

































Five years ago, Customer Data Platforms (CDPs) started gaining popularity by marketing themselves as an all-in-one solution to collect, unify, and activate customer data. But let's be honest: They failed.
Customers who adopted off-the-shelf CDPs have long since struggled with their rigid data models, long onboarding times, and redundancies across analytics and marketing tools with only 1% of companies actually meeting their current and future needs with CDPs. 😬
Now, the rise of the modern data stack and data activation means that companies have access to best-in-class solutions for each component of an off-the-shelf CDP. As a result, the Composable CDP has emerged as an ideal solution for data-forward companies looking to maximize their existing data investments. 📈
In this post, we’ll discuss off-the-shelf CDPs, the rise of data activation, and how to turn your existing data platform into a Composable CDP to start getting value in your organization today.
But first, WTF is a Customer Data Platform and why do people buy them?
A Customer Data Platform (CDP) is an all-in-one platform built for marketing teams to collect, transform and activate customer data. The number one reason why marketing teams are rushing out to buy CDPs is to get a unified view of their customer, with 63% of marketers saying that unifying data is their key challenge.
There’s a lot of variety within the CDP category, but generally, all CDPs have (at least) these three components: Data collection, data transformation, and data activation.
You might be thinking, “Hey, these components sound mighty familiar to those of the modern data stack” — and you’d be right. The CDP provides a lot of overlapping functionality to that of the company’s existing data platform. So... Why do data teams want them?
In our experience, there are two scenarios where data teams are looking at CDPs 👇
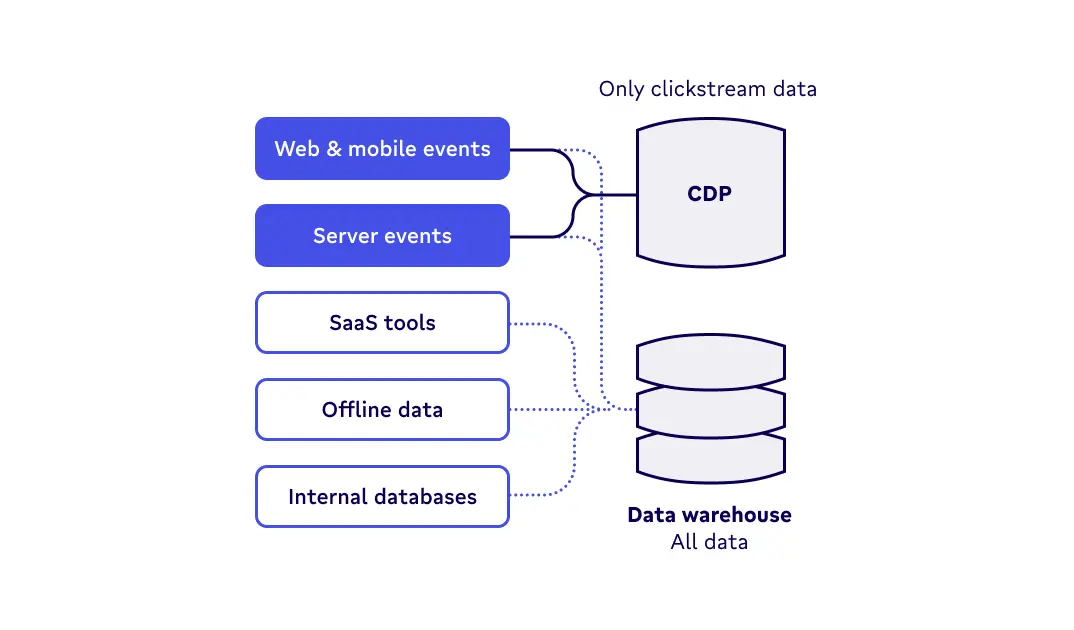
- For their event collection features. CDPs like Twilio Segment started as event collection and tag management tools. As a result, they offer incredibly developer-friendly APIs that make it really easy to track new events. The biggest downside to this is that because they are an all-in-one solution and have a volume-based pricing model based on Monthly Tracked Users, they quickly become very expensive for companies with many customers. This makes all-in-one CDPs a very expensive event collection solution – especially with other more cost-effective options in the market like Snowplow.
