































Product-led growth is a game-changer for RevOps – you can make the most of your data ecosystem, maximize the impact of your operational tools, and drive better outcomes.
But that doesn’t mean that it's free of challenges. 😬
Luckily, some pretty knowledgeable folks let us in on some of their tips during our recent webinar, Driving Product-Led Growth with your RevOps data stack. It featured a few awesome RevOps-oriented leaders who get their hands dirty in the revenue and growth landscapes daily:
- Henry Mizel, VP of Revenue at Apollo
- Cyril Marques, Founder & CEO of Montreal Analytics
- Sylvain Giuliani, Head of Growth & Ops at Census
Watch the full webinar below 👇
Together, Henry, Cyril, and Syl shared learnings and examples of how to build a data stack that enables PLG companies to leverage data that directly impacts their revenue goals. 💸
Product data enables you to reach customers at the right time
In RevOps, it’s critical to have a complete 360° view of product usage. Enriching your customer accounts with context from all of your internal customer data enables your sales team to prioritize the right accounts, while your customer success team prevents churn and drives upsells.
By using the customer’s actual product usage, your teams can have more authentic conversations that revolve around a customer’s real, demonstrated needs. Henry let us in on a few of Apollo’s use cases demonstrating the results of more authentic customer communication. 👇
- Improving outbound conversion rates with product data. By adding product behavior to outbound emails, Apollo increased their conversion rates 10X to over 5%.
- Automating upsell alerts when users hit feature gates. When Apollo users hit feature gates inside the product and don’t convert, that behavioral data is sent to Salesforce and Apollo and triggers both automated and manual tasks for the sales and customer success teams to follow up.
- Product-qualified lead (PQL) scoring to prioritize leads for the sales team. Apollo combined context from all their leads’ activities to identify which leads were most likely to convert, resulting in a better-equipped sales team.
📈 For more examples of how you can use your product data to drive revenue, check out these use cases from some of the best PLG companies.
All these use cases show that when you use your product as the main vehicle to acquire, activate, and retain customers, you empower product-led growth. So, let your potential customers try your product for free or for a small fee, realize the value the product is providing, and then bring them into a sales cycle.
“As new users sign up, you want to measure how far along they are in the process towards realizing the value that your product is bringing. And when they do achieve those values – or as we call it, achieve the ‘AHA’ moment – it's really about getting that information to your team and enriching your CRM,” Cyril said.
How do you decide what product data to use?
Product analytics can help you answer questions like:
🎯 Where is a specific user on the journey?
🎯 Are they just signing up, or have they triggered some feature?
🎯 Have they used a bunch of different tools and features on the platform?
🎯 Are multiple users from the same company using the product?
🎯 Do they have a lot of usage in a short amount of time?
All this data is specific to your organization, your niche, and your customers. While we might wish it were as easy as flipping a switch, there’s no standardized set of product metrics for every company.
“I think, zooming out, there isn't a one-size-fits-all approach to PQLs, and I think that's kind of the definition of it, right? It's specific to the business, it's specific to the tier and the segment that you're working on, and where the customer is in the funnel,” Henry commented.
Start by looking at your existing customers' user behavior within your product so you can start pulling out actionable information, Henry recommended. Ultimately you’re looking for signals to help decide:
Is this person potentially either a current or future customer champion for you?
Can they help you drive adoption and engagement with your product within that organization? Or are they too early in their journey and need some support or intervention from the sales team?
By timing your interventions appropriately according to these details, you can maximize the value that you give your customer in parallel with them realizing the core value of your product during their ‘AHA’ moment. 💡
Product data is often siloed
The problem is, historically speaking, your product data is siloed. Your stack might be composed of dozens of tools, with each tool carrying different data about your customers. And, when none have the full picture, all your valuable product data isn't getting to the teams who need it.
So what’s the solution? Bringing your data into a single source of truth – your data warehouse. When Apollo worked with Montreal Analytics to implement the modern data stack, they were able to centralize their data in Snowflake and activate it in their GTM tools.
Apollo started this process with three goals in mind:
- They wanted deeper product usage insights for their GTM teams
- They wanted to future-proof their data stack. PLG means they had a “firehouse” of users signing up for their free trials, and Apollo didn’t want all of these in their CRM.
- They wanted to make the warehouse a system of record for the customer.
