the destination and continue to update incrementally based on inserts and updates. Plus, with Reverse ETL, there are usually options to implement fail handling, like retries and validation – and it even comes with inherent monitoring and alerting as an added bonus.
Curious about how these alerts work? See how Bold Penguin reduced support response times from 24 hours to 30 minutes with operational Slack alerts.
|
Okay, so when should you use server-side tag managers and when should you use reverse ETL?
As you probably gathered, there are three significant differences between the two:
- Server-side tag manager can handle requests in real-time and pass the data to the destination
- Reverse ETL can load historical and more extensive data
- Reverse ETL can ensure data sync and delivery
So, let's break this down into actionable use cases:
👉 Use server-side tag manager for all things that need streaming in real-time (like tracking events) or near real-time (like welcome emails). You could also use this for onboarding notifications, but primarily use it for tracking purposes.
👉 Use reverse ETL to sync extensive data regularly to a destination. If you use it for data enrichments like enriching your CRM with usage, financial, or configuration data, you can re-use it for better pipelines and targetings.
- Your sales team can use enriched contacts data in Hubspot when you extend it with usage data, such as logins or features used. This enables them to make decisions about priorities based on a prospect's intent to buy and create marketing automation based on synced data.
- Your support team can work with extended product usage and customer data to make better decisions about priorities and act on more context that usually needs to be pulled together manually.
As you can see, both services can go hand-in-hand and cover different use cases. 🤝 For example, the tracking data that the server-side tag manager collects can be enriched, qualified, and then passed on to a CRM with reverse ETL to see if a lead has checked the pricing page at least four times.
TLDR: It makes sense to invest in both products to pass data from different sources to different destinations. Bringing the right data into the tools where your different teams work every day can unblock extensive productivity gains.
✨ Want to start operationalizing your data to unlock its potential? Book a demo with a Census product specialist.