- Because their marketing team wants to buy one for data activation purposes and needs them as part of the evaluation and implementation process.
The biggest problem: CDPs are yet another copy of your data
The biggest problem with CDPs is that they claim to be the single source of truth for customer data, but they do not (and cannot) replace data warehouses. Why? Simply because CDPs don’t have all the customer and company-level information to be a complete source of truth for analytics.
Instead, data collected by CDPs is copied to the data warehouse to power trusted analytics, instantly diluting the CDPs' promise of a “single source of truth.” While some CDPs are now supporting importing data from the data warehouse, doing so results in additional data latency and still doesn’t solve the fact that the CDP is still just another silo of data. 🙄 Due to this fragmentation, data inside the CDP is not as trusted or fresh as in the data warehouse.
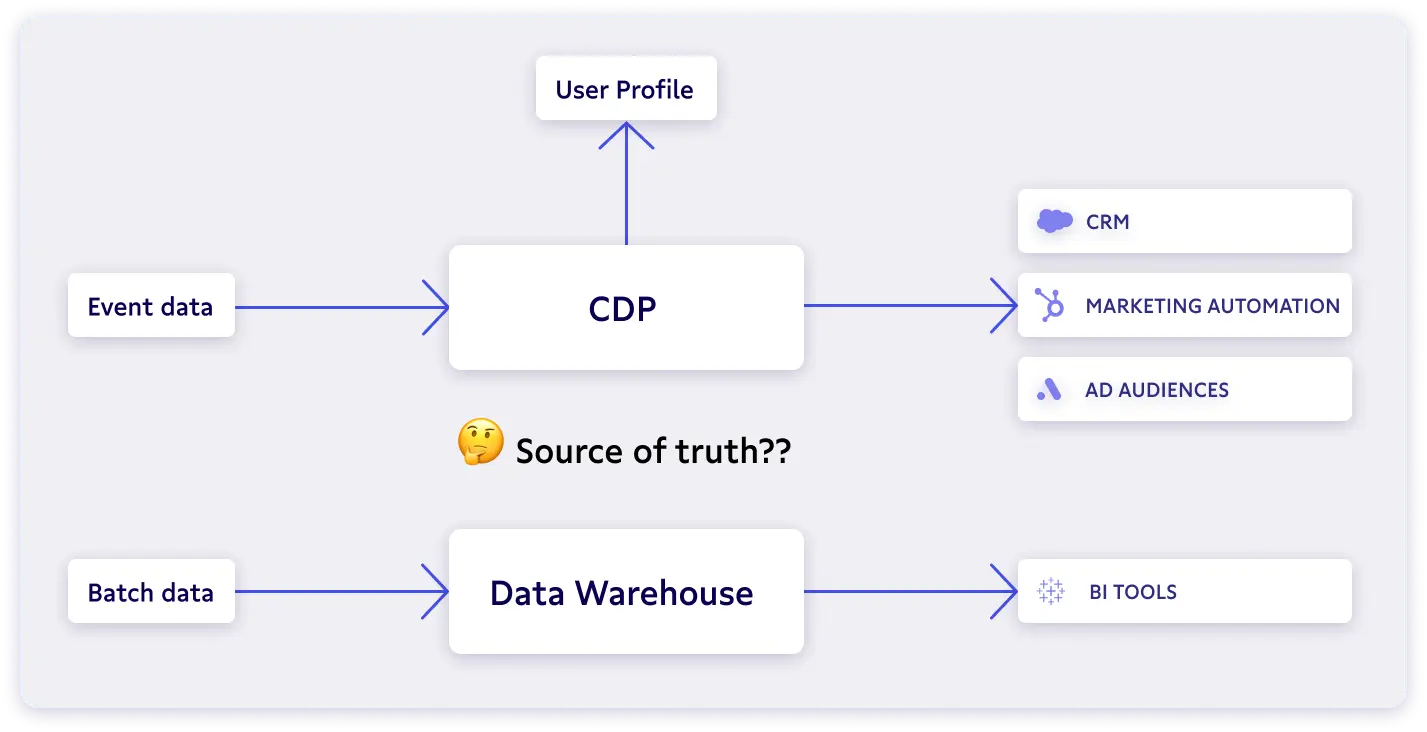
Why you don’t actually need a CDP (if you have a data warehouse)
If there’s one tool that can claim that it’s the “single source of truth” for customer data, it’s the humble data warehouse. Most growing companies are already investing heavily in data warehouses to power analytics and reporting. Plus, advancements in the modern data stack with transformation tools like dbt and the DataOps movement have made the data warehouse a hub to operationalize data.