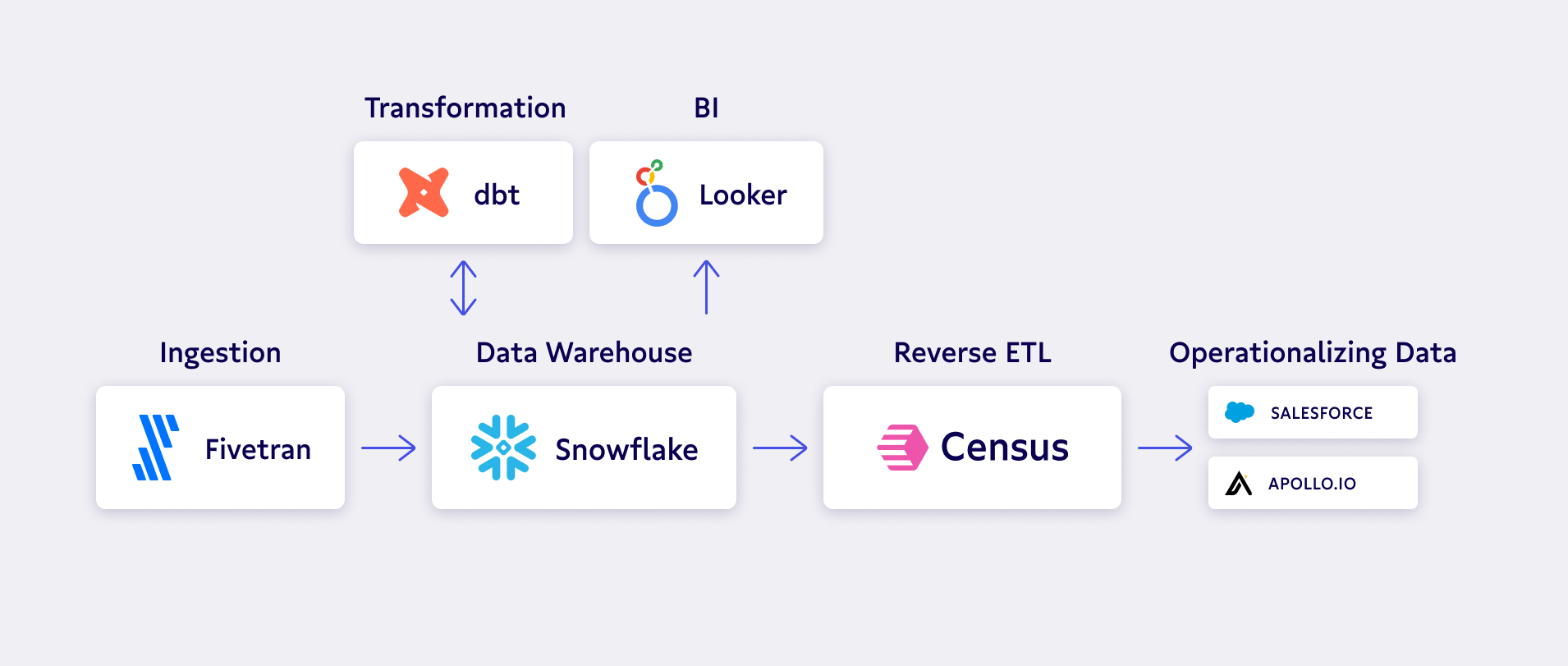
With these goals as their North Star and Montreal Analytics to guide them, they needed one final piece of the puzzle: Confidence in their data. 🧩
Product data isn’t all there is to it. You need confidence in that data
It’s one thing to have access to your data, but it’s another thing entirely to have confidence in that data. Data needs to be reliable to be actionable. So, you need a single source of truth and a governance plan to make that data trustworthy.
Once you’ve centralized your data in the warehouse, you need to model that data (join your product, marketing, and sales data) together and focus on the metrics that matter for your business. Cyril calls this “giving an opinion to your data.”
There’s a lot to it. How do you start?
Cyril recommends adopting an agile product approach to activating your data: Don’t try to build everything at once. Start with bite-sized pieces, and determine priority based on the project sponsor. For example, if your sponsor is the Head of RevOps, the highest priority should be getting data to the revenue team.
Start by bringing a couple of sources into your warehouse, then model it and train your team on that data. You can iterate to get exactly what you need. 🔁 But it can still seem a little overwhelming at first, especially when you realize you need to balance time to value, data quality, and breadth of scope.
“Data quality is very important. So if you want to go fast and take shortcuts, know that you don't get a lot of shots to get adoption from non-data people on the data itself. If at some point you bring in some data and people realize that the data is not accurate, you've lost a ton of trust, and it's going to be a journey to bring that trust back,” Cyril warned.
Work on getting solid foundations in place first and then build on those foundations versus trying to boil the ocean. 🌊 Keep in mind: A tool alone won't solve your problems, so start by nailing down your roadmap and deciding on tools based on where you want to go (instead of letting your tools dictate your path). From there, you can see tremendous effects.
PLG needs lots of experimentation and iteration
Personalization with product data increases conversion rates since you can now reach out to the right person at the right time – but product data alone won't always lead you to the right place. After all, having all the quantitative data you need doesn't mean you have the context behind it.
PLG involves a lot of experimentation. You won't necessarily hit it out of the park the first time. ⚾ “So, take your North Star, take your business goals as a company and go into the data and figure out what success is for your users,” Cyril proposed.
As Henry mentioned, “PQL scoring evolves over time,” – but you can’t evolve if you don’t start somewhere. A solid foundation with trustworthy data will enable your organization to be agile and experiment with how to effectively activate that data across the business.
✨ Want to start operationalizing your data to drive product-led growth with your RevOps data stack? Book a demo with a Census product specialist.