In fact, the data warehouse has become the place where:
✅ All company and customer data lives
✅ Data is most trusted as it’s maintained by data teams
✅ It’s well governed (by data teams)
✅ Data is secure by default

At Census, we believe the data warehouse has won as the source of truth for customer data. We also believe that many of the components of a CDP already exist inside a company’s data platform. So, let’s break it down 👇
- Data Collection. Engineering and Data teams have already set up robust data collection to collect vast quantities of behavioral (e.g. product, web analytics), operational (CRM), and transactional data (orders, subscriptions) on customers. These are either being streamed directly into your data warehouse (in the case of behavioral data) or being consolidated via ETL in the data warehouse.
- Data Transformation. Once the data is in the warehouse, data teams are already cleaning, joining, enriching, and flattening this data to make it consumable by analytical tools. For example, data teams need to unify many different tables of customer data across the organization in order to break down Customer Lifetime Value (CLV) by each individual customer ID.
So the collection and transformation pieces are already happening inside your organization – and the data warehouse has emerged as the most complete single source of truth for customer data. Today, however, the most common destination for this single source of truth is a dashboard. But dashboards are where data goes to die because actually activating those insights still requires complex pipelines and engineering effort.
This is where warehouse-native data activation comes in. 🦸
Data activation is the missing link 🔗
Data activation is the missing link needed to connect the data collection and transformation efforts of the data team and make that data accessible to marketing teams to activate across all their channels. Warehouse-native data activation tools like Census enable marketers to unlock data directly from the warehouse – all without needing to know SQL — while still enabling data teams to maintain governance and control that comes from being built on the data warehouse
These warehouse-native activation tools enable marketers to:
- Sync customer attributes and lists from their data warehouse into “systems of action” such as Salesforce Marketing Cloud, Marketo, and Hubspot, and update them in real-time as the data is transformed. This pattern is known as reverse ETL.
- Build dynamic customer (and other entity) segments by filtering across trusted data models from the data warehouse and syncing them to all their advertising and marketing automation platforms from a single place.

In conjunction, data teams can:
- Automate reverse ETL pipelines to sync data to downstream tools used by business teams.
- Define approved entities (or business objects) for marketing teams to activate. For example, they can define the underlying approved “users” and “events” tables that marketing teams can use for audience building.
- Maintain full governance and control of all customer data leaving the warehouse with robust logging, observability, and access control features.
TL;DR: Warehouse-native data activation tools (like Census) bridge the gap between marketing teams and data teams and fundamentally change the way data and marketing teams collaborate.
What about real-time use cases?
Up until recently, the biggest limitation of the data warehouse was the inability to perform real-time, high-speed use cases. Warehouses were designed for batch processing with high accuracy and scalability, but as a result, they were too slow for use cases like geotargeting and cart abandonment.
That meant that businesses had to implement their real-time use cases without the data warehouse by building a separate fast path, through custom infrastructure and event buses, CDPs, or iPaaS — all with painful limitations such as lack of scalability, data silos, and low adaptability. Modern business teams want to leverage the data warehouse to power their operations, but warehouse latency was one of the last barriers blocking adoption.
Last year, Census introduced Live Syncs to tear down the latency barrier. Live Syncs activate data from data warehouses in single-digit seconds, enabling companies to use the same data infrastructure for all use cases at any latency. The best part is, Live Syncs can be 100x faster and 100x cheaper to operate than traditional Reverse ETL, making real-time use cases more easily accessible to every business.
The Composable CDP: Bridging the gap between marketing and data teams 🤝
The composable CDP is a best-of-breed solution that serves as an alternative to buying an expensive all-in-one CDP for data-forward organizations. Now, data teams can turn their existing data platform into a CDP by adding the data activation layer since CDPs duplicate a lot of the functionality of the company’s data platform.
This alternative approach to a CDP is known by a few names: Composable CDP, unbundled CDP, headless CDP, etc. Although the name might differ depending on who you’re talking to, they are all ultimately saying the same thing: Use your data warehouse as the source of truth for customer data, and activate data where it already lives.
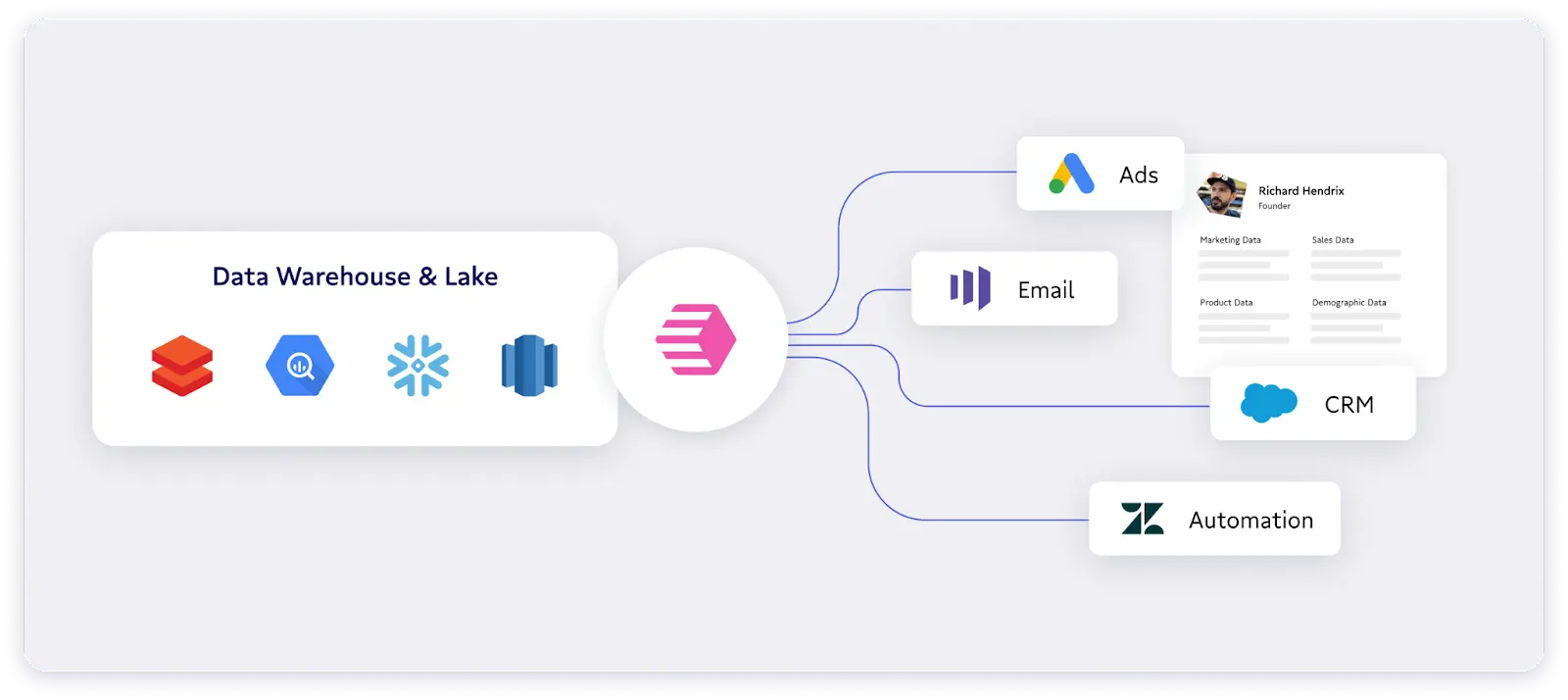
Building a composable CDP with data activation
Typically composable CDPs have the following components built on top of the data warehouse or lake.
Data Collection:
- Event tracking (e.g. Snowplow): Capture rich, quality behavioral data across all platforms and channels in a common format and stream it into your data warehouse or lake. Notably, we don’t recommend Segment or Rudderstack in this category purely from a cost perspective, as both of these companies position themselves as all-in-one solution providers and end up being more expensive down the line.
- ETL (often Fivetran): Replicate data from your SaaS tools and databases across marketing, sales, finance/IT, product, etc. into your data warehouse.
Data Transformation:
- dbt: Once all your raw data has landed in your data warehouse, you can use SQL to clean up and transform the data into clean tables/views.
- BI (e.g. Looker or Sigma): Enable business teams to aggregate or filter customer data in a visual way, or analyze insights from marketing activities.
Data Activation:
- Census: Sync data from the data warehouse into the tools that business teams rely on (e.g. Salesforce, Marketo, Facebook Ads, etc). Enable business teams to build self-service segments and audiences leveraging all of the rich data available in the data warehouse.

Benefits of the Composable CDP
Here’s why you should use best-in-class tooling from your existing data platform to create a Composable CDP, rather than buying an expensive all-in-one CDP.
A true single source of truth for customer data ⭐
While legacy CDPs on the market only give you a partial copy of your customer data, the composable CDP is built on top of your data warehouse to provide you with a complete view of ALL your customer data. With this 360-degree view, organizations can easily leverage data from all sources, including POS systems, data science models, and even offline data to get a comprehensive understanding of their customers.
More flexibility
CDPs force customer data to conform to a rigid structure. This might appear efficient at first, but businesses come in all shapes and sizes, meaning they require much more flexibility than what these CDPs can offer. The composable CDP is built on the data warehouse, which means it’s built on top of trusted models and transformation maintained by the data team using a tool like dbt. This flexibility allows you to represent relationships between users and entities, so your business can have complete control over how you unify customer identity.
Better data governance
Rather than an off-the-shelf CDP managing all of your customer data, the composable CDP is built on top of your data warehouse so you get to leverage all your existing data governance, security, and observability protocols for managing your customer data. This is particularly important with growing privacy legislation like GDPR and CCPA mandating the customer’s right to be forgotten. It’s never been more important to know exactly where all your customer data is going, and have control over all of it.
Future-proof by design
Composable CDPs are future-proof by design and allow you to avoid vendor lock-in. Since every element in a composable CDP is modular, you can choose the best-in-class tools that fit the requirements at that time. As the requirements of your business evolve, you can continue to invest on top of your composable CDP as opposed to implementing a new stack from scratch.
Why best-of-breed matters
Software commonly goes through cycles of “bundling” and “unbundling”, but a few things remain consistent:
🙅♀️ No one wants vendor lock-in
⏱️ Everyone wants fast time-to-value
🫰 Everyone wants a low total cost of ownership
Generally, organizations are tempted by the lure of time-to-value and cost of ownership for all-in-one solutions, which is why they compromise on vendor lock-in. Though initially you may be quoted a lower number for an all-in-one CDP, their volume-based pricing model is designed to squeeze you for what you're worth. Vendors will often heavily discount their first year for this reason (just ask any Segment customer). 🤷

Ultimately, when it comes to the CDP space (which has really only been around for the past 5 years) there is no true all-in-one solution. Organizations that buy all-in-one CDPs are forced to ask themselves which part of the stack they are willing to compromise on and make trade-offs on capabilities that are actually critical to their business today.
Companies may feel like it’s worth betting on an all-in-one solution that has strong data collection capabilities today (e.g. Rudderstack) in the hope that their data activation features might catch up, but if we’ve learned anything from CDPs it’s that the all-in-one promise has not come to fruition. 😞
The benefit of buying best-of-breed tools (as the name would suggest) is that you truly get the best-in-class for that piece of the stack. 🏆 As an added bonus, you get to future-proof your stack since you can switch modular pieces of the stack out. Data and software stacks have functioned this way for at least the last 10 years which has enabled so much of the innovation in the space (contrast this to the monolithic times of Oracle and Teradata).
The future is warehouse-native 🔮
Every company eventually needs to invest in some sort of “customer data platform.” But rather than buying an expensive all-in-one solution, why not leverage the building blocks for a composable CDP built on your existing data warehouse? That way, you can start delivering value today and avoid yet another copy of your data.
There’s no denying that when it comes to the future of the CDP, the tailwinds are heading in the direction of the data warehouse. CDP vendors like Twilio Segment and mParticle have recognized this by recently announcing their own versions of “reverse ETL connectors,” but their rushed attempts to “slap on” reverse ETL are clearly an afterthought.
With data activation and reverse ETL democratizing access, the data warehouse is best positioned to become the system of customer record that powers not just your marketing technology, but the entire business operations of the company. 🚀
💡 Learn more about how Census can help you activate the place your customer data already lives. Book a demo with one of our product specialists to see how we can help you build granular segments, and sync customer data to all your marketing and advertising tools, without any